







 神经网络训练时,不收敛可能是数据未归一化、输出检查遗漏、数据预处理不足等原因导致。解决办法包括数据归一化、检查输出、数据预处理、正则化、合理设置batch size、学习率调整、选择合适激活函数等。此外,网络结构不合理、样本量过少、权重初始化不当也可能导致不收敛,需要适当调整网络深度、隐藏层神经元数量以及使用抗过拟合策略。
神经网络训练时,不收敛可能是数据未归一化、输出检查遗漏、数据预处理不足等原因导致。解决办法包括数据归一化、检查输出、数据预处理、正则化、合理设置batch size、学习率调整、选择合适激活函数等。此外,网络结构不合理、样本量过少、权重初始化不当也可能导致不收敛,需要适当调整网络深度、隐藏层神经元数量以及使用抗过拟合策略。
目录
14.通过training loss和test loss分析网络当下的状态
1. 忘记对你的数据进行归一化
问题描述
在神经网络训练中,如何对你的数据进行归一化是非常重要的。这是一个不能省略的步骤,几乎不可能在不进行归一化的前提下可以训练得到一个很好的网络模型。不过正因为这个步骤非常重要,而且在深度学习社区也很有名,所以很少人会提到它,但是对于初学者则是可能会犯下的一个错误。
原因
我们需要对数据进行归一化操作的原因,主要是我们一般假设输入和输出数据都是服从均值为 0,标准差为 1 的正态分布。这种假设在深度学习理论中非常常见,从权重初始化,到激活函数,再到对训练网络的优化算法。
解决办法
常用的归一化方法主要是零均值归一化,它会将原始数据映射到均值为 0,标准差为 1 的分布上。假设原始特征的均值是μ、方差是δ,则公式如下:
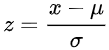
另一种常用的归一化方法是线性函数归一化(Min-Max Scaling)。它对原始数据进行线性变换,使得结果映射到[0,1]的范围,实现对原始数据的等比缩放,公式如下:
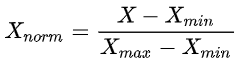
其中 X 是原始数据,Xmax、Xmin分别表示数据最大值和最小值。
未经训练的神经网络通常输出的值大致在-1到1之间。如果希望它输出一些其他范围的值(例如RGB图像,存储为字节的范围是0到255),那将会有一些问题。当开始训练时,网络将非常不稳定,因为当预期值为255时,它将产生-1或1,这个错误被用于训练神经网络的大多数优化算法认为是巨大的。这将产生巨大的梯度,你的训练误差可能会爆发。如果你的训练没有爆炸,那么训练的前几个阶段仍然是浪费,因为网络将学习的第一件事是缩放和转移输出值到大致期望的范围。如果你规范化你的数据(在这种情况下你可以简单地除以128减去1),那么这些都不是问题。
一般来说,神经网络中特征的规模也会决定它们的重要性。如果你在输出中有一个大尺度的特征,那么与其他特征相比,它会产生更大的错误。同样,输入中的大尺度特征会主导网络,导致下游更大的变化。由于这个原因,使用许多神经网络库的自动归一化并不总是足够的,这些库盲目地减去平均值,然后除以每个特征的标准差。你可能有一个输入特征一般范围在0.0和0.001之间,这个特性的范围如此之小,因为它是一个重要的特性(在这种情况下,也许你不想对它再缩放),或因为它有一些小型单位相比其他特性?
同样地,要小心那些有如此小范围的特性,它们的标准偏差接近或精确地接近于零——如果规范化它们,这些特性将产生nan的不稳定性。仔细考虑这些问题是很重要的——考虑你的每个特性真正代表了什么,并将标准化视为制作“单元”的过程。所有输入特征都相等。这是我认为在深度学习中真正需要人类参与的少数几个方面之一。
2. 忘记检查输出结果
问题描述
当你开始训练你的网络几个 epoch 后,发现误差在减小了。这表示成功训练网络了吗?很不幸这并不是,这说明你的代码中很可能还有一些问题,可能是在数据预处理、训练代码或者推理部分有问题。仅仅因为误差在减小并不意味着你的网络正在学习有用的信息。
原因
与传统编程不同,机器学习系统几乎在所有情况下都会悄无声息地失败。在传统的编程中,我们习惯于电脑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









