



 本文详细介绍了如何使用YoloV3进行目标检测,包括利用预训练权重进行图像检测,通过GPU加速,结合OpenCV显示结果,基于视频的实时检测,以及训练自定义数据集检测特定目标的完整流程。重点讲解了数据集的标记、配置文件修改和模型训练的过程。
本文详细介绍了如何使用YoloV3进行目标检测,包括利用预训练权重进行图像检测,通过GPU加速,结合OpenCV显示结果,基于视频的实时检测,以及训练自定义数据集检测特定目标的完整流程。重点讲解了数据集的标记、配置文件修改和模型训练的过程。

yoloV3是实时目标检测算法yolo的第三个版本,其本身基于darknet构建的神经网络算法.
官网:YOLO: Real-Time Object Detection
1.实例演示
#获取源码
git clone https://github.com/pjreddie/darknet
cd darknet
make
#获取预训练的参数权重
wget https://pjreddie.com/media/files/yolov3.weights
#执行
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg在darknet文件夹下的predictions.jpg即是检测后的结果,如图:

2. 利用GPU
Darknet在进行图像目标检测时,可以使用GPU进行运算加速,比单独使用CPU要快500倍以上.
前提:具有NVIDIA 显卡、显卡驱动已安装、CUDA已安装、CUDNN已安装
上述的前提的安装过程较为繁琐,请参考阿弎:ubuntu安装tensorflow gpu版本
假设上述前提已准备好,则修改darknet根目录下的Makefile文件:
GPU=1
CUDNN=1 #若安装了cudnn设置为1,也可以不设置.安装了cuda其实就可以使用GPU了#注意makefile中如下的配置 请确认是否与你安装的目录一致
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/
CFLAGS+= -DGPU
ifeq ($(OS),Darwin) #MAC
LDFLAGS+= -L/usr/local/cuda/lib -lcuda -lcudart -lcublas -lcurand
else
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
ifeq ($(OS),Darwin) #MAC
CFLAGS+= -DCUDNN -I/usr/local/cuda/include
LDFLAGS+= -L/usr/local/cuda/lib -lcudnn
else
CFLAGS+= -DCUDNN -I/usr/local/cudnn/include
LDFLAGS+= -L/usr/local/cudnn/lib64 -lcudnn
endif
endif 再次使用make重新编译
使用GPU版测试dog.jpg 耗时0.20秒
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg #默认使用第1块GPU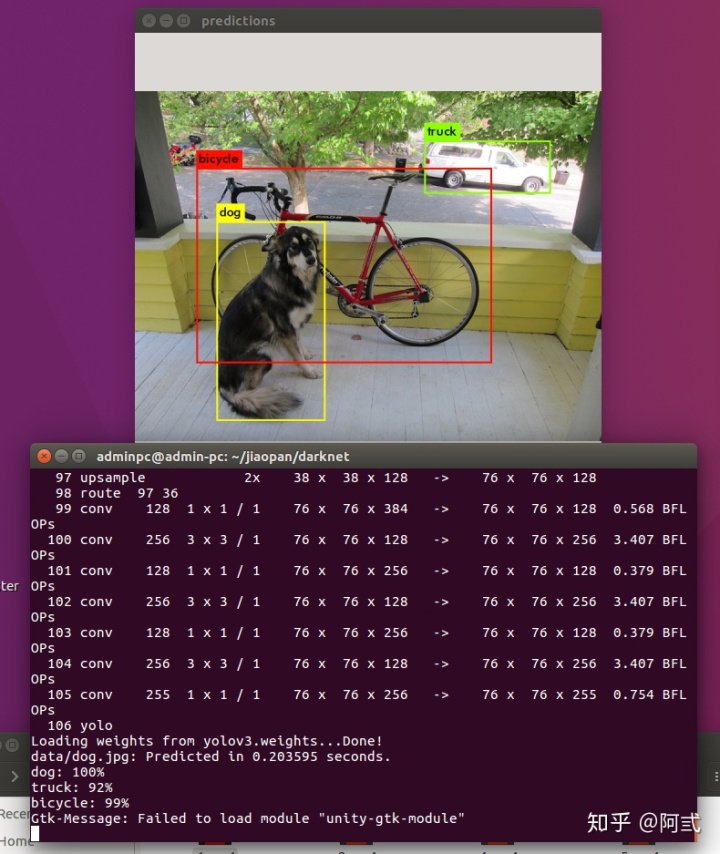
./darknet detect cfg/yolov3.cfg yolov3.weights -i 1 data/dog.jpg # -i 1:使用第2块GPU
./darknet -nogpu detect cfg/yolov3.cfg yolov3.weights data/dog.jpg #-nogpu:不使用GPU3.结合OpenCV(opencv 版本<=3.4.0)
默认下Darknet使用stb_image.h加载图像,如果支持多种图片格式可以结合OpenCV进行处理,同时OpenCV将检测结果实时直观的展示出来.
Opencv的安装请参考opencv3(1-2) linux配置opencv3开发环境
安装好OpenCV后,修改Makefile文件
OPENCV=1执行make命令再次重新编译
测试是否可用:
./darknet imtest data/eagle.jpg
#再次执行如下命令,检测结果的图片将会弹到桌面
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg4.基于视频的实时目标检测
除了检测图片外,Darknet还可以针对视频进行检测,前提:安装好CUDA和OpenCV
#通过摄像头进行视频测试 系统具备摄像头且可用
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
#通过视频文件进行测试
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>使用MP4视频测试
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights /home/adminpc/jiaopan/test.mp4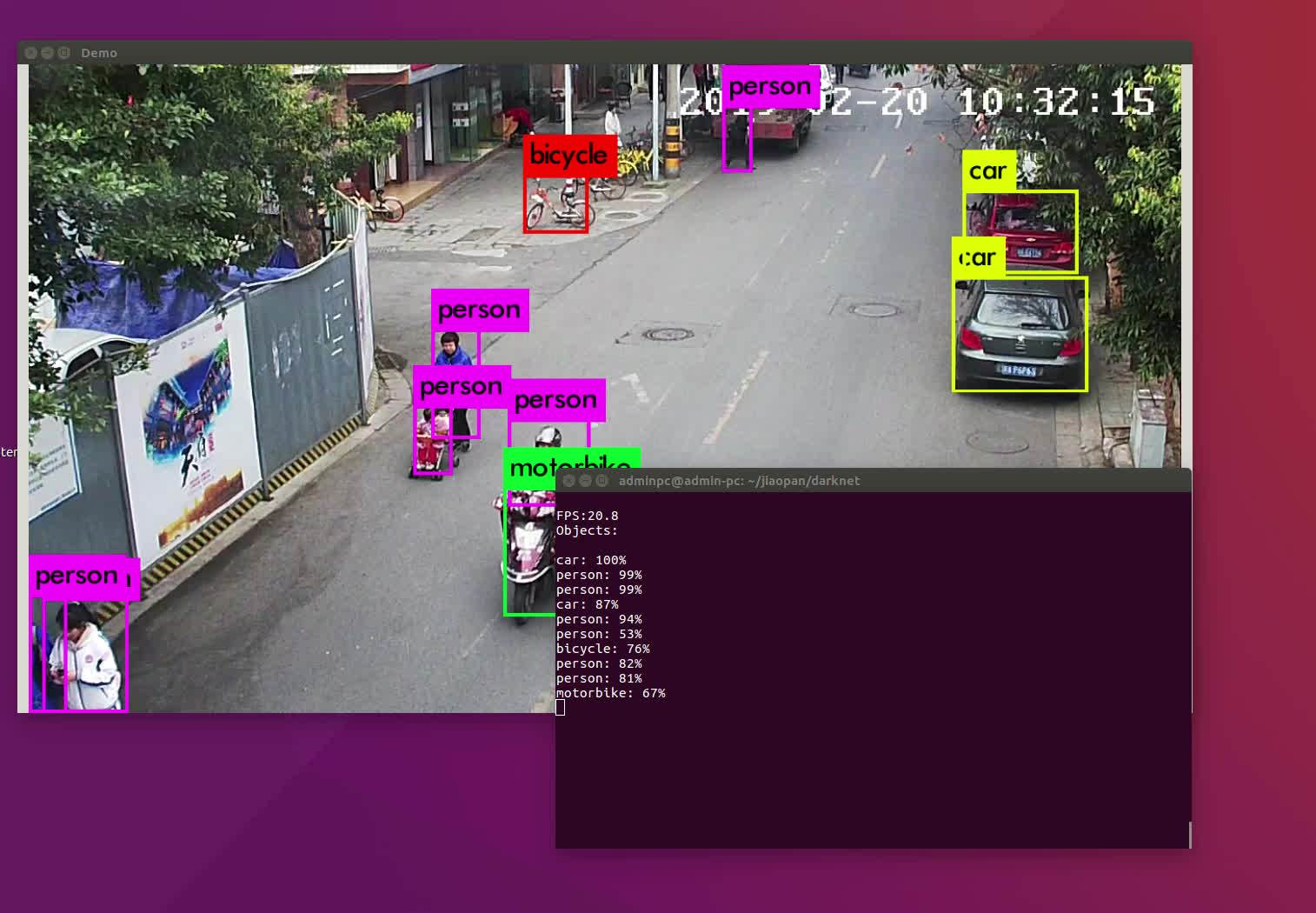
5.训练自定义数据集 检测自定义目标
训练数据集的标记
训练数据集的构造可以使用yolo_mark,地址:AlexeyAB/Yolo_mark
参考:AlexeyAB/darknet 通过上述步骤编译该版本的darknet
yolo_mark的编译安装请参考官方文档,不再赘述.
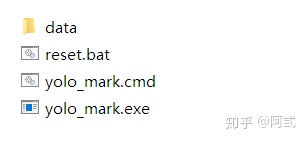
在data目录下构建如下四个文件

- img:放置需要标记的图片集合
- obj.data内容如下:
classes= 2 #检测的类别个数 如检测自行车、小汽车、公交车,则classes = 3
train = data/train.txt
valid = data/train.txt
names = data/obj.names
backup = backup/- obj.names
检测的类别名称,如检测自行车和自行车群,个数等于classes的值,且用英文命名
使用中文会乱码,需要更改darketnet源码
bike
bike_grouptrain.txt:初始为空
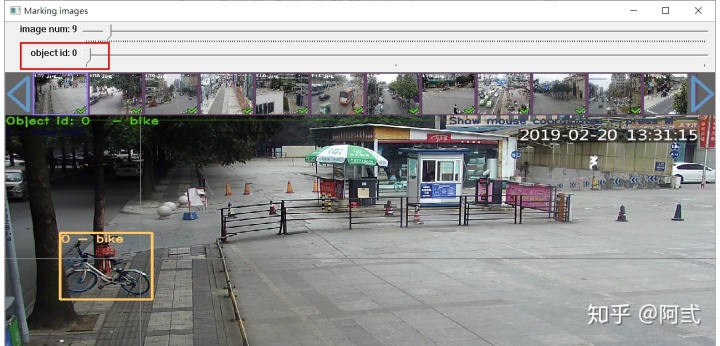
双击yolo_mark.cmd启动标记程序,启动后如图:
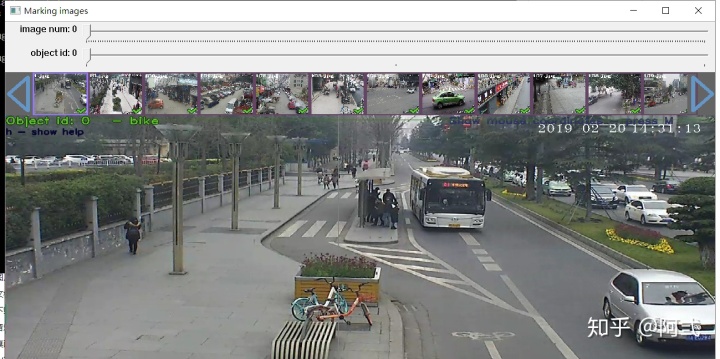
- image num 0:第几张图片
- object id 0:当前标记的类别,0对应bike 1对应bike_group 通过键盘的数字键可直接进行切换或者使用鼠标点击切换
通过鼠标绘制矩形框进行标记,标记bike时object id 指向0,标记bike_group时object id 指向1
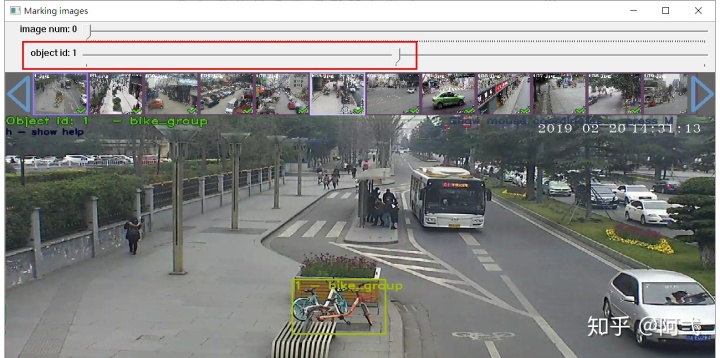
切换上一张图片和下一张图片可通过键盘方向键进行切换,同时空格键位切换到下一张图片
若标记错误,可将鼠标指针移到方框内,并按键盘R键即可删除错误的标记框.
按键盘H键可以查看更多的操作说明.
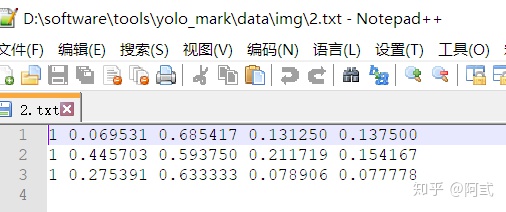
标记完图片以后,在img目录下会生成图片对应的txt,txt内容为类别值以及标记方框在图片中的坐标(x,y,width,height),且值为归一化后的值.

同时,图片的所有相对路径将会自动加载到train.txt文件中
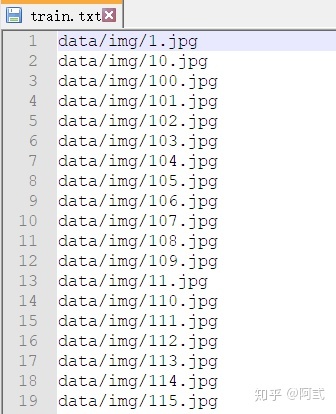
注意,train.txt文件需要通过notepad++转为unix格式
至此,训练数据集便构造完成.
模型训练
- 将img文件夹、obj.data、obj.names、train.txt复制到darknet的data目录下
2.创建model目录,复制darknet/cfg目录下的yolov3.cfg到darknet/model目录,并重新命名为yolo-obj.cfg
cfg文件定义yolo神经网络的结构、学习速率、迭代次数等参数
3.打开yolo-obj.cfg文件
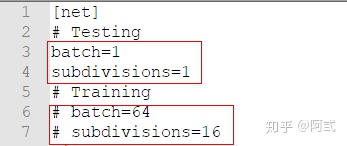
- 注释3-4行,取消6-7行的注释
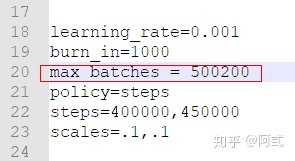
- 更改迭代次数,2000次即可,依据GPU性能,本文使用的是Titan V .若显卡性能较差,迭代次数过多,训练时间将会很长,若迭代次数太少,模型的准确率会很低.
- 本文检测自行车和自行车群两个类别,修改classes = 2 ,共三处
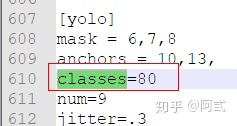
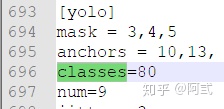
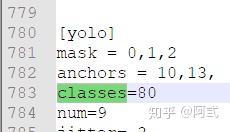
- 更改 [
filters=255] 为 filters=(classes + 5)x3
原文件classes = 80,因此filters = (80+5) x 3 = 255
本文classes = 2,因此filters = (2+5) x 3 = 21
注意:只修改 [filters=255]的地方,其他的filters不要修改,共三处


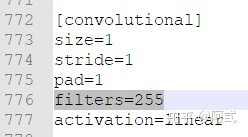
所以针对两个类别的检测 修改的值为:
filters=21
classes=24.下载预训练模型参数 :http://pjreddie.com/media/files/darknet53.conv.74,并将其复制到darknet/model目录下
5.执行命令训练
./darknet detector train data/obj.data model/yolo-obj.cfg model/darknet53.conv.74 训练过程,如图:
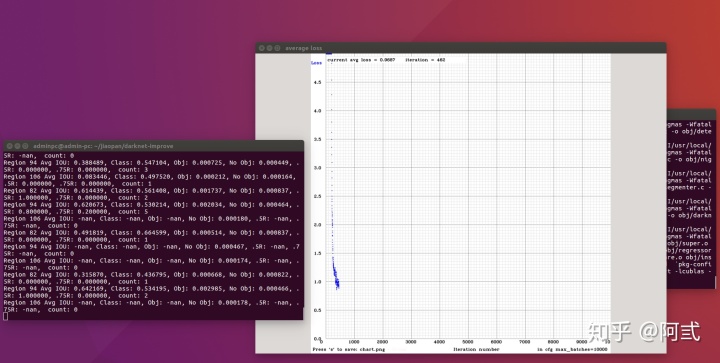
每训练100或1000次,在darknet/backup目录下会自动生成模型参数文件.图表为训练时的误差值趋势图.训练时的误差足够小即可手动停止训练或等待训练完成.
训练完成以后,在darknet/backup目录会生成yolo-obj_last.weights文件.这就是我们训练完成的模型参数文件,yolo-obj_1000.weights表示迭代1000次时的模型参数
6.测试
#使用训练完成后的模型参数测试
./darknet detector test data/obj.data model/yolo-obj.cfg backup/yolo-obj_last.weights输入图片地址后,结果如图
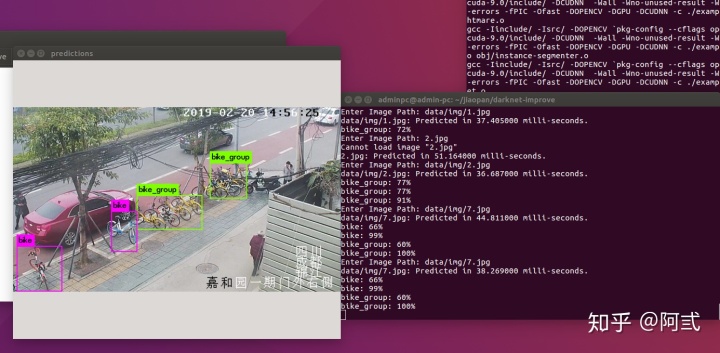


















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









