





一、简介
数据集包含4个文件,
train-images-idx3-ubyte:训练集图像
train-labels-idx1-ubyte:训练集标签
t10k-images-idx3-ubyte:测试集图像
t10k-labels-idx1-ubyte:测试集标签
二、数据存储方式
此处来源于MNIST官网,略看即可,没有后面的代码分析,这部分较难理解,可以直接跳。
数据以非常简单的文件格式存储,旨在存储矢量和多维矩阵。
文件中的所有整数都以大多数非Intel处理器使用的MSB优先(高端)格式存储。英特尔处理器和其他低端计算机的用户必须翻转标头的字节。
训练设置标签文件(train-labels-idx1-ubyte):
[偏移] [类型] [值] [描述]
0000 32位整数0x00000801(2049)幻数(MSB优先)
0004 32位整数60000项数
0008无符号字节?标签
0009无符号字节 标签
........
xxxx无符号字节?? 标签标签值为0到9。
训练集图像文件(train-images-idx3-ubyte):
[偏移] [类型] [值] [描述]
0000 32位整数0x00000803(2051)幻数
0004 32位整数60000图片数
0008 32位整数28行数
0012 32位整数28列数
0016无符号字节? ?像素
0017无符号字节 像素
........
xxxx无符号字节?? 像素点像素按行组织。像素值为0到255。0表示背景(白色),255表示前景(黑色)。
测试集标签文件(t10k-labels-idx1-ubyte):
[偏移] [类型] [值] [描述]
0000 32位整数0x00000801(2049)幻数(MSB优先)
0004 32位整数10000项数
0008无符号字节?标签
0009无符号字节 标签
........
xxxx无符号字节?? 标签标签值为0到9。
测试集图像文件(t10k-images-idx3-ubyte):
[偏移] [类型] [值] [描述]
0000 32位整数0x00000803(2051)幻数
0004 32位整数10000图像数
0008 32位整数28行数
0012 32位整数28列数
0016无符号字节? ?像素
0017无符号字节 像素`
........
xxxx无符号字节?? 像素点像素按行组织。像素值为0到255。0表示背景(白色),255表示前景(黑色)。
三、代码分析
import load_mnist 函数返回两个数组, 第一个是一个 n x m 维的 NumPy array(images), 这里的 n 是样本数(行数), m 是特征数(列数). 在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示. 在这里, 我们将 28 x 28 的像素展开为一个一维的行向量, 这些行向量就是图片数组里的行(每行 784 个值, 或者说每行就是代表了一张图片).
load_mnist 函数返回的第二个数组(labels) 包含了相应的目标变量, 也就是手写数字的类标签(整数 0-9)
此处插入介绍一下大小端的问题
先放一张我学C语言的时候关于地址的图
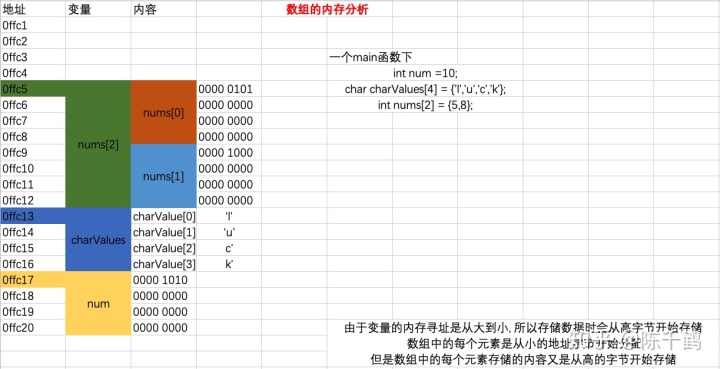
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
回来继续。
显然这种读取方式有点奇怪,而且还出现了奇怪的符号:
magic通过使用上面两行代码, 我们首先读入 magic number, 它是一个文件协议的描述, 也是在我们调用 fromfile 方法将字节读入 NumPy array 之前在文件缓冲中的 item 数(n). 作为参数值传入 struct.unpack 的 >II 有两个部分:
>: 这是指大端(用来定义字节是如何存储的)
I: 这是指一个无符号整数.
当然这只是读入数据的方法,我们还可以让它可视化。
import 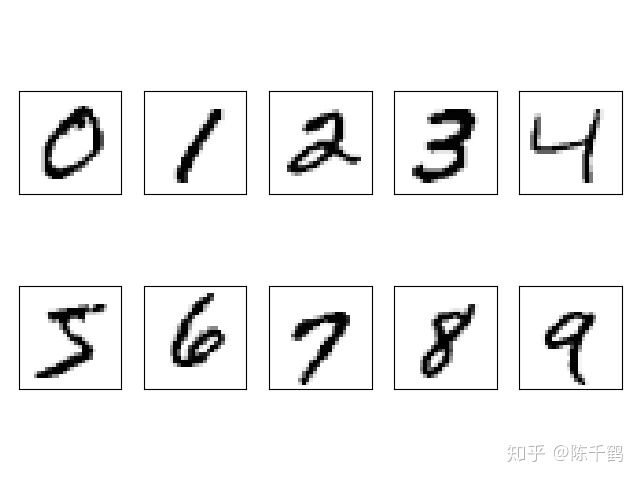
fig
四、附上PaddlePaddle对该数据集的读取代码
欢迎使用PaddlePaddle框架进行开发学习
该代码可以在本机安装PaddlePaddle后,在Padddle的dataset文件夹中找到
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









