



 本文围绕Kafka展开,探讨了能否脱离Zookeeper、数据保留策略、数据清除规则等问题。介绍了Kafka创建topic的命令及后台逻辑,还分析了导致Kafka运行变慢的因素,以及使用Kafka集群的注意事项,如数量不宜超7个且最好为单数。
本文围绕Kafka展开,探讨了能否脱离Zookeeper、数据保留策略、数据清除规则等问题。介绍了Kafka创建topic的命令及后台逻辑,还分析了导致Kafka运行变慢的因素,以及使用Kafka集群的注意事项,如数量不宜超7个且最好为单数。

63. kafka 可以脱离 zookeeper 单独使用吗?为什么?
kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafka 的节点服务器。
64. kafka 有几种数据保留的策略?
- 探究的是kafka的数据生产出来之后究竟落到了哪一个分区里面去了
- 第一种分区策略:给定了分区号,直接将数据发送到指定的分区里面去
- 第二种分区策略:没有给定分区号,给定数据的key值,通过key取上hashCode进行分区
- 第三种分区策略:既没有给定分区号,也没有给定key值,直接轮循进行分区
- 第四种分区策略:自定义分区
/// / producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), Integer.toString(i)));
65. kafka 同时设置了 7天和 10G 清除数据,到第五天的时候消息达到了 10G,这个时候 kafka 将如何处理?
这个时候 kafka 会执行数据清除工作,时间和大小不论那个满足条件,都会清空数据。
66. 怎么设置kafka topic数据存储时间
Kafka创建topic命令很简单,一条命令足矣:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test 。
这条命令会创建一个名为test的topic,有3个分区,每个分区需分配3个副本。
topic创建主要分为两个部分:命令行部分+后台(controller)逻辑部分。
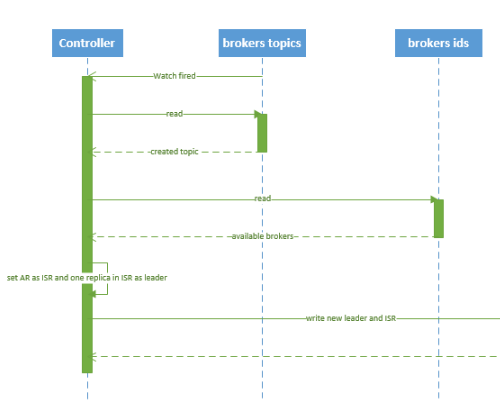
后台逻辑会监听zookeeper下对应的目录节点,一旦发起topic创建命令,该命令会创建新的数据节点从而触发后台的创建逻辑。
确定分区副本的分配方案(就是每个分区的副本都分配到哪些broker上);创建zookeeper节点,把这个方案写入/brokers/topics/<topic>节点下。
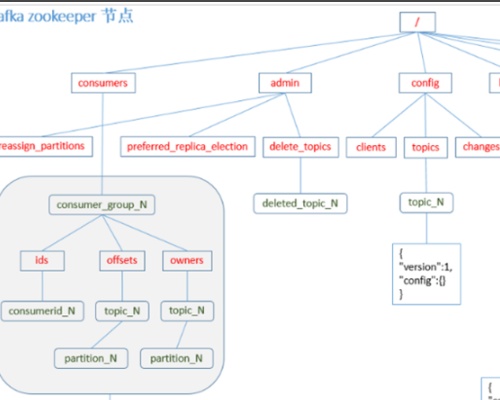
Kafka controller部分主要做下面这些事情:创建分区;创建副本;为每个分区选举leader、ISR;更新各种缓存。
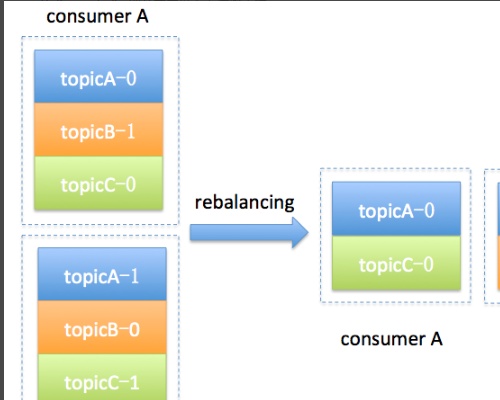
67. 什么情况会导致 kafka 运行变慢?
- cpu 性能瓶颈
- 磁盘读写瓶颈
- 网络瓶颈
68. 使用 kafka 集群需要注意什么?
- 集群的数量不是越多越好,最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,整个群组的吞吐量就越低。
- 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。

















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









