






一、介绍
从 MTCNN(Multi-task Cascaded Convolutional Networks)的名字当中便可知,MTCNN 是多任务网络,且其网络结构为级联结构。论文中摘要中有句话特别简洁的介绍了其网络结构及其作用:

可以看出MTCNN有三个(three stages)网络组成,或者说训练过程具有三步(“三步走”大法~),其用途(目的)则是人脸检测和人脸关键点定位,并且是一个由粗到细(还好不是人体某个 organ~)定位的过程,可以理解为使用显微镜查找细胞内细胞核的过程,先粗调找到目标,再微调以细致观察。
论文创新点:(1)通过将人脸检测和人脸关键点对齐相结合以提升检测指标;(2)对在线难样本挖掘(Online Hard Sample Mining,OHSM)算法进行改进
二、网络结构
2.1 pipline
论文中给出了一个pipiline贴图,如下图所示:
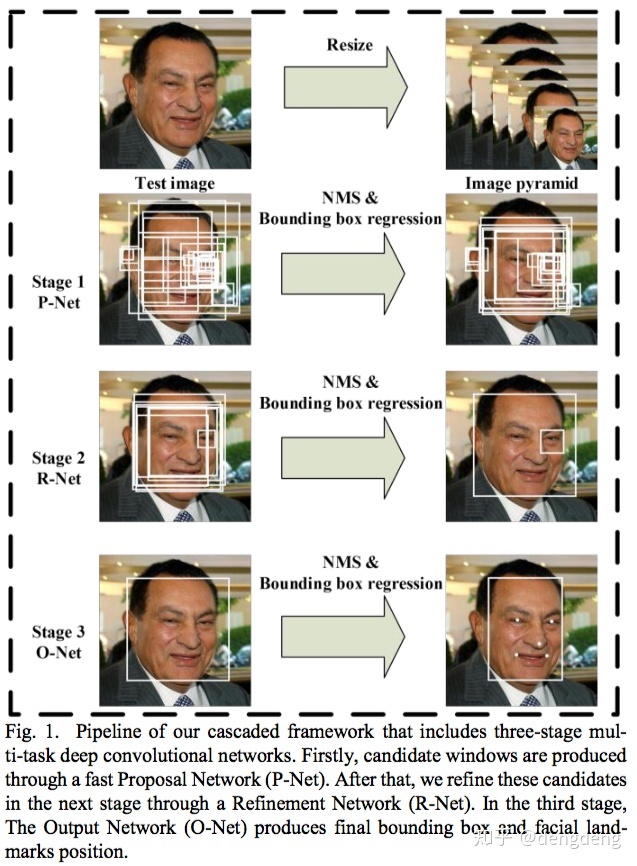
看完Pipeline之后便能对MTCNN训练/测试过程有了一个初步的了解,其大致过程如下:
1)Image Pypamid : 制作图像金字塔(将尺寸从大到小的图像堆叠在一起类似金字塔形状,故名图像金字塔),对输入图像resize 到不同尺寸,为输入网络作准备。
2)Stage 1 : 将金字塔图像输入P-Net(Proposal Network),获取含人脸的Proposal boundding boxes,并通过非极大值抑制(NMS)算法(后面对NMS算法的过程进行了补充)去除冗余框,这样便初步得到一些人脸检测候选框。
3)Stage 2 : 将P-Net输出得到的人脸图像输入R-Net(Refinement Network),对人脸检测框坐标进行进一步的细化,通过NMS算法去除冗余框,此时的到的人脸检测框更加精准且冗余框更少。
4)Stage 3 : 将R-Net输出得到的人脸图像输入O-Net(Output Network),一方面对人脸检测框坐标进行进一步的细化,另一方面输出人脸5个关键点(左眼、右眼、鼻子、左嘴角、右嘴角)坐标。
疑问:为什么要做图像金字塔?
由于原始图像中,存在大小不同的脸,为了在统一尺度下检测人脸,进入网络训练之前,就要将原始图片缩放至不同尺度。以增强网络对不同尺寸大小人脸的鲁棒性。
代码:
for 2.2 网络结构:
MTCNN 网络由P-Net 、R-Net、O-Net 串联组成,下图为三个网络的结构:
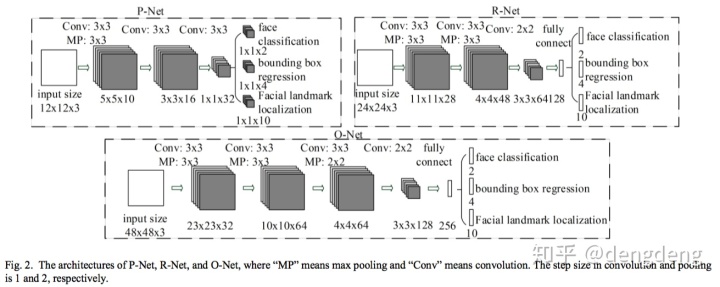
1、P-Net
P-Net包含三个卷积层,每个卷积核的大小均为3✖️3,注意到P-Net 没有全连接层。
(1)作用:判断是否含人脸,并给出人脸框和关键点的位置,为O-Net提供人脸候选框。
(2)输入:尺寸大小为 12✖️12的三通道图像
(3)输出:包含三部分:a.是否人脸的概率1✖️1✖️2向量(之所以有两个值(0和1的概率)是因为为了方便计算交叉熵);b.人脸检测框坐标(左上点和右下点)1✖️1✖️4向量;c.人脸关键点(5个关键点)坐标1✖️1✖️10向量。
代码:
class PNet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 10, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='PReLU1')
.max_pool(2, 2, 2, 2, name='pool1')
.conv(3, 3, 16, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='PReLU2')
.conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='PReLU3')
.conv(1, 1, 2, 1, 1, relu=False, name='conv4-1')
.softmax(3,name='prob1'))
(self.feed('PReLU3') #pylint: disable=no-value-for-parameter
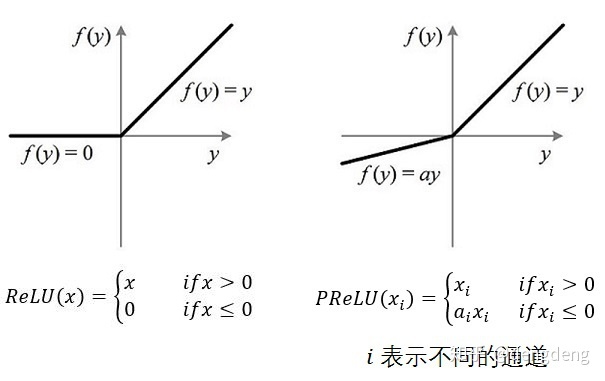
.conv(1, 1, 4, 1, 1, relu=False, name='conv4-2'))代码中,激活函数为PReLU(Parametric Rectified Linear Unit),其为ReLU的改进版,即带了参数的ReLU,该参数a会随着数据变化,而当a为定值时,则变身为Leaky ReLU。
2、R-Net
P-Net网络结构与P-Net的网络结构类似,也包含三个卷积层,前两个卷积核的大小均为3✖️3,第三个卷积核的大小为2✖️2,且其相比于P-Net 多了一个全连接层。
(1)作用:对P-Net 输出可能为人脸候选框图像进一步进行判定,同时细化人脸检测目标框精度。
(2)输入:尺寸大小为 24✖️24的三通道图像
(3)输出:包含三部分:a.是否人脸的概率的1✖️1✖️2向量;b.人脸检测框坐标(左上点和右下点)1✖️1✖️4向量;c.人脸关键点坐标1✖️1✖️10向量。
代码:
class RNet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 28, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='prelu1')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(3, 3, 48, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='prelu2')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
.conv(2, 2, 64, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='prelu3')
.fc(128, relu=False, name='conv4')
.prelu(name='prelu4')
.fc(2, relu=False, name='conv5-1')
.softmax(1,name='prob1'))
(self.feed('prelu4') #pylint: disable=no-value-for-parameter
.fc(4, relu=False, name='conv5-2'))3、O-Net
O-Net网络结构相比R-Net的网络结构,多了一个3✖️3卷积层,
(1)作用:对R-Net 输出可能为人脸的图像进一步进行判定,同时细化人脸检测目标框精度。
(2)输入:尺寸大小为 48✖️48的三通道图像
(3)输出:包含三部分:a.是否人脸的概率的1✖️1✖️2向量;b.人脸检测框坐标(左上点和右下点)1✖️1✖️4向量;c.人脸关键点坐标1✖️1✖️10向量。
代码:
class ONet(Network):
def setup(self):
(self.feed('data') #pylint: disable=no-value-for-parameter, no-member
.conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv1')
.prelu(name='prelu1')
.max_pool(3, 3, 2, 2, name='pool1')
.conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv2')
.prelu(name='prelu2')
.max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
.conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv3')
.prelu(name='prelu3')
.max_pool(2, 2, 2, 2, name='pool3')
.conv(2, 2, 128, 1, 1, padding='VALID', relu=False, name='conv4')
.prelu(name='prelu4')
.fc(256, relu=False, name='conv5')
.prelu(name='prelu5')
.fc(2, relu=False, name='conv6-1')
.softmax(1, name='prob1'))
(self.feed('prelu5') #pylint: disable=no-value-for-parameter
.fc(4, relu=False, name='conv6-2'))
(self.feed('prelu5') #pylint: disable=no-value-for-parameter
.fc(10, relu=False, name='conv6-3'))估计大家也发现了一个现象,P-Net 、R-Net、O-Net ,图像的输入越来越大,每一层卷积核的个数越来越多,网络的深度也是越来越深。所以他们的运行速度也是越来越慢,然而其准确度却是越来越高。
疑问:那既然O-Net的准确度最高,为什么不直接过O-Net呢?或者是比O-Net更深的网络呢?
这是因为,假如直接过O-Net网络,运行速度会非常的慢,实际上P-Net和R-Net 这两步对含人脸检测Proposal bounding box 做了一个过滤,使得最后过耗时更大的O-Net网络 的bounding box 比较少,从而减少了整体时间。
三、网络训练
3.1 训练样本选择
- a. 负样本数据:IoU 小于0.3
- b. 正样本数据:IoU 大于0.65
- c. 部分人脸数据:IoU 大于0.4 小于0.65
- d. 关键点样本数据:样本标注了5个关键点的坐标
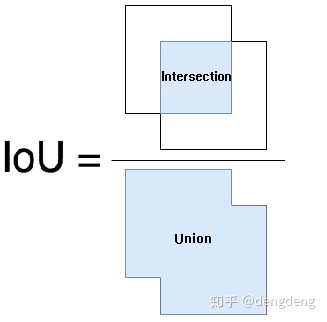
IoU (Intersection over Union)即bounding box 和 groud truth 的交并比,计算方法如下图所示:
训练时,负样本和正样本用于是否人脸分类的训练;正样本和部分样本用于检测框回归训练;关键点样本则用于人脸关键点的训练。
3.2 损失函数设计
由于在MTCNN 中,每个网络都有三个输出,因此会对应有三个损失函数:
1)对于输出a:是否人脸分类,由于是分类问题,其loss 函数使用常见的交叉熵损失:
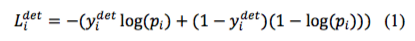
2)对于输出b:人脸检测框定位,由于是回归问题,所以使用L2 损失函数:
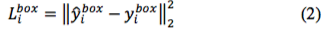
3)对于输出c:人脸关键点定位,由于也是回归问题,所以也使用L2 损失函数:
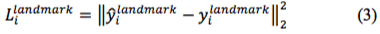
最终将三个损失函数进行加权累加,便得到总损失函数。由上述样本选择可知,当负样本和正样本训练时,由于仅用于分类,所以其仅有分类损失,而不存在人脸检测框和人脸关键点定位损失。即并不是所有的样本都同时存在上述三种损失。通过控制不同权重,使得三个网络的关注点不一样:

其中,
- a. 当样本为负样本数据时,
;
- b. 当样本为正样本数据时,
;
- c. 当样本为部分人脸数据时,
;
- d. 当样本为关键点样本数据时,
3.3 难样本挖掘
不同于传统的难样本挖掘算法,论文中提出使用在线难样本挖掘。首先将前向传递得到的loss值降序排序,然后选择前70%大的样本作为难样本,并在反向传播的过程中只计算难样本的梯度,即将对于训练网络没有增强作用的简单样本忽略不计。
补充:非极大值抑制(NMS)
论文:《Efficient Non-Maximum Suppression》
NMS 主要是用于对多个候选框去除重合率大的冗余候选框,从而保留区域内最优候选框,其过程是一个迭代遍历的过程。

算法步骤如下图所示:
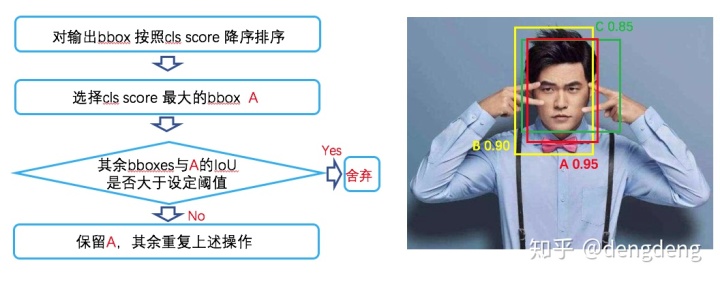
代码:
def nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep参考文献
论文链接:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
代码:
Daniel00008/MyAIgithub.com
以上就是我对MTCNN算法的理解,欢迎大家一起讨论Y~
还以为写完能有时间看《妇联4》,结果已经深夜了,摔~
只好拿海报做个人脸检测Test作为封面安慰下自己~

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









