






 本文详细分析了Android系统中消息机制的关键组成部分——Looper和MessageQueue的创建过程,以及它们如何协同工作来实现消息循环。在Android7.1.1版本中,Looper通过prepareMainLooper()初始化,MessageQueue由nativeInit()在Native层创建,使用epoll机制实现线程的阻塞与唤醒。消息循环通过loop()函数不断从MessageQueue中获取并处理Message,同时处理IdleHandler。文章深入探讨了nativePollOnce()在epoll_wait()调用中的角色,揭示了消息处理与线程阻塞的实现原理。
本文详细分析了Android系统中消息机制的关键组成部分——Looper和MessageQueue的创建过程,以及它们如何协同工作来实现消息循环。在Android7.1.1版本中,Looper通过prepareMainLooper()初始化,MessageQueue由nativeInit()在Native层创建,使用epoll机制实现线程的阻塞与唤醒。消息循环通过loop()函数不断从MessageQueue中获取并处理Message,同时处理IdleHandler。文章深入探讨了nativePollOnce()在epoll_wait()调用中的角色,揭示了消息处理与线程阻塞的实现原理。
写在前面
本文基于Android 7.1.1 (API 25)的源码分析编写
与之前的触摸事件分发机制分析的文章一样,Android系统机制的分析中关键的一环就是事件消息的处理。之前也说过,Android本质上是一个事件驱动的模型,通过各式各样不断产生事件消息的来推动UI、数据的更新与对我们交互的反馈,没有事件消息的产生,就不会有直观的界面的变化,也就不会有应用丰富的功能。
所以Android的消息机制与其他过程的关系是极其紧密的,例如启动Activity的过程就涉及到ActivityManagerService与应用主进程的通信,产生的通知消息通过Binder机制送入应用主进程的消息队列,再由主进程的消息循环来读取这一消息来进行处理。之前触摸事件分发中也是利用了应用主进程的消息队列来读取我们的触摸事件再进行后续的分发处理。可以说消息队列在各种通信过程中无处不在。
消息队列的存在为异步处理提供了一个非常好的基础,有了消息队列之后,我们就可以在新的线程中处理计算、IO密集、阻塞的任务而不会影响UI的更新,在处理过程中可以通过向消息队列中放入消息来进行UI的更新操作,而发送消息的行为也避免了工作线程为了等待返回而造成的阻塞。
可以说,想要了解其他基于事件的过程,对主线程消息机制的了解是必不可少的基础,在触摸事件分发机制分析的文章中我对消息机制还不是很了解,所以后来发现分析中有很多描述不妥的地方,所以在对消息机制的系统学习之后我又修改完善了这部分的内容。
引入
Android Studio的3.0版本中引入了一个强大的性能分析工具:Android Profiler,对于它的详细介绍可以看官方的文档。
我们对一个简单的HelloWorld应用进行方法分析:
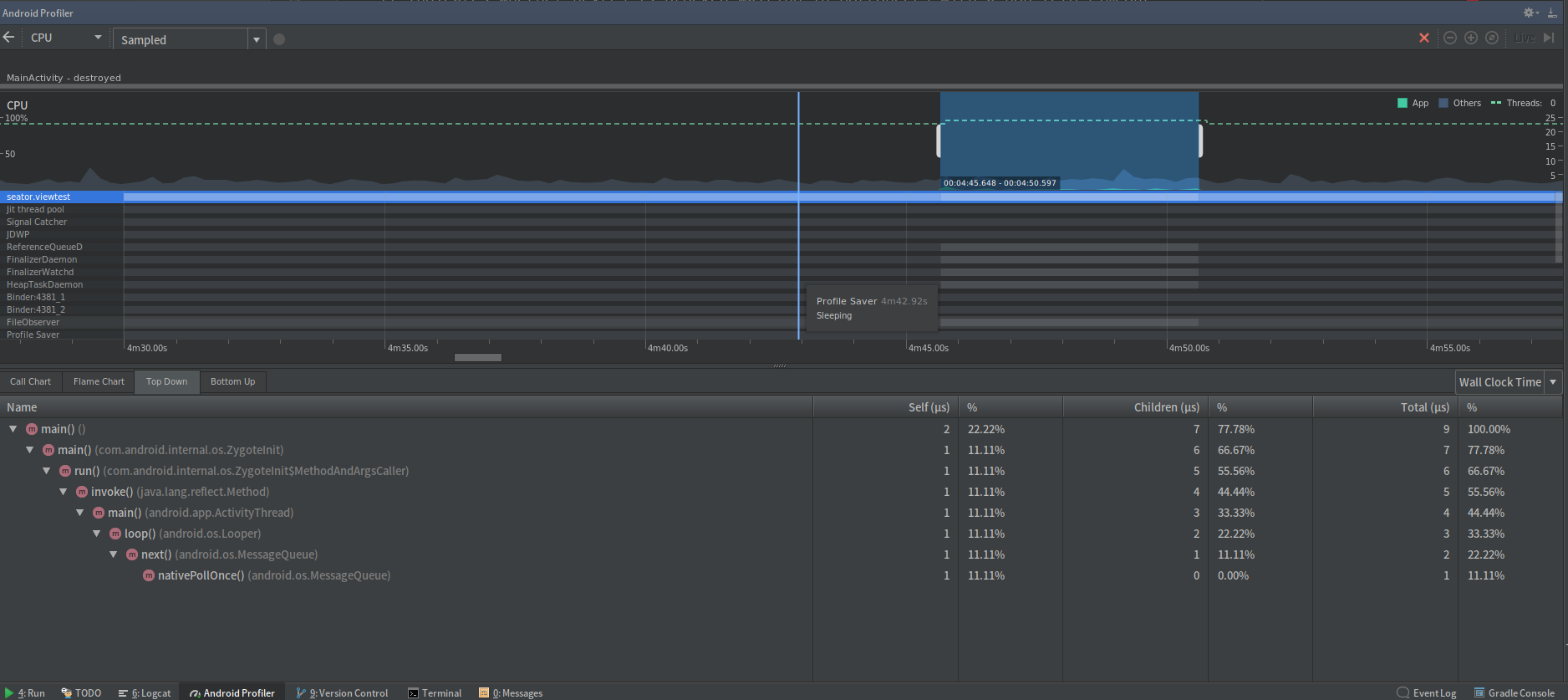
可以看到,对于这样一个没有任务需要处理的程序,这段时间中它一直执行的是nativePollOnce()方法,对于这个,stackoverflow上就有人提了一个问题。这个方法其实就是消息队列在队列中没有消息时处于等待状态执行的一个Native方法。
我们的分析就从消息队列(MessageQueue)与负责执行循环过程的Looper对象的创建与开始运行开始。
Looper与MessageQueue的创建
当一个Activity被创建时,ActivityThread的main()方法会被执行(关于Activity创建过程的内容,请参阅启动分析相关的文章):
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args){
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");
...
Looper.prepareMainLooper();
...
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
Looper的创建
第5行中,调用Looper的prepareMainLooper()方法来创建Looper对象:
1
2
3
4
5
6
7
8
9public static void prepareMainLooper(){
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
1
2
3
4
5
6private static void prepare(boolean quitAllowed){
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
这里的sThreadLocal对象的类型是ThreadLocal是一个存放在TLS(Thread-local storage)中的对象容器,储存在其中的对象的特点是每个线程中只有一个,并且个线程中储存的该对象不相同。
我们在这里新建了一个Looper对象并放入了TLS中:
1
2
3
4private Looper(boolean quitAllowed){
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
mThread保存了当前运行Looper的进程信息。
而mQueue就是与Looper对应的MessageQueue。
MessageQueue的创建1
2
3
4MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}
构造函数十分简单,除了初始化quitAllowed标记之外,就是对mPtr的初始化了。
那么mPtr是什么呢?可以推测出的是,真正的MessageQueue的创建一定在nativeInit这个Native调用中,也就是说,我们的MessageQueue实际上存在于Native层。
android_os_MessageQueue.cpp:
1
2
3
4
5
6
7
8
9
10static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz){
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
if (!nativeMessageQueue) {
jniThrowRuntimeException(env, "Unable to allocate native queue");
return 0;
}
nativeMessageQueue->incStrong(env);
return reinterpret_cast(nativeMessageQueue);
}
在Native层创建了一个NativeMessageQueue对象:
1
2
3
4
5
6
7
8NativeMessageQueue::NativeMessageQueue() :
mPollEnv(NULL), mPollObj(NULL), mExceptionObj(NULL) {
mLooper = Looper::getForThread();
if (mLooper == NULL) {
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}
这里做的事情可以和Java层进行对应:在TLS中创建了一个Looper对象,但这个Looper对象和Java层并不是同一个,并且他们的功能也不相同:Java层的Looper是为了处理的消息队列中的消息,Native中的Looper是为了处理注册的自定义Fd引起的Request 消息,这些消息一般来自于系统底层如触摸事件等(这个部分另开文章讲,这篇文章只关注一般的事件分发)。
我们来看看这个与NativeMessageQueue对应的Native Looper的构造:
Native Looper 创建与 Epoll的初始化1
2
3
4
5
6
7
8
9
10
11Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mPolling(false), mEpollFd(-1), mEpollRebuildRequired(false),
mNextRequestSeq(0), mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
mWakeEventFd = eventfd(0, EFD_NONBLOCK | EFD_CLOEXEC);
LOG_ALWAYS_FATAL_IF(mWakeEventFd < 0, "Could not make wake event fd: %s",
strerror(errno));
AutoMutex _l(mLock);
rebuildEpollLocked();
}
这里就要涉及一些Linux中系统调用中eventfd()函数与多路I/O复用函数epoll()的相关知识了,这部分也是消息机制的底层核心。
上面的代码中第5行中使用eventFd()系统调用获取了一个mWakeEventFd作为后续epoll()用于唤醒的File Descriper(文件描述符)。这里是较之前版本有所不同的地方,网上找到的大部分分析文章中的这个地方还是使用的之前使用的管道机制,也就是通过pipe()系统调用来创建一对Fd,再利用这对Fd来进行监听唤醒操作。相比于管道,Linux在内核版本2.6.22引入的eventFd在解决这种简单的监听操作中的开销比较小,并且更加轻量。
我们现在有了一个eventFd对象的Fd,下面我们进入第10行的rebuildEpollLocked()调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25void Looper::rebuildEpollLocked(){
...
mEpollFd = epoll_create(EPOLL_SIZE_HINT);
LOG_ALWAYS_FATAL_IF(mEpollFd < 0, "Could not create epoll instance: %s", strerror(errno));
struct epoll_event eventItem;
memset(& eventItem, 0, sizeof(epoll_event)); // zero out unused members of data field union
eventItem.events = EPOLLIN;
eventItem.data.fd = mWakeEventFd;
int result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);
LOG_ALWAYS_FATAL_IF(result != 0, "Could not add wake event fd to epoll instance: %s",
strerror(errno));
for (size_t i = 0; i < mRequests.size(); i++) {
const Request& request = mRequests.valueAt(i);
struct epoll_event eventItem;
request.initEventItem(&eventItem);
int epollResult = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, request.fd, & eventItem);
if (epollResult < 0) {
ALOGE("Error adding epoll events for fd %d while rebuilding epoll set: %s",
request.fd, strerror(errno));
}
}
}
第3行中,进行了系统调用epoll_create()初始化了一个epoll实例。之后的6-9行创建了epoll注册需要使用的eventItem并设置了events属性与fd域。
在第10行,进行了系统调用epoll_ctl()来将之前创建的mWakeEventFd与eventItem注册到epoll。那么这些步骤的目的是什么呢?
简单地说,epoll这个系统提供的组件允许我们对多个文件描述符(fd)进行监听,注册监听的fd后,可以调用epoll_wait()函数,当fd所指向的对象的数据可用时,epoll_wait()函数就会返回,同时以events的形式返回发生改变的fd对应的eventItem。
借助这个功能,我们就可以实现在没有事件的时候让线程阻塞,当新的事件来临的时候让线程解除阻塞并唤醒。
到这里你可能会想,这样的功能使用一个标志量,不断地查询这个标志量,当标志量发生变化的时候唤醒不也可以实现相同的功能吗?为什么要使用这么复杂的机制呢?这是因为Looper同时为我们提供了addFd()函数让我们可以设置自定义的fd与对应的event,然后在Native Looper中对自定义的fd发生改变的事件进行处理(上面代码中后面的部分就是在处理这部分注册)。之前文章讲过的触摸事件分发就是这样做的。(再次说明这一剖分的内容另外一篇文章讲,本篇只涉及一般的消息处理机制)
现在,注册epoll的过程已经完成,Native Looper的初始化也到此结束。
现在我们回到nativeInit调用,它的返回值赋给了Java层MessageQueue的mPtr域:
1
2
3
4
5
6
7
8
9
10static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz){
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
if (!nativeMessageQueue) {
jniThrowRuntimeException(env, "Unable to allocate native queue");
return 0;
}
nativeMessageQueue->incStrong(env);
return reinterpret_cast(nativeMessageQueue);
}
第9行就将创建的NativeMessageQueue对象的地址转换为一个Java long类型返回,之后调用Native方法的时候就会传入这个参数来找到这个MessageQueue。
用一张图来梳理这个过程:
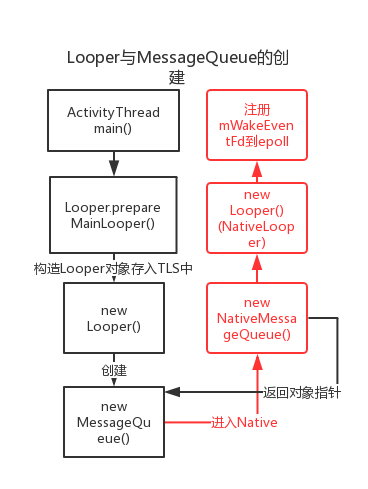
消息循环
loop()
初始化过程结束后,我们回到ActivityThread的main()函数:
1Looper.loop();
调用了Looper的loop()函数开始消息循环。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public static void loop(){
final Looper me = myLooper();
...
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
...
try {
msg.target.dispatchMessage(msg);
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
...
msg.recycleUnchecked();
}
}
省略掉一些log的代码之后,我们看到第7行开始了一个无限循环,循环的第一步就是从MessageQueue里面获取一条Message,后面有一个注释告诉我们这个调用可能会阻塞。我们先不管这个调用具体情况,假设我们从这个调用中返回,我们先看后面的处理过程。
首先检查获取到的msg是否为null,如果为null,那么将会直接退出loop()函数,对于Activity的主线程来说,这个情况只会发生在应用退出的时候。
下面就直接调用了Message的target的dispatchMessage()函数,在使用Handler来发送消息的时候,这个target指的就是Handler本身,后面会看到这个过程。
MessageQueue next()
这个函数过程比较长, 我们分开来分析。
1
2
3
4
5
6
7
8
9
10
11Message next(){
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
...
nativePollOnce(ptr, nextPollTimeoutMillis);
第一部分是变量的初始化,如果MessageQueue的mPtr为0的话,说明NativeMessageQueue没有正确初始化,返回null结束消息循环。
下面定义了两个变量,第一个pendingIdleHandlerCount初始化为-1,它表示的是将要执行的空闲Handler数量,之后会用到。
第二个nextPollTimeoutMillis就是距下一条消息被处理需要等待的时间。
下面又进入了一个无限循环,注意第11行,我们看到了熟悉的调用,它是引入中讲的在没有事件处理的时候不断执行的函数。我们可以猜测,等待的过程就是发生在这个函数中的。
我们同样先看下面的处理,现在只要知道这个函数会造成阻塞,当有新的Message或者达到超时时间时才会返回,这点非常重要。
下面的过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39synchronized (this) {
final long now = SystemClock.uptimeMillis(); // 获取当前时刻
Message prevMsg = null;
Message msg = mMessages; // Message是一个链表的结构,而mMessages相当于"头指针"
if (msg != null && msg.target == null) {
// 当message的target为null的时候,被认为是一个特殊的message,我们应当跳过这类message
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// 当时间还没到message的执行时间时,更新nextPollTimeoutMillis
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// message到时间,需要被处理
mBlocked = false; // 取消阻塞状态标记
// 从链表中取出表头的message
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse(); // 标记使用状态
return msg; // 返回该message
}
} else {
// msg == null,没有消息
nextPollTimeoutMillis = -1; // 如果该值为-1,nativePullOnce()将会无限执行直到有新的消息通知
}
// 处理退出消息循环的请求,返回null退出消息循环
if (mQuitting) {
dispose();
return null;
}
这个过程比较简单,需要注意的就是Message的链表结构,每次取首元素来进行处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// 只会在第一次没有消息的时候执行,检查mIdleHandlers中注册的IdleHandler
if (pendingIdleHandlerCount < 0 && (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
// 如果没有注册pendingIdleHandler,继续保持阻塞状态
if (pendingIdleHandlerCount <= 0) {
mBlocked = true;
continue;
}
// 初始化mPendingHandlers
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
// 执行pendingIdleHandler
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null;
boolean keep = false;
try {
// 实质上是执行queueIdle()方法
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
// 如果返回是false,则移除这个IdleHandler,不会再执行
synchronized (this) { mIdleHandlers.remove(idler);
}
// 重置pendingIdleHandler计数
pendingIdleHandlerCount = 0;
// 由于执行IdleHandler过程中可能已经有新的消息到来,故设置超时为0,直接检查新的消息
nextPollTimeoutMillis = 0;
}
这里的mIdleHandlers中注册了一些需要在没有消息处理时进行的任务,在处理这些任务的过程中使用了pendingIdleHandler作为临时容器。这个过程就是去执行这些IdleHandler的过程。
现在我们看完了返回消息的全过程,其中只有一环没有解决了:nativePollOnce
NativePollOnce()
调用的是Native层android_os_MessageQueue.cpp下的函数:
1
2
3
4
5static void android_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj,
jlong ptr, jint timeoutMillis){
NativeMessageQueue* nativeMessageQueue = reinterpret_cast(ptr);
nativeMessageQueue->pollOnce(env, obj, timeoutMillis);
}
根据传入的地址,找到了之前新建的NativeMessageQueue对象,调用它的pollOnce()方法(注意参数中的timeoutMillis):
1
2
3
4
5
6
7
8
9
10
11
12
13void NativeMessageQueue::pollOnce(JNIEnv* env, jobject pollObj, int timeoutMillis){
mPollEnv = env;
mPollObj = pollObj;
mLooper->pollOnce(timeoutMillis);
mPollObj = NULL;
mPollEnv = NULL;
if (mExceptionObj) {
env->Throw(mExceptionObj);
env->DeleteLocalRef(mExceptionObj);
mExceptionObj = NULL;
}
}
其实调用的是保存的NativeLooper的pollOnce()方法(注意参数中的timeoutMillis)。
现在我将NativeLooper中关于Native事件循环的代码全部忽略,只分析与前面这个过程有关的部分:
1
2
3
4
5int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData){
...
result = pollInner(timeoutMillis);
}
}
调用了pollInner()方法(注意参数中的timeoutMillis),分为两部分分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40int Looper::pollInner(int timeoutMillis){
...
mPolling = true;
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
mPolling = false;
...
// 检查轮询错误
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
ALOGW("Poll failed with an unexpected error: %s", strerror(errno));
result = POLL_ERROR;
goto Done;
}
// 检查轮询超时
if (eventCount == 0) {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ pollOnce - timeout", this);
#endif
result = POLL_TIMEOUT;
goto Done;
}
// 处理事件
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
if (fd == mWakeEventFd) {
if (epollEvents & EPOLLIN) {
awoken();
} else {
ALOGW("Ignoring unexpected epoll events 0x%x on wake event fd.", epollEvents);
}
} else {
...
}
}
第6行就是事情的关键,我们执行了系统epoll_wait()调用(对我们之前创建的mEpollFd epoll实例),这是一个阻塞调用,当注册的Fd有新内容或者到达超时时间时才会返回。我们还记得前面我们创建了mWakeEventFd和eventItem并把它注册到了mEpollFd中。这样,只要mWakeEventFd中有了新的内容,这行调用就会返回,解除阻塞。
现在我们可以推测,当有新消息到来时,正是以向mWakeEvendFd中写入内容的方式来使nativePollOnce()调用返回,达到了通知消息循环继续处理的目的。
如果没有新的消息呢?我们一步步传进来的timeoutMillis就作为了epoll_wait()的超时参数,一旦到达这个时间,epoll_wait()函数就会返回,这达到了我们等待一段时间再去执行下一条消息的目的。
如果超时,20行检测出超时,跳转到Done。
如果因fd触发而返回,会进入28行的事件处理过程,这个过程依据拿到的eventItem对象,检查fd与events标志,如果是我们之前设置的用于唤醒的mWakeEventFd,调用awaken():
1
2
3
4void Looper::awoken(){
uint64_t counter;
TEMP_FAILURE_RETRY(read(mWakeEventFd, &counter, sizeof(uint64_t)));
}
做的事情非常简单,通过read()读取并清零fd中的数据。
你可能会想,为什么什么事情都没有做呢?因为这个mWakeEventFd存在的唯一目的就是解除阻塞,现在这个目的已经达到了,我们只要重置它以便下一次使用就可以了。
Done标号以后的代码与我们的过程无关,执行了自定义fd消息处理相关的内容。最后将result返回:
1return result;
现在我们可以重新看待nativePollOnce()函数,再次强调,它的作用是阻塞,当有新的消息或达到超时后返回。而这个核心的特性,完全是利用系统提供的epoll机制实现的。
现在整个Java消息循环的处理过程已经看完了,下面我们来结合常用的Handler来讲解向消息队列中投入新的消息的过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









