






 本文深入解析并发编程概念,包括进程、线程、并发与并行的区别,探讨线程的实现方式、状态及线程同步机制。详细介绍Synchronized锁机制与Lock接口的特性,对比两者差异,阐述线程间共享变量的可见性保证方法,最后讲解线程复用及多线程执行框架ThreadPoolExecutor的使用。
本文深入解析并发编程概念,包括进程、线程、并发与并行的区别,探讨线程的实现方式、状态及线程同步机制。详细介绍Synchronized锁机制与Lock接口的特性,对比两者差异,阐述线程间共享变量的可见性保证方法,最后讲解线程复用及多线程执行框架ThreadPoolExecutor的使用。
1. 什么是并发?
程序的并行执行。
2. 什么是程序?
应用进程。
3. 由进程引申出线程,什么是线程?
线程是程序运行的最小单元,轻量级进程,也是CPU调度的最小单位。
4. 有了进程,为什么还要有线程?
线程是程序执行的最小单元,所以线程的创建、销毁都比较快。
5. 哪些方式可以实现线程?
继承Thread类和实现Runnable接口(还有一些其他的线程工具ThreadLocal/ThreadPoolExecutor/Callable和Fulture等...)
6. 线程有哪些状态?
通俗的讲:新建、就绪、运行、阻塞、死亡
按照线程定义来讲:新建、运行(包含运行和可运行)、阻塞、等待、超时等待、终止
7. 有哪些方式可以实现线程同步?
JVM关键字Synchronized和JUC工具Lock接口
8. Synchronized
①、作用域:
1.修饰实例方法:方法的作用域为当前实例范围
2.修饰静态方法:方法的作用域为跨对象的
3.修饰代码块:方法的作用域为同步代码块
②、Synchronized锁
Synchronized锁为独占锁,非公平锁。
基于锁的粒度:偏向锁(无锁状态)--->轻量级锁(无锁状态)--->重量级锁(有锁)
偏向锁:单线程应用场景中,线程获取锁的时候,会先获得锁对象的MarkWord,判断锁对象是否处于可偏向状态,
如果是可偏向状态,就通过CAS操作把当前线程的线程ID写入到MarkWord中,如果CAS成功,表示当前线程获取到了对象锁,可以执行同步代码了,如果CAS失败,表示有其他线程正在执行,则需要撤销当前的偏向锁,将锁升级为轻量级锁。
如果是已偏向状态,需要检查当前MarkWord中的线程ID是否为当前线程的,如果是,直接直接同步代码,如果不是,则锁升级为轻量级锁。
轻量级锁:通过自旋的方式去CAS竞争锁资源。直到获取到锁(自旋的过程会一直占用CPU,浪费资源),自旋会存在一定的自旋次数,超过次数没有获取到锁资源,锁会膨胀为重量级锁。
重量级锁:独占锁,只有一个线程会获取锁资源,其他没有获取到锁资源的线程会被挂起,放入到同步队列(双向链表的同步队列,支持FIFO)中,当执行中的线程释放了锁资源后,会去同步队列中拿线程并执行。
基于ObjectMonitor监视器来实现线程通信
wait:调用当前线程的wait方法后,会将当前线程放入阻塞队列(单向链表的阻塞队列)中,释放CPU,释放锁资源,直到调用notify方法后才能放入到同步队列中继续去争抢锁资源。
notify:唤醒阻塞队列中的某个线程,唤醒后,该线程会从阻塞队列中转移到同步队列中,等待被执行。
9. Lock
Lock接口的实现类
①.ReentrantLock(独占锁,可重入锁)
可重入锁指的是线程在获得锁之后,再次获取锁不需要再竞争,而是关联一次计数器增加冲入次数。
②.ReentrantReadWriteLock(共享锁)
共享锁适用于读多写少的场景,读读共享、读写互斥、写写互斥。
Lock接口对应的工具
①.Condition(实现线程通信)
await()--->Object.wait()
signal()--->Object.notify()
②.CountDownLaunch(计数器,可以用来模拟并发场景)
CountDownLatch countDownLatch = new CountDownLatch(1000);
只有当计数器归0后,调用CountDownLaunch.await()方法的线程才能获取到锁。
③.Semaphore(限流)
Semaphore semaphore = new Semaphore(5);
semaphore.acquire();//+1
semaphore.release();//释放
10. Synchronized和Lock的区别
①Synchronized是JVM关键字,Lock是接口
②Synchronized是被动获得锁,程序执行完后自动释放,Lock需要手动获取锁,程序执行完后要手动释放。
③基于自动和手动,Lock的扩展性比较强
11. 线程间保证共享变量的可见性
volatile关键字:保证共享变量之间的可见性。
分析:对于程序的执行效率,CPU>内存>磁盘,所以为了保证程序的运行速度,就要最大化的利用CPU资源,所以就有了CPU自己的缓存,因此CPU与CPU之间的数据共享以及CPU与内存之间的数据同步可能就会出现差异。
解决方案:
①基于总线锁实现CPU与内存之间的通信,基于缓存锁实现CPU自己的数据缓存。
②在多核CPU情况下,如果CPU1对一个共享变量进行修改,就要通知其他CPU对该变量进行修改,这个过程中CPU1一直处于等待其他CPU对他的回执,浪费CPU资源,因此提出了StoreBuffer
③CPU1将数据写入到StoreBuffer中,由StoreBuffer异步通知其他CPU要对该变量进行修改,这样,CPU1就可以去处理其他的线程,不会处于等待状态。
④多个CPU通过StoreBuffer对内存中的数据进行修改,会造成重排序的问题-->引入内存屏障。
⑤多核CPU、内存之间的共享变量,在缓存的过程中,会出现缓存一致性问题(CPU1从内存中对共享变量进行操作,总线锁会给当前CPU分配内存空间,其他CPU想获取数据只能等待)
⑥缓存一致性协议(常用的MESI协议)
M:Modify 表示共享的数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的数据和主内存的数据不一致。
E:Exclusive 表示缓存的独占状态,数据只缓存在当前的CPU中,并且没有被修改
S:Shared 表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存的数据一致。
I:Invalid 表示缓存已经是失效的
CPU读操作:缓存处于M、E、S状态都可以被读取,I状态CPU只能从内存中去读取数据。
CPU写请求:缓存处于M、E状态才能被写,对于S状态的写,需要将其他CPU中缓存行置为无效才可以写。
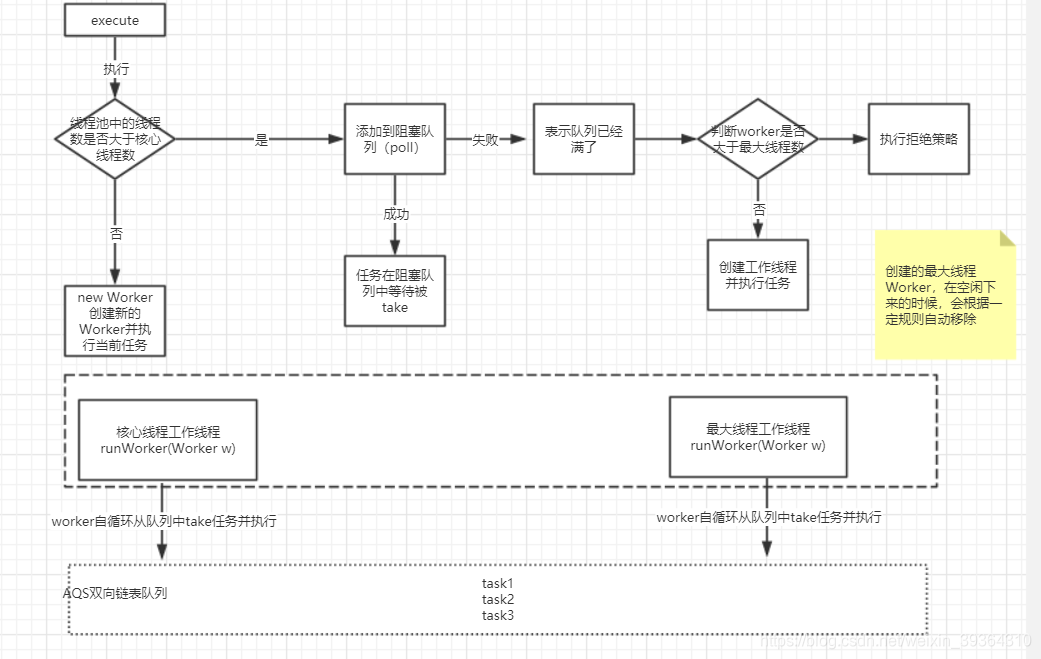
12. 线程复用–>多线程ThreadPoolExecutor
①实际开发中,不可能总是在每次需要用到线程的时候就去创建一个,这样可能造成线程数过多,导致频繁的上下文切换,浪费资源。
②引入多线程,创建一定数量的worker线程,来执行任务。
③ThreadPoolExecutor的几个参数:
corePoolSize:核心线程数
maximumPoolSize:最大线程数
maximumPoolSize:超时时间
unit:超时时间的单位
workQueue:阻塞队列
threadFactory:线程工厂
handler:拒绝策略
线程池工作原理

















 2232
2232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









