




 本文介绍了在数据处理和特征工程中如何巧妙运用时间戳来高效地处理时序数据,提供两种示例,包括如何按15秒间隔统计用户下单次数以及获取输入时间前一周的数据。通过时间戳的运算,可以灵活地对时间进行划分和统计。
本文介绍了在数据处理和特征工程中如何巧妙运用时间戳来高效地处理时序数据,提供两种示例,包括如何按15秒间隔统计用户下单次数以及获取输入时间前一周的数据。通过时间戳的运算,可以灵活地对时间进行划分和统计。
时序数据处理小技巧—巧用时间戳
数据处理和特征工程中中常常会遇到对时序数据的聚合统计等操作,我在未发现这个技巧之前,常常需要查各类时间处理的函数的api。但当有一次,有个朋友问我如何每间隔15秒(比较极端)统计多个不同账号的下单次数时,我发现使用现有函数去对划分时间很困难。这时我想到了时间戳去解决这个需求
示例一
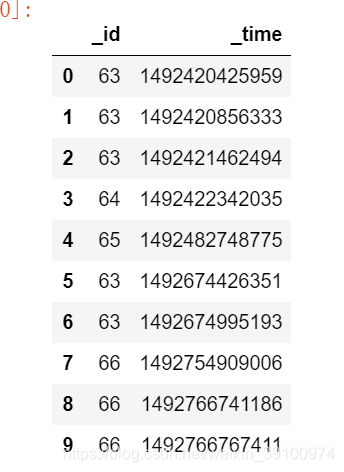
上图为某个流水表的部分数据,_id代表了一个用户,_time是下单时间,如何每隔15秒统计一次用户的下单次数呢?
以往做的都是按月,按天统计时,可以把时间戳转换成datetime,调函数去获得对应时间的进行统计。然而只要理解了时间戳就是格林威治时间到现在经过的秒或毫秒,那么我们就只需要一句代码就可以对这部分数据进行处理了
df['new_time'] = df._time.apply(lambda x:x//15000*15000)
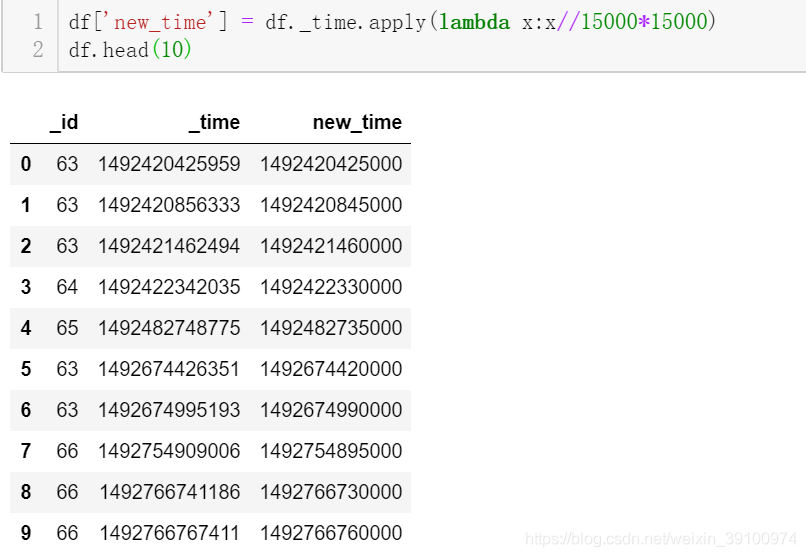
如上图所示,new_time将数据按每隔15秒进行了一个切分(15秒=15000毫秒)。然后我们对相应地数据进行聚合统计就可以了。因为这里是多个用户的下单,正常我们需要按_id聚合后再按new_time进行聚合,这里在提另一个小技巧:字符串的拼接。
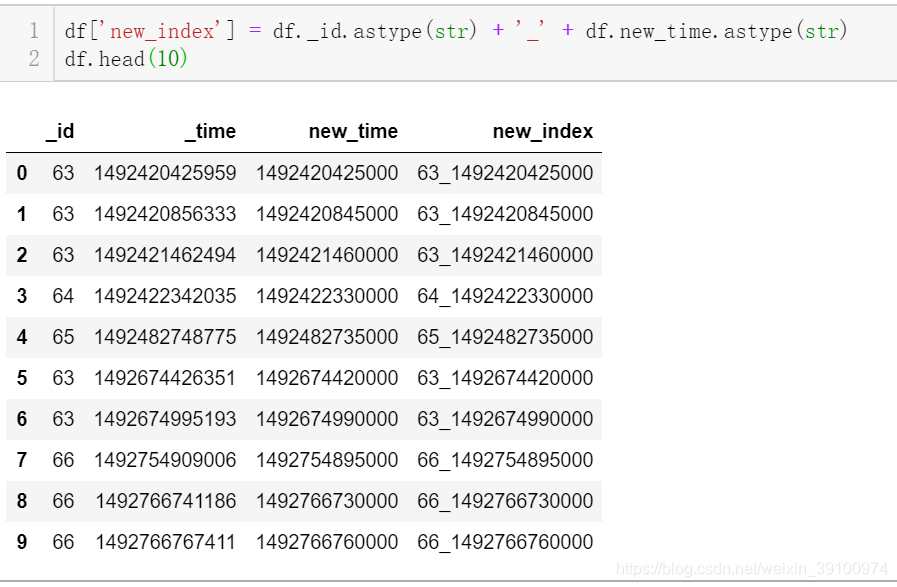
如上图所示,我们只需要对新拼接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









