




 本文对比了jQuery对象和DOM对象的使用方式及特性,详细解释了如何通过$.eq()方法从jQuery对象中获取单个元素,并展示了这两种对象在操作DOM元素(如修改内容和绑定事件)上的不同。
本文对比了jQuery对象和DOM对象的使用方式及特性,详细解释了如何通过$.eq()方法从jQuery对象中获取单个元素,并展示了这两种对象在操作DOM元素(如修改内容和绑定事件)上的不同。
先看官方对jquery eq() 的说明:
如果给定表示 DOM 元素集合的 jQuery 对象,.eq() 方法会用集合中的一个元素构造一个新的 jQuery 对象。所使用的 index 参数标示集合中元素的位置。
注意:这里eq() 返回一个jquery对象,可以使用jquery的属性,方法。
看一段代码:
<div id="userName">test</div>
<script src="js/jquery-2.0.3.min.js"></script>
<script>
console.log('1---->', $('#userName'));
console.log('2---->', $('#userName').eq(0));
console.log('3---->', $('#userName')[0]);
// 比较一:改变DOM元素值
// $('#userName').text('张三');
// $('#userName').eq(0).text('张三');
// $('#userName')[0].innerText = "张三";
// 比较二:绑定事件
$('#userName').click(function() {
console.log('1--->success')
})
$('#userName')[0].addEventListener('click', function() {
console.log('2--->success');
})
$('#userName')[0].onclick = function() {
console.log('3--->success');
}
</script>
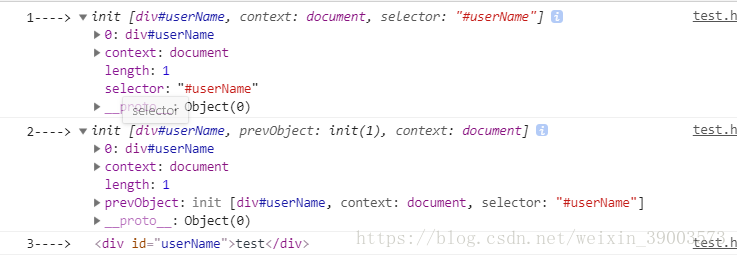
可以看到,$('#userName') 、$('#userName').eq(0) 打印出来的是jquery 对象,而 $('#userName')[0] 打印出来的是dom对象,将 $('#userName') 取到的jquery对象转化为了dom对象。
$('#userName') 、$('#userName').eq(0) 得到的jq对象,可以使用jq的属性和方法,通过 .text('newValue') 来改变div的值,而 $('#userName')[0] 得到的dom对象,则可以使用dom属性和方法,通过 innerText 、innerHTML 这两个DOM属性修改div的值,而不能混用jq对象的属性和方法。
- 首先,观察 $('#userName') 、$('#userName').eq(0) 、$('#userName')[0] 三者打印在控制台的样子:
- 执行比较一中的三种改变div值的方法,可以发现三种写法均可以正确修改div的值,由此可得:
- 比较二中的三种监听 div 点击事件的方法,都可以生效,但是不能混用,比如 $('#userName') 用 addEventListener 监听点击事件则会报错,也是同样的道理。
总结:$('#userName')[0] 获取到的是 dom对象(可以使用dom属性,方法,不可以使用jq属性方法),而 $('#userName').eq(0) 获取到的则是 jquery对象(可以用jq的属性、方法,不可以使用dom属性方法)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











