






1. kafka的简介
kafka之前是LinkedIn在2011年开源项目,并且也是在2011年加入Apache基金会. Apache kafka是消息中间件的一种.
参考例子说明:
生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
2. Kafka的设计和结构
2.1 kafka基本概念
- producer:消息和数据的生产者,就是它来生产“鸡蛋”的。
- consumer:消息和数据的消费者,生出的“鸡蛋”它来消费。
- consumer group: 对于同一个topic会广播给不同的group,一个group中只有一个consumer可以消费该消息。
- topic:你把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的“鸡 蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃”了。
- broker:kafka集群中的每个kafka节点, 就是篮子了。
- partition: kafka下数据存储的单元.一个topic数据会被分散存储到多个partition,每一个partition是有序的.
2.2 kafka基本结构
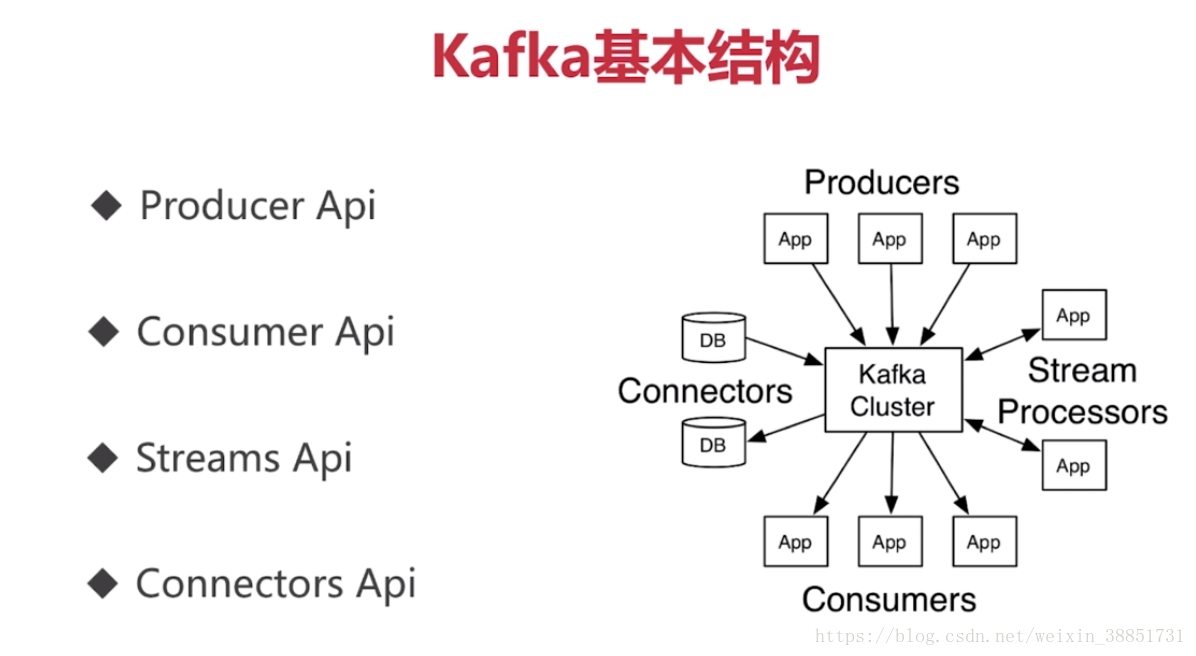
kafka特点:
- 分布式特点
多分区, 多副本, 多订阅者(即kafka的一个topic可以有一个或者多个订阅者,但是订阅者数量要少于topic的数量), 基于ZooKeeper的调度. - 高性能特点
高吞吐量, 低延迟, 高并发, 时间复杂度为O(1). - 持久性和扩展性
数据可持久化, 容错性, 支持在线水平扩展, 消息自动平衡
3. kafka的应用场景
- 消息队列
- 行为跟踪
- 元数据监控
- 日志收集
- 流处理
- 事件源
- 持久性日志
4. kafka的使用
4.1 下载并安装
- zookeeper下载
http://zookeeper.apache.org/releases.html#download - kafka 下载
http://kafka.apache.org/downloads - 安装: 解压并配置环境
4.2 基于docker安装
参考大神的博客地址
docker-compose.yml文件如下:
version: '2'
services:
zk_server:
image: daocloud.io/library/zookeeper:3.3.6
restart: always
kafka_server:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
command: /bin/sh -c '/usr/local/work/start_server.sh'
restart: always
message_producer:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
- kafka_server:kafkahost
restart: always
message_consumer:
image: bolingcavalry/kafka:0.0.1
links:
- zk_server:zkhost
restart: always
4.3 kafka的项目中使用的示例
5. kafka高级特性
5.1 消息事务
数据传输的事务定义:
1. 最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不被传输.
2. 最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
3. 精确的一次: 不会漏发送也不会重复发送,每个消息仅被传输一次.
事务保证:
1. 内部重试问题: Procedure幂等处理
2. 多分区原子写入
5.2 零拷贝
在kafka中,使用sendfile调用减少了数据从磁盘读取到发送的之间的内核态到用户态之间的状态转换。

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









