 SpringBoot数据库访问方式
SpringBoot数据库访问方式





 本文详细介绍了SpringBoot中三种常见的数据库访问方式:MyBatis XML、MyBatis注解和Spring Data JPA,对比了各自的优缺点及适用场景。
本文详细介绍了SpringBoot中三种常见的数据库访问方式:MyBatis XML、MyBatis注解和Spring Data JPA,对比了各自的优缺点及适用场景。
前言:spring boot对关系型数据库访问一般采用以下三种方式方式访问:mybatis的xml、mybatis的注解版、spring data jpa。
环境准备:IntelliJ使用spring initializr创建项目,并添加相应的依赖:mybatis、jpa、mysql
项目结构:
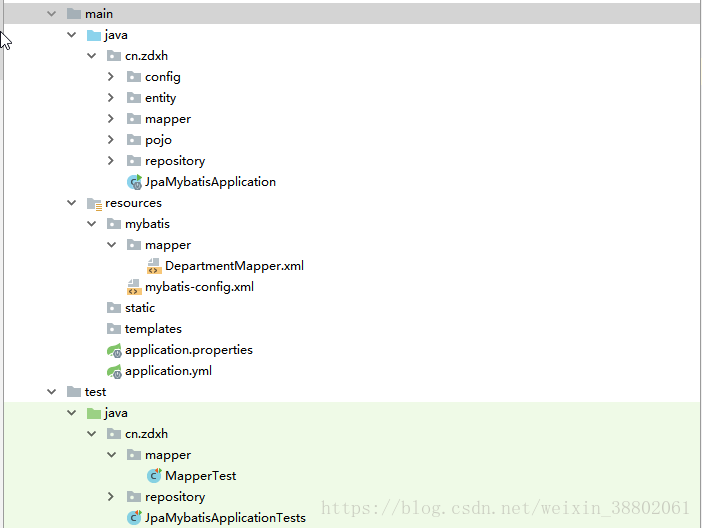
entity、repository目录:jpa数据访问
pojo、mapper(包括resources下)目录:mybatis数据访问
test目录:测试类
application.properties和application.yml文件:均可作为spring boot的配置文件,两者作用一样
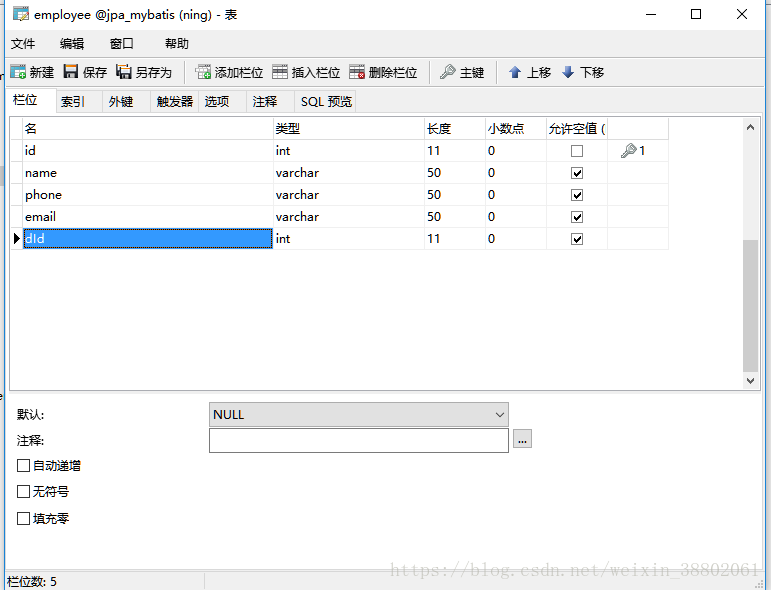
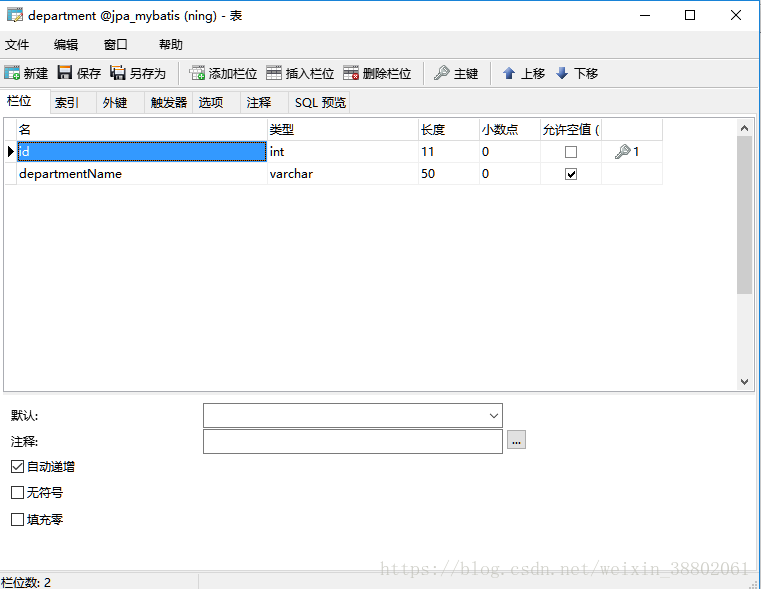
数据库结构:
员工表:employee(从表)
部门表:department(主表)
员工表和部门表存在一对多的关系(这里演示的是双向关系,实际开发要根据需求确定单向还是双向关系)
1、mybatis的xml方式
以application.yml为例:配置数据源和mybatis的sql映射文件
config-location:mybatis的配置文件位置
mapper-locations:mybatis的映射文件,*.xml为该目录下所有的xml的文件
spring:
datasource:
username: root
password: 12345
url: jdbc:mysql://localhost:3306/jpa_mybatis
driver-class-name: com.mysql.jdbc.Driver
mybatis:
config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mybatis/mapper/*.xml
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--mybatis的配置文件-->
<configuration>
</configuration>
department表的pojo类
public class Department {
private Integer id;
private String departmentName;
//关联查询,一个部门有多个员工
private List<Employee> employees;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getDepartmentName() {
return departmentName;
}
public void setDepartmentName(String departmentName) {
this.departmentName = departmentName;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
@Override
public String toString() {
return "Department{" +
"id=" + id +
", departmentName='" + departmentName + '\'' +
", employees=" + employees +
'}';
}
}
employee表的pojo
public class Employee {
private Integer id;
private String name;
private String phone;
private String email;
//department表,外键
private Integer dId;
//关联查询,一个员工属于一个部门
private Department department;
public Integer getdId() {
return dId;
}
public void setdId(Integer dId) {
this.dId = dId;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", name='" + name + '\'' +
", phone='" + phone + '\'' +
", email='" + email + '\'' +
", dId=" + dId +
", department=" + department +
'}';
}
}
DepartmentMapper接口
public interface DepartmentMapper {
//根据id查询某部门
public Department findDepById(Integer id);
//插入
public int insertDep(Department department);
//更新
public int updateDep(Department department);
//删除
public int deleteDep(Integer id);
//根据某部门名称查询部门的所有的员工,关联查询
public Department findAllEmployeesByDepName(String departmentName);
}
DepartmentMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.zdxh.mapper.DepartmentMapper">
<select id="findDepById" resultType="cn.zdxh.pojo.Department" parameterType="integer">
SELECT * FROM department WHERE id=#{id}
</select>
<insert id="insertDep" parameterType="cn.zdxh.pojo.Department" useGeneratedKeys="true">
INSERT INTO department(departmentName) VALUES (#{departmentName})
</insert>
<update id="updateDep" parameterType="cn.zdxh.pojo.Department">
UPDATE department SET departmentName=#{departmentName} where id=#{id}
</update>
<delete id="deleteDep" parameterType="integer">
DELETE FROM department WHERE id=#{id}
</delete>
<resultMap id="findAllEmp" type="cn.zdxh.pojo.Department">
<id property="id" column="id"/>
<result property="departmentName" column="departmentName"/>
<collection property="employees" ofType="cn.zdxh.pojo.Employee">
<id property="id" column="eId"/>
<result property="name" column="name"/>
<result property="phone" column="phone"/>
<result property="email" column="email"/>
<result property="dId" column="dId"/>
</collection>
</resultMap>
<select id="findAllEmployeesByDepName" resultMap="findAllEmp" parameterType="string">
SELECT
department.id,
department.departmentName,
employee.id eId,
employee.name,
employee.phone,
employee.email,
employee.dId
FROM department
LEFT JOIN employee
ON department.id=employee.dId
WHERE department.departmentName=#{departmentName}
</select>
</mapper>
以上的内容几乎和ssm的开发几乎一致,唯一的不同的就是不用配置那么多的配置文件,只需要简单配置一下数据源和映射文件的位置即可。使用spring boot开发相当快捷快速。这也是推荐的数据访问方式。
2、mybatis的注解方式
EmployeeMapper接口
public interface EmployeeMapper {
//根据员工id查询员工信息
@Select("select * from employee where id=#{id}")
public Employee findEmpById(Integer id);
//插入
@Insert("insert into employee(name,phone,email,dId) values(#{name},#{phone},#{email},#{dId})")
public int insertEmp(Employee employee);
//更改
@Update("update employee set name=#{name},phone=#{phone},email=#{email},dId=#{dId} where id=#{id}")
public int updateEmp(Employee employee);
//删除
@Delete("delete from employee where id=#{id}")
public int deleteEmp(Integer id);
//根据某员工姓名查询员工信息以及部门信息
@Select("select * from employee left join department on employee.dId=department.id where employee.name=#{name}")
@Results({@Result(property = "id",column = "id"),
@Result(property = "name",column = "name"),
@Result(property = "phone",column = "phone"),
@Result(property = "email",column = "email"),
@Result(property = "dId",column = "dId"),
@Result(property = "department",column = "dId",
one = @One(select = "cn.zdxh.mapper.DepartmentMapper.findDepById"))
})
public Employee findOneEmployeeAndDepartmentByName(String name);
}
@Select:查询
@Insert:插入
@Update:更新
@Delete:删除
根据删除、插入、更新还是删除,并且在里面加上相应的sql语句,就可完成简单的增删改查
如果涉及联表查询,@Results就相当于xml中的ResultMap标签,里面的@Result就相当于id和result标签
one:多对一或一对一用到的属性
one=@One(select="根据department的id查询department的方法全路径"):先通过查出的外键dId,再根据这个外键去二次查询
many:一对多,同理
mybatis两种方式的测试类
MapperTest类
@RunWith(SpringRunner.class)
@SpringBootTest
public class MapperTest {
@Autowired
EmployeeMapper employeeMapper;
@Autowired
DepartmentMapper departmentMapper;
/**
* 配置文件的测试类
*/
//根据id查询员工
@Test
public void testEmplyeeFindById(){
Employee employee=employeeMapper.findEmpById(3);
System.out.println(employee);
}
//添加
@Test
public void testEmployeeAdd(){
Employee employee=new Employee();
employee.setName("ning");
employee.setEmail("664650000@qq.com");
employee.setPhone("1318940000");
employee.setdId(1);
employeeMapper.insertEmp(employee);
}
//更新
@Test
public void testEmplyeeUpdate(){
Employee employee=new Employee();
employee.setId(3);
employee.setName("xiao");
employee.setEmail("664650000@qq.com");
employee.setPhone("1318940000");
employee.setdId(1);
employeeMapper.updateEmp(employee);
}
//删除
@Test
public void testEmplyeeDel(){
employeeMapper.deleteEmp(4);
}
//联表查询,一对多
@Test
public void testFindAllEmployeesByDepName(){
Department department = departmentMapper.findAllEmployeesByDepName("AA");
System.out.println(department);
}
/**
* 注解方式的测试方法
*/
//根据id查询部门
@Test
public void testDepartmentFindById(){
Department department=departmentMapper.findDepById(1);
System.out.println(department);
}
//添加
@Test
public void testDepartmentAdd(){
Department department=new Department();
department.setDepartmentName("BB");
departmentMapper.insertDep(department);
}
//更新
@Test
public void testDepartmentUpdate(){
Department department=new Department();
department.setId(2);
department.setDepartmentName("BB-BB");
departmentMapper.updateDep(department);
}
//删除
@Test
public void testDepartmentDel(){
departmentMapper.deleteDep(3);
}
//联表查询,多对一
@Test
public void testFindOneEmployeeAndDepartmentByName(){
Employee employee = employeeMapper.findOneEmployeeAndDepartmentByName("xiao");
System.out.println(employee);
}
}
3、spring data jpa方式
jpa面向接口,hibernate面向实现。jpa的底层就是hibernate
有hibernate基础的同学对jpa相信也会感觉很熟悉
首先在application.yml中添加如下设置
spring:
jpa:
hibernate:
ddl-auto: update #自动建表
show-sql: true #显示sql语句
employee的entity类
@Entity
@Table(name = "employee")//不写name的话就默认类名小写
public class Employee {
@Id//标志这是一个主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//标明这是自增主键
private Integer id;
@Column(name = "name")//不写也默认
private String name;
@Column(name = "phone")
private String phone;
@Column(name = "email")
private String email;
@Column(name = "dId")
private Integer dId;
private Department department;
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Integer getdId() {
return dId;
}
public void setdId(Integer dId) {
this.dId = dId;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", name='" + name + '\'' +
", phone='" + phone + '\'' +
", email='" + email + '\'' +
", dId=" + dId +
'}';
}
}
department的entity类
@Entity
@Table
public class Department {
@Id//设为自动增长
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column
private String departmentName;
private Set<Employee> employees;
public Set<Employee> getEmployees() {
return employees;
}
public void setEmployees(Set<Employee> employees) {
this.employees = employees;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getDepartmentName() {
return departmentName;
}
public void setDepartmentName(String departmentName) {
this.departmentName = departmentName;
}
@Override
public String toString() {
return "Department{" +
"id=" + id +
", departmentName='" + departmentName + '\'' +
'}';
}
}
类上:
@Entity:标志该类为entity类
@Table(name=""):指定表名,不写则默认类名小写
属性上:
@Id:该属性为一个主键
@GeneratedValue(strategy=GenerationTpye.IDENTITY):设定主键为自动增长
@Column(name=""):该属性为普通属性
上面的这些映射信息和hibernate的映射信息几乎一样
注意:这里的jpa没有做联表查询操作,需要深入了解的同学可以参考@OneToMany、@ManyToOne、@OneToOne等注解,和hibernate配置的many-to-one等标签相似度也很高。
DepartmentRepository接口
/**
* 只需要继承JpaRepository即可进行简单的crud
* 参数一:实体类类型
* 参数二:实体类的id类型
*/
public interface DepartmentRepository extends JpaRepository<Department,Integer> {
}
EmployeeRepository接口
/**
* 只需要继承JpaRepository即可进行简单的crud,如果需要进行复杂的查询则需要另继承JpaSpecificationExecutor
* JpaRepository 参数一:实体类类型 参数二:实体类的id类型
* JpaSpecificationExecutor 参数:实体类类型
*/
public interface EmployeeRepository extends JpaRepository<Employee,Integer>,JpaSpecificationExecutor<Employee> {
}
继承JpaRepository接口就可以进行简单的增删改查和分页功能
泛型参数一:实体类类型
泛型参数二:实体类中的id的类型
再继承JpaSpecificationExecutor接口,一些复杂的条件类型查询就可以实现
泛型参数:实体类类型
DepartmentRepositoryTest类
@RunWith(SpringRunner.class)
@SpringBootTest
public class DepartmentRepositoryTest {
@Autowired
DepartmentRepository departmentRepository;
@Autowired
DataSource dataSource;
@Test
public void testDepartmentFindById(){
Department department=new Department();
department.setId(1);
Example example= Example.of(department);
Optional<Employee> one = departmentRepository.findOne(example);
if (one.isPresent()){
System.out.println(one.get());
} else {
System.out.println("查询的值不存在!");
}
}
}
注意:这里是以spring boot2.00以上版本作为测试实例,Optional类是jdk1.8的新特性,专门解决空指针异常的,给里面传一个Example类作为参数。和spring boot1.00版本的findOne方法会有所不同,直接传入id就行。
EmployeeRepositoryTest类
@RunWith(SpringRunner.class)
@SpringBootTest
public class EmployeeRepositoryTest {
@Autowired
EmployeeRepository employeeRepository;
@Test
public void testEmployeeAdd(){
Employee employee=new Employee();
employee.setName("jian");
employee.setEmail("666666666@qq.com");
employee.setPhone("13189999999");
//employee.setdId(1);
employeeRepository.save(employee);
}
@Test
public void testEmplyeeUpdate(){
Employee employee=new Employee();
employee.setId(5);
employee.setName("xiao");
employee.setEmail("666666666@qq.com");
employee.setPhone("13189999999");
//employee.setdId(1);
employeeRepository.save(employee);
}
@Test
public void testEmplyeeDel(){
employeeRepository.deleteById(5);
}
@Test
public void testEmplyeeFindById(){
Employee employee=new Employee();
employee.setId(5);
Example example= Example.of(employee);
Optional<Employee> one = employeeRepository.findOne(example);
if (one.isPresent()){
System.out.println(one.get());
} else {
System.out.println("查询的值不存在!");
}
}
@Test
public void testEmployeeComplexQuery(){
//构造查询条件
Specification<Employee> specification = new Specification<Employee>() {
@Nullable
@Override
public Predicate toPredicate(Root<Employee> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path<Object> pathName = root.get("name");
Path<Object> pathPhone = root.get("phone");
Predicate predicatePhone = criteriaBuilder.equal(pathPhone, "1318999999");
Predicate predicateName = criteriaBuilder.equal(pathName, "ning");
return criteriaBuilder.and(predicateName,predicatePhone);
}
};
Optional<Employee> optional = employeeRepository.findOne(specification);
Employee employee = optional.get();
System.out.println(employee);
}
}
其他方法大同小异,只是testEmplyeeComplexQuery方法用来做复杂的条件查询(主要)
Spectification接口传入一个实体类构造查询类
主要实现toPredicate方法
参数Root:从中获得要查询的类型
参数CriteriaQuery:添加查询条件,例如OrderBy等等
参数CriteriaBuilder:构建perdicate,例如and、or等等,作为返回的值
还有两种方法可以拓展查询条件:(了解)
(1)、规范方法名,spring data会根据里面的关键词构造查询条件
(2)、@Query注解直接写查询条件
总结:虽然spring boot给我们提供那么多的访问数据的方式,但是实际开发当中不会全部的用到,要学会有取有舍,用自己最擅长的方式,也可以混合使用,当用到联表查询的时候可以直接用mybatis的xml,方便快捷又便于维护,如果说只是对单表的操作,用jpa的方式也不错,但是jpa的联表查询有一些复杂,对hibernate不熟的同学来说,也是一大挑战。

















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









