






 本文介绍了使用Python的Pandas库进行列表分列的三种实际应用场景,包括利用正则表达式提取并分列数据、分组聚合后进行分列以及解析JSON字符串后的字典分列。
本文介绍了使用Python的Pandas库进行列表分列的三种实际应用场景,包括利用正则表达式提取并分列数据、分组聚合后进行分列以及解析JSON字符串后的字典分列。

公众号后台回复“图书“,了解更多号主新书内容
来源:快学Python
作者:小小明
上次我分享了一道基础题N种解题思路,其中一种读取数据的过程涉及到列表分列,详见:《一道基础题,多种解题思路,引出Pandas多个知识点》
这次我将分享三个实际案例,让大家看看列表分列的一些实际应用。
首先,我们先导包并设置Pandas显示参数:
import pandas as pd
pd.set_option("display.max_colwidth", 100)
正则提取并分列
需求:
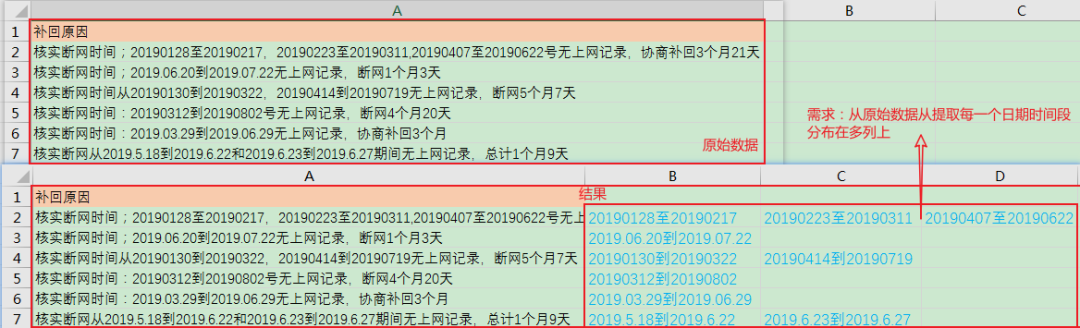
读取数据:
df = pd.read_excel("正则提取与分列.xlsm", usecols=[0])
df.head()
结果:
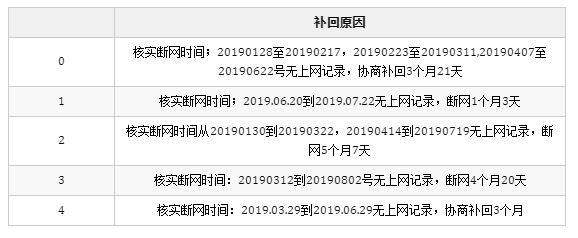
实现代码:
result = df.copy()
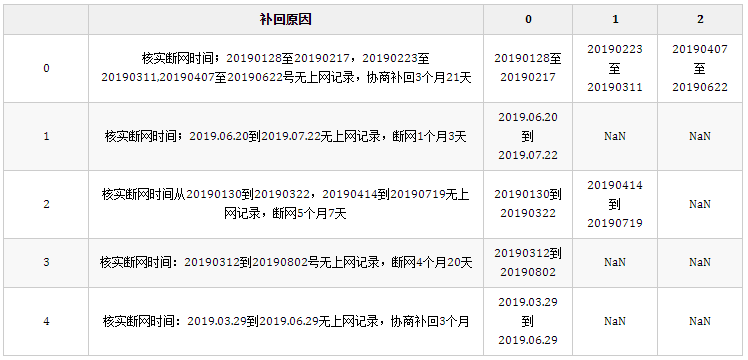
result["tmp"] = result["补回原因"].str.findall("([\d.]+[到至][\d.]+)")
result = result.agg({"补回原因": lambda x: x, "tmp": pd.Series}).droplevel(0, axis=1)
result.head()
结果:
分步解析:
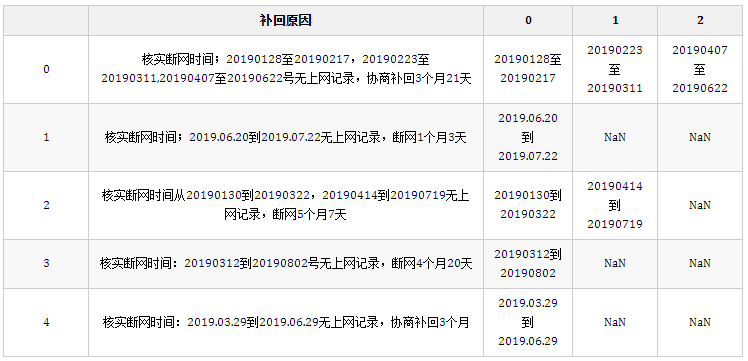
df["tmp"] = df["补回原因"].str.findall("([\d.]+[到至][\d.]+)")
df.head(5)
结果:

这步使用正则提取出每个日期字符串,[\d.]+表示连续的数字或.用于匹配时间字符串,两个时间之间的连接字符可能是到或至。
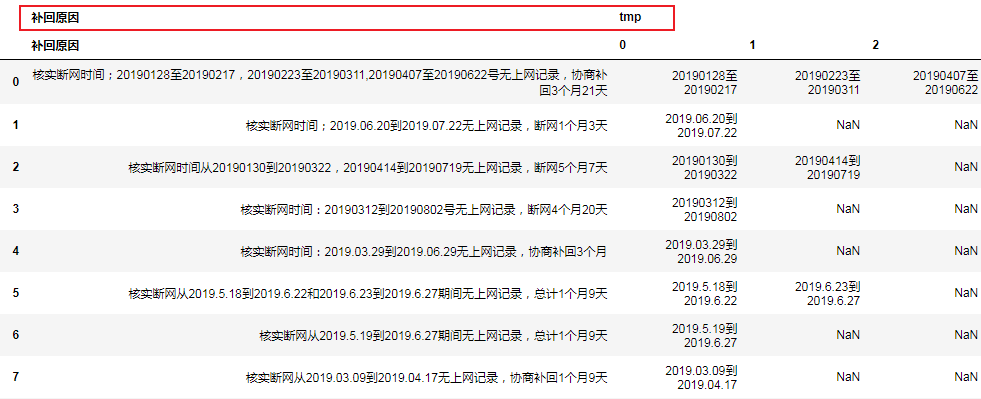
然后我使用agg函数直接对Datafream分列:
df.agg({"补回原因": lambda x: x, "tmp": pd.Series})
结果:
由于列索引多了一级,所以需要删除:
df.agg({"补回原因": lambda x: x, "tmp": pd.Series}).droplevel(0, axis=1).head()
结果:
droplevel(0, axis=1)用于删除多级索引指定的级别,axis=0可以删除行索引,axis=1则可以删除列索引,第一参数表示删除级别0。当然如果列索引存在名称时还可以传入名称字符串,可参考官网文档:
df = pd.DataFrame([
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12]
... ]).set_index([0, 1]).rename_axis(['a', 'b'])
>>> df.columns = pd.MultiIndex.from_tuples([
... ('c', 'e'), ('d', 'f')
... ], names=['level_1', 'level_2'])
>>> df
level_1 c d
level_2 e f
a b
1 2 3 4
5 6 7 8
9 10 11 12
>>> df.droplevel('a')
level_1 c d
level_2 e f
b
2 3 4
6 7 8
10 11 12
>>> df.droplevel('level2', axis=1)
level_1 c d
a b
1 2 3 4
5 6 7 8
9 10 11 12
分组聚合并分列
需求:
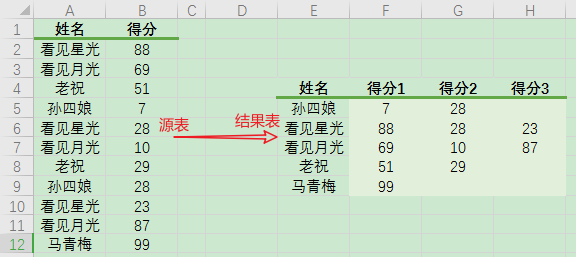
首先,读取数据:
df = pd.read_excel("分组聚合并分列.xlsx")
df
结果:
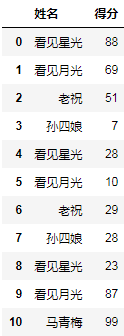
实现代码:
(
df.groupby("姓名")["得分"]
.apply(list)
.apply(pd.Series)
.fillna("")
.rename(columns=lambda x: f"得分{x+1}")
.reset_index()
.astype({"得分1":"int8"})
)
结果:
分布解析:
首先将每个姓名的得分聚合成列表,并最终返回一个Series:
df.groupby("姓名")["得分"].apply(list)
结果:
姓名
孙四娘 [7, 28]
看见星光 [88, 28, 23]
看见月光 [69, 10, 87]
老祝 [51, 29]
马青梅 [99]
Name: 得分, dtype: object
当然,这步的标准写法应该是使用Series的内部方法:
df.groupby("姓名")["得分"].apply(lambda x:x.to_list())
使用Series内部方法的性能比python列表方法转换快一些。
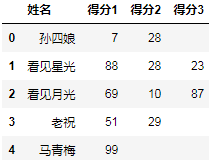
作为一个Series就可以通过将每个列表元素转换为Series,从而最终返回一个分列的Datafream:
_.apply(pd.Series)
结果:
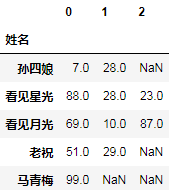
注意:
_在ipython表示上一个输出返回的结果,jupyter还额外支持_num表示num编号单元格的输出。
_.fillna("")
结果:
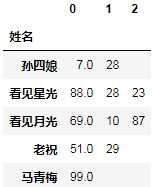
fillna表示填充缺失值,传入""表示将缺失值填充为空字符串。
下面重命名一下列名:
_.rename(columns=lambda x: f"得分{x+1}")
结果:
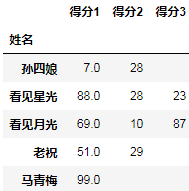
然后还原索引:
_.reset_index()
结果:
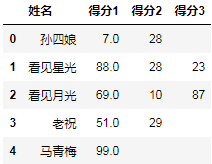
发现结果中有一列,不是整数,所以还原成整数(总分100分,8位足够存储):
_.astype({"得分1":"int8"})
结果:
解析json字符串并字典分列
需求:
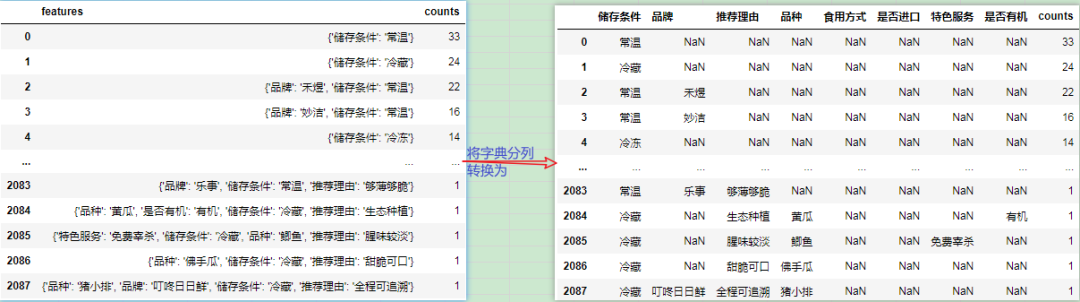
首先读取数据:
df = pd.read_excel("字典分列.xlsx")
df.head()
结果:
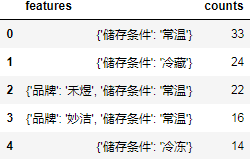
处理代码:
result = df.features.apply(eval).apply(pd.Series)
result["counts"] = df.counts
result
结果:
| 储存条件 | 品牌 | 推荐理由 | 品种 | 食用方式 | 是否进口 | 特色服务 | 是否有机 | counts | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 常温 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 33 |
| 1 | 冷藏 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 24 |
| 2 | 常温 | 禾煜 | NaN | NaN | NaN | NaN | NaN | NaN | 22 |
| 3 | 常温 | 妙洁 | NaN | NaN | NaN | NaN | NaN | NaN | 16 |
| 4 | 冷冻 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 14 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2083 | 常温 | 乐事 | 够薄够脆 | NaN | NaN | NaN | NaN | NaN | 1 |
| 2084 | 冷藏 | NaN | 生态种植 | 黄瓜 | NaN | NaN | NaN | 有机 | 1 |
| 2085 | 冷藏 | NaN | 腥味较淡 | 鲫鱼 | NaN | NaN | 免费宰杀 | NaN | 1 |
| 2086 | 冷藏 | NaN | 甜脆可口 | 佛手瓜 | NaN | NaN | NaN | NaN | 1 |
| 2087 | 冷藏 | 叮咚日日鲜 | 全程可追溯 | 猪小排 | NaN | NaN | NaN | NaN | 1 |
2088 rows × 9 columns
浅析:
df.features.apply(eval)用于将features列的每个json字符串解析为字典对象。
**.apply(pd.Series)则可以将每个字典对象转换成Series,则可以将该字典扩展到多列,并将原始的Series转换为Datafream。
而result["counts"] = df.counts则将原始数据的counts列添加到结果列中。
◆ ◆ ◆ ◆ ◆麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗

















 3305
3305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









