




 本文详细介绍了Spark中Shuffle的基本概念、触发条件及其实现原理。对比了早期版本与新版本中Shuffle机制的不同,并分析了这两种机制各自的优缺点。此外,还探讨了Spark与MapReduce在Shuffle过程中的差异。
本文详细介绍了Spark中Shuffle的基本概念、触发条件及其实现原理。对比了早期版本与新版本中Shuffle机制的不同,并分析了这两种机制各自的优缺点。此外,还探讨了Spark与MapReduce在Shuffle过程中的差异。
目录
Shuffle原理剖析与源码分析
1、在Spark中,什么情况下,会发生shuffle?reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup等操作。
2、默认的Shuffle操作的原理剖析
3、优化后的Shuffle操作的原理剖析
4、Shuffle相关源码分析
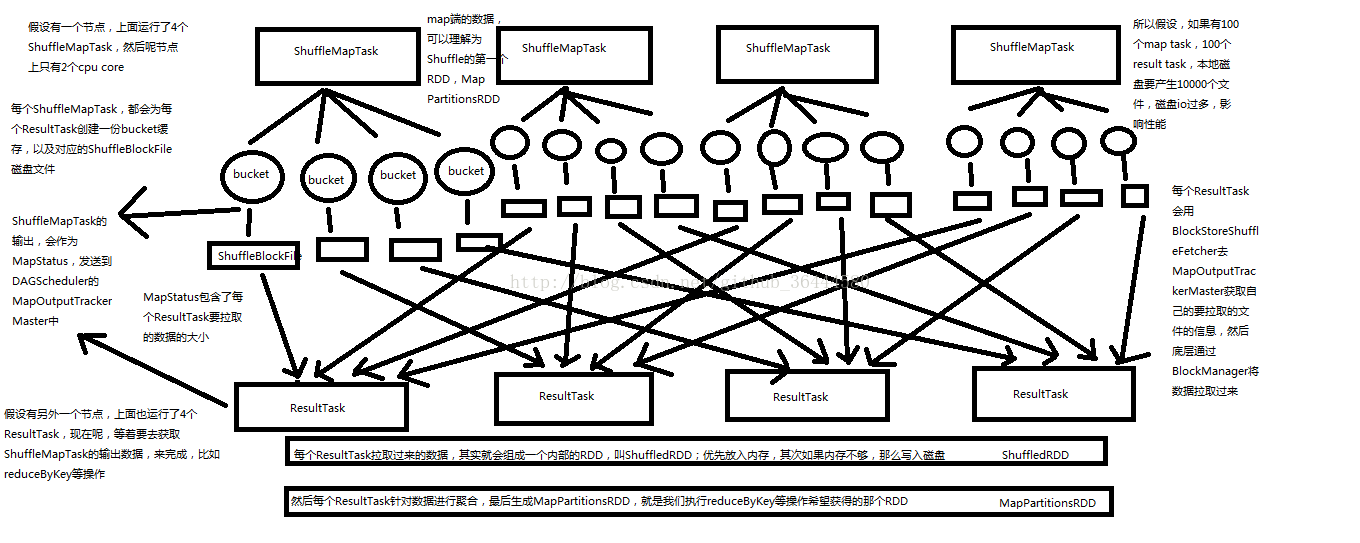
普通的shuffle:
优化后的shuffle:
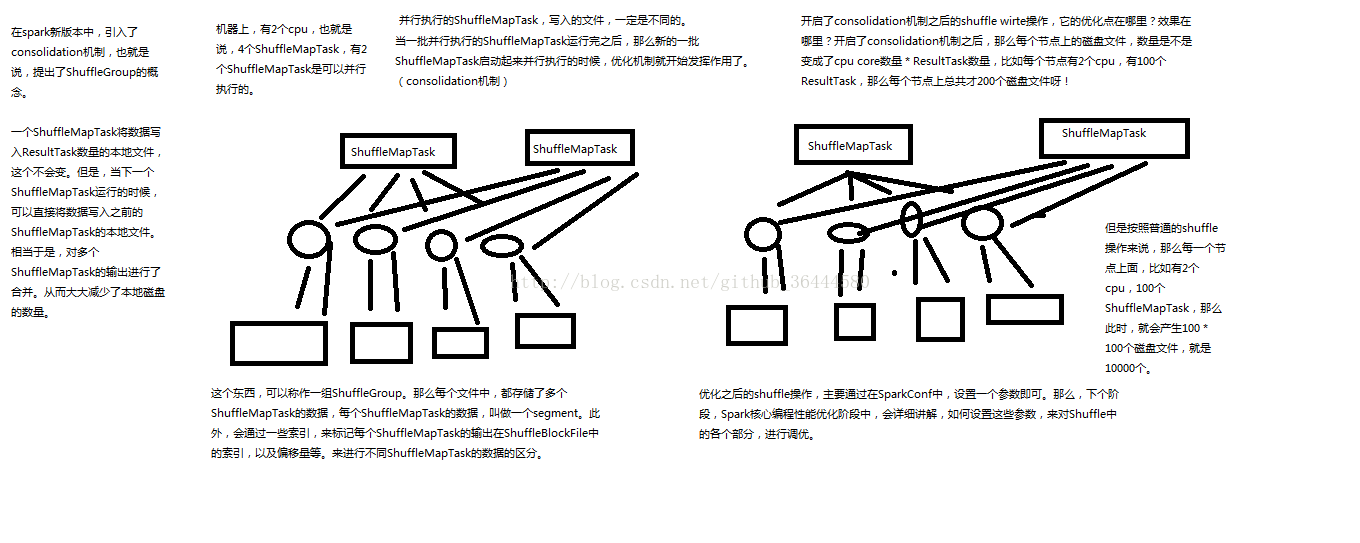
spark shuffle操作的两个特点
第一个特点,
在Spark早期版本中,那个bucket缓存是非常非常重要的,因为需要将一个ShuffleMapTask所有的数据都写入内存缓存之后,才会刷新到磁盘。但是这就有一个问题,如果map side数据过多,那么很容易造成内存溢出。所以spark在新版本中,优化了,默认那个内存缓存是100kb,然后呢,写入一点数据达到了刷新到磁盘的阈值之后,就会将数据一点一点地刷新到磁盘。
这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘写io操作。所以,这里的内存缓存大小,是可以根据实际的业务情况进行优化的。
第二个特点,
与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。为什么?因为mapreduce要实现默认的根据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后在本地执行我们定义的聚合函数和算子,进行计算。
spark这种机制的好处在于,速度比mapreduce快多了。但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很方便。但是spark中,由于这种实时拉取的机制,因此提供不了,直接处理key对应的values的算子,只能通过groupByKey,先shuffle,有一个MapPartitionsRDD,然后用map算子,来处理每个key对应的values。就没有mapreduce的计算模型那么方便。
原文参考:https://blog.youkuaiyun.com/github_36444580/article/details/78637355
参考:https://baijiahao.baidu.com/s?id=1579031780295476145&wfr=spider&for=pc

















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









