



 本文介绍了Kafka的核心概念,包括话题、分区和偏移量,以及节点、生产者、消费者和消费者组。通过Python的pykafka库,展示了如何创建生产者和消费者进行数据的生产和消费。同时,文中还封装了EasyProducer和EasyConsumer类,简化了pykafka的使用。此外,提到了配置设置文件setting.py的相关内容。
本文介绍了Kafka的核心概念,包括话题、分区和偏移量,以及节点、生产者、消费者和消费者组。通过Python的pykafka库,展示了如何创建生产者和消费者进行数据的生产和消费。同时,文中还封装了EasyProducer和EasyConsumer类,简化了pykafka的使用。此外,提到了配置设置文件setting.py的相关内容。
1 简介
Kafka是一个分布式、用于发布、订阅消息的系统。
2 核心概念
话题(Topic):某种消息的高层抽象。
分区(Partition):某个话题会被分为多个分区,每个分区都是一个排序且不可改变的队列。
偏移量(Offset):消息在进入队列时会被分配一个唯一的ID,官方称之为偏移量。
概念1 话题、分区、偏移量
Kafka的Topic是一个逻辑概念,Partition则是一个物理概念。
对于生产者来说,他们只需要知道发布的消息在Kafka集群层面上是哪个话题;对于消费者来说,也是一样,同样只需要知道哪个话题并向集群索取,并不需要了解真正的存储情况。
节点(Broker):集群中的每一个节点服务器,多个节点组成一个集群。
概念2 节点
假设一个Topic仅仅只是存在于一个Broker的一条队列中,如果这个节点遇到了性能瓶颈,那么我们将无法对其拓展。就这个问题看来,设计者选择将Topic内的数据分布到整个集群就是自然而然的设计方式,分区的引入就是为了解决水平拓展问题的一个方案。
除此之外,将话题分区,这也提高了系统的容错性。
生产者(Producer):消息生产者。
消费者(Consumer):消息消费者。
消费者组(Consumer Group):消费者组是一个逻辑概念,一个话题接收到消息时会向不同的消费者组广播,保证每一个消费者组都有且只有一条消息。
概念3 生产者、消费者、消费者组
生产者会将数据发送消息给话题(抽象概念)。发送的目的地最终到达的分区(物理概念),可以是根据轮讯策略(由Kafka集群选择分区),或是由生产者按照某种规则指定分区。
消费者则是真正使用消息,处理消息的对象。
消费者组是逻辑上的概念,同一个话题的消息,会广播给不同的组。当一个组有多个消费者的时候,只有一个消费者Worker可以拿到消息,这就是消费者的队列模式;若是有多个组,每个组都只有一个消费者,那生产者发布的消息,即是每一个消费者都能拿到,这便是第二种模式----发布订阅模式。
3 简单例子
大致了解了Kafka集群的基本概念后,现在利用python的第三方模块pykafka来做几个简单例子操作实验一下。
3.1 产生数据
图1就是一个简单的生产者产生数据的例子:
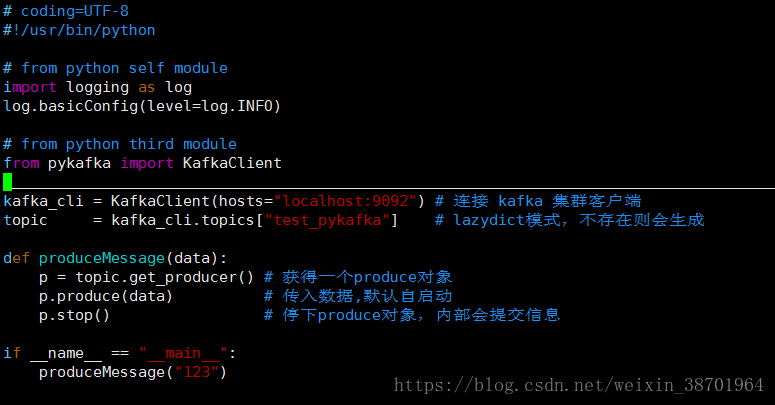
图1 生产者产生数据
在获取producer的时候,我没有传入任何参数,使用默认传入的参数。因此我们获得的是这
样一个producer对象,默认参数如下图2:
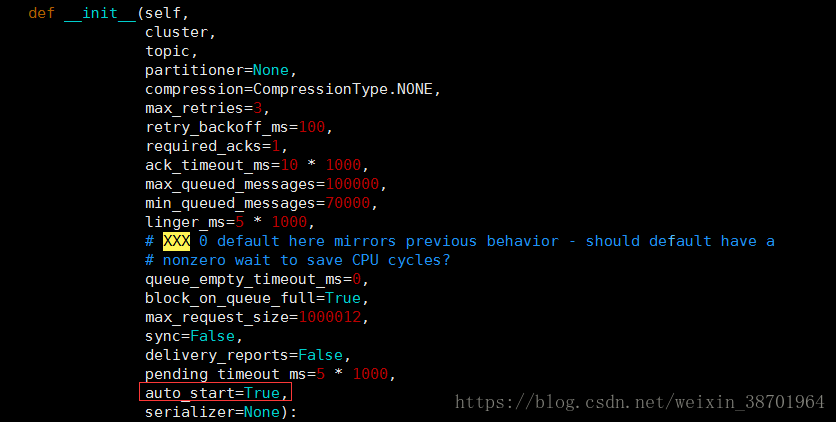
图2 Producer默认参数
其中,auto_start为True意味着是自初始化Produce就自动调用自身的start方法启动;sync
表示同步与否,设置为True则会阻塞等待到入集群的缓存队列并且获得delivery report为止,默
认是异步的。不同的用法当然根据你的具体需求。
图1的程序在获取后就自动启动了,手动调用stop即会flush数据到真正的broker上面。
3.2 消费数据
以下图3代码就是一个简单消费者的调用实例。
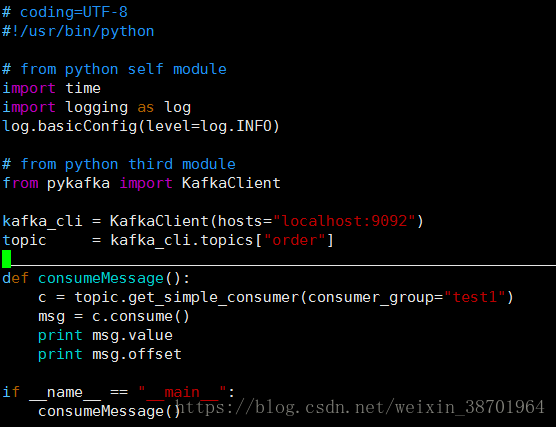
图3 消费者消费一条信息
在获得消费者的时候传入了consumer_group为test1。类似生产者,消费者类初始化的时候
同样auto_start参数是True,初始化自动启动消费者的worker。在回收对象的时候,析构函数也
会调stop方法,提交数据。
3.3 取得最新可用的消息
图4,消费者消费最新一条可用的消息。
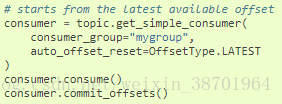
图4 消费最新的一条消息
这样当consummer调用consume消费时候,就会取得最新的一条未被消费的数据。如果队
列中的消息不足以消费,那么程序这次消费行为将会处于阻塞状态,直到队列出现新的消息。
如图5,队列的数据不足以被消费,因此消费者的consume被阻塞。

图5 阻塞情况模拟
如上图所示,我启动了一个consumer。由于消费者的offset已经到了最后一条可用消息的下
一个的位置,因此没有获得新的消息被阻塞。
我再在另外一个终端操作,启动一个producer,传入一条新的消息。看到了消费者这边原本
阻塞的终端消费了一条新的消息,如图所示:
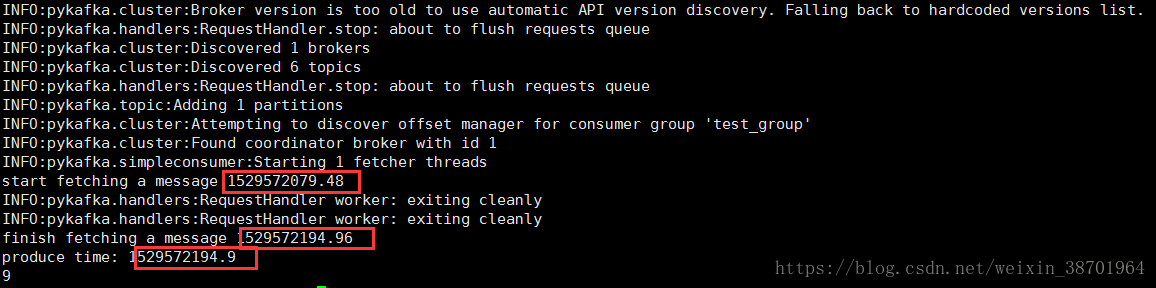
图6 阻塞情况恢复
可以看到,开始获取消息的时间戳要小于产生消息的时间戳,同时产生消息的时间戳要小于
成功获取到消息的时间戳。依旧这个顺序可以看出,消费者先阻塞,等待生产者生产了消息,然
后获得了这条新消息并消费了它。
这种阻塞的方式很适合在各种情景应用。比如,聊天器的接收终端。假设我们在和别人做即
时通讯,对于我们的服务器来说,我们并不知道什么时候对方会发送消息给我们,这个时候我们
就需要接收终端阻塞等待。
3.4 从最后一个提交的位移开始消费
如图4,我们可以来生成一个从最后一条提交的位移开始消费的消费者。
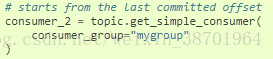
图7 从最后一个提交的位移开始消费的消费者
如果有一个情景,我们要获取当天新闻,而且我们已经将新闻传入了队列,我们产生的一个
消费者每次都要获得当天的消息来消费。
可以这样设计,在每天晚上12点整会将前一天的消息(当然前提是入队列的所有新闻都是顺
按时间顺序)的最后一条的offset提交了。那么第二天,我们利用消费者consume获得的新闻,
都是从今天最早的一条开始的。
这大概就符合这种情形。
下图是这种方式的模拟试验:
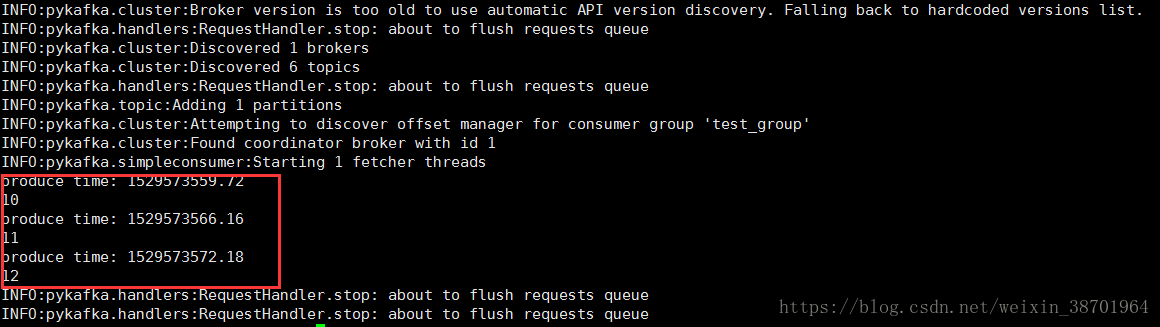
图8 从最后一个提交的位移开始消费
下面将最后一个位移提交了。结果如图所示:
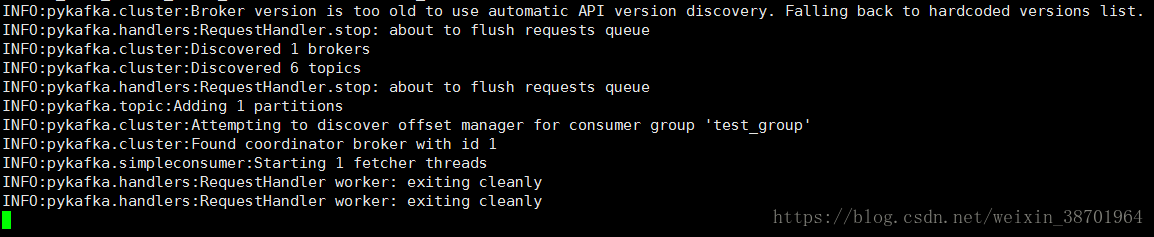
图9 位移到达了最后一个的下一个,阻塞
3.5 从队列头开始消费
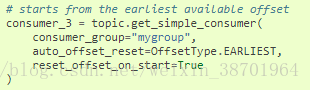
图10 从队列头开始消费
其中,auto_offset_reset被设置为了EARLIEST,reset_offset_on_start设置为True。依据官
方文档给出的解释,当reset_offset_on_start被设置为True的时候,将会将消费者位移计数器的
offset指向auto_offset_reset意味的值,此处即是队列头。
因此,实验出现了这样的结果,如下图所示:
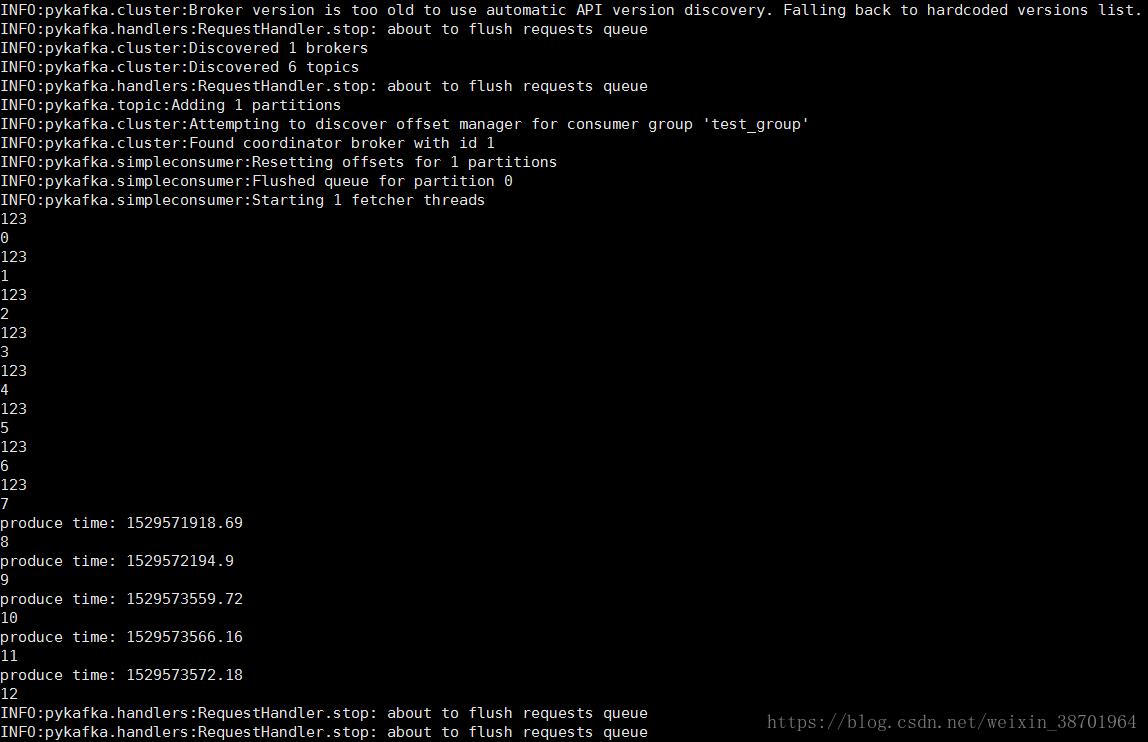
图11 该话题中的所有消息都被列出
4 为了能够方便的调试和学习,将生产者、消费者的以上几种用法封装成了简单的类
4.1 EasyProducer
模块:easy_pykafka.easy_producer
类名:easy_pykafka.easy_producer.EasyProducer
说明:将pykafka生产者简单操作的封装。
方法:
__init__(
self,
topic_name="test", # 指定话题
default_construct=True # 是否使用默认生成简单producer
) # 初始化
__del__(self) # 析构,停止producer对象的运行,flush数据到broker
producer_self_define() # 自行构建producer对象
produce(self, data) # 执行produce函数,产生数据
以下是简单的调用方法:

图11 easy_producer简单的使用方法
4.2 EasyConsumer
模块:easy_pykafka.easy_consumer
类名:easy_pykafka.easy_consumer.EasyConsumer
说明:将pykafka消费者的简单操作的封装,并且做了3种常见的用法。
方法:
__init__(
self,
topic_name ="test", # 指定话题
consumer_group = "test_group" # 指定消费者组
) # 初始化
__del__(self) # 析构函数
consume_lastest_message(
self,
consumer_group = None # 指定消费者组,如果没指定则以类初始化的为准
) # 获取最后一条可用的消息消费,同上的描述
onsume_from_the_last_commit_offset(
self,
consumer_group = None, # 同上
consume_num = 10, # 最大消费数量,如果消费达到这个数量则退出
commit_or_not = False # 消费后是否提交
): # 获得最后一次提交到现在为止的所有可用的数据
consume_from_the_very_beginning(
self,
consumer_group = None,
consume_num = -1 # 默认-1则从头消费到尾
): # 获得队列中所有的消息
commit_offsets(self) # 提交位移
使用方法示例:

图12 EasyComsumer简单使用示例
4.3 配置setting.py
目前只需要配置kafka集群的主机名和端口,ssl配置将会后续补充。如图所示:
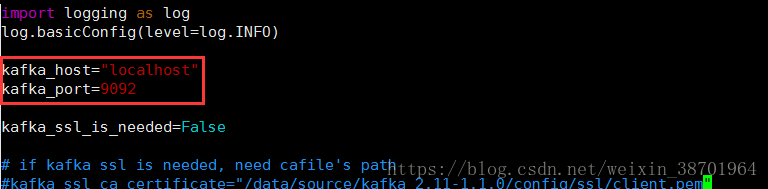
图13 easy_pykafka setting.py
补充ssl配置:
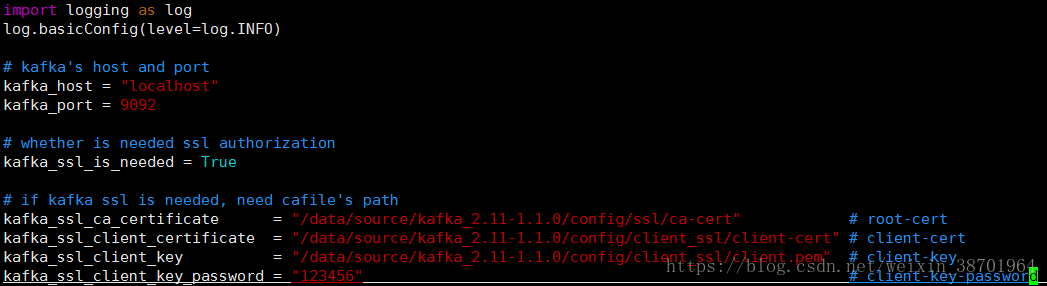
图14 easy_pykafka setting.py

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









