






 本文介绍了数据集中离散特征的两种编码方法:一种是对没有大小意义的特征采用one-hot编码;另一种是有大小意义的特征使用LabelEncoder思想进行数值映射,并提供了具体的Python代码示例。
本文介绍了数据集中离散特征的两种编码方法:一种是对没有大小意义的特征采用one-hot编码;另一种是有大小意义的特征使用LabelEncoder思想进行数值映射,并提供了具体的Python代码示例。
数据集中离散特征的编码分为两种情况:
- 离散特征的取值之间没有大小的意义(特征之间的欧式距离相同),比如color:[red,green],可以采用one-hot的方法
- 离散特征的的取值有大小的意义(特征之间的欧式距离不同),比如size:[X,XL,XXL],可以采用数值的映射{X:1,XL:2,XXL3},这种方式就是LabelEncoder()的思想
对离散特征的处理可以采用两种方式:
1、采用map()函数映射,处理欧式距离为0的特征-类似于One-Hot编码
import pandas as pd
df=pd.DataFrame([
['green','M',10.1,'class1'],
['red','L',13.5,'class2'],
['blue','XL',15,3,'class1']])
df.columns=['color','size','prize','class label']
size_mapping={
'XL':3,
'L':2,
'M':1
}
df['size']=df['size'].map(size_mapping)
class_mapping={
label:idx for idx in enumerate(set(df['class label']))
}
df['class label']=df['class label'].map(class_mapping)
说明:对于大小有意义的离散特征(欧式距离不相同),直接使用映射就可以了,{'XL':3,'L':2,'M':1}
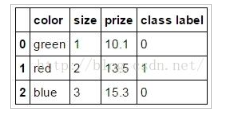
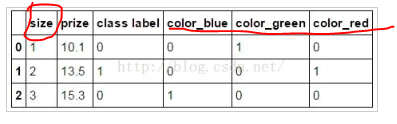
2、直接使用pandas.get_dummies()函数处理
函数:get_dummies()
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None,
sparse=False, drop_first=False)
参数说明:
data : array-like, Series, or DataFrame
输入的数据
prefix : string, list of strings, or dict of strings, default None
get_dummies转换后,列名的前缀
columns : list-like, default None
指定需要实现类别转换的列名
dummy_na : bool, default False
增加一列表示空缺值,如果False就忽略空缺值
drop_first : bool, default False
获得k中的k-1个类别值,去除第一个
print(pandas.get_dummies(df))

















 5595
5595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









