







 本文探讨了模型预测精度与训练样本数量之间的关系,并通过调整特征提取代码解决了精度提升问题。实验表明,当样本数量达到一定规模后,LR和MLPC模型精度提高,SGDC模型精度下降。
本文探讨了模型预测精度与训练样本数量之间的关系,并通过调整特征提取代码解决了精度提升问题。实验表明,当样本数量达到一定规模后,LR和MLPC模型精度提高,SGDC模型精度下降。
书接上回,再表一枝
(1)模型预测精度问题
上次出现的问题是自己训练出来的模型精确度和训练样本的数量不是呈现正相关关系,检查发现与原文作者的代码在实际执行的时候出现问题,也可能作者上传的代码不全(捂脸),代码如下图所示。此文件是特征提取部分代码get_features.py,对于第58行,同sample_nums下,选择的都是遍历所有图像,所以最后储存在score中的数据是同等训练样本数目下的模型精确度。
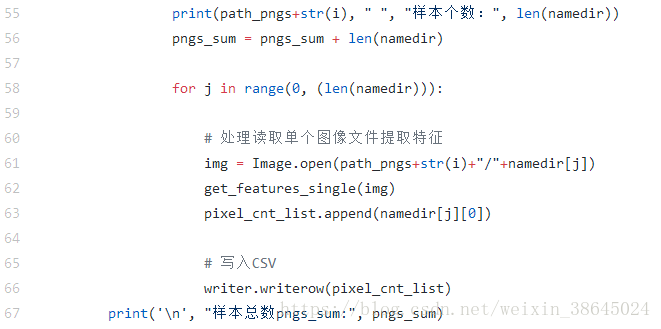
(2)解决方法
修改代码如下,在遍历每个文件夹下的文件的时候,引入sample_nums变量,则在每个文件夹下选择相同的数目的图像建立特征,并且选择数量和sample_nums正相关。
for i in range(1, 10):
namedir = os.listdir(path_pngs+str(i))
# 读到图像文件
if os.path.isdir(path_pngs + str(i)):
print(path_pngs+str(i), " ", "样本个数:", len(namedir))
pngs_sum = pngs_sum + len(namedir)
#for j in range(0, (len(namedir))):
print(sample_nums)
t=sample_nums/10;
k=int(t)
for j in range(0,k):
img = Image.open(path_pngs+str(i)+"/"+namedir[j])
get_feature(img)
# 写入csv
pixel_cnt_list.append(namedir[j][0])
writer.writerow(pixel_cnt_list)
print('\n', "样本总数pngs_sum:", pngs_sum)(3)训练结果
可以发现训练效果和原作者文章基本相同,训练样本在达到1000左右的时候,基本上精确度开始进入稳定哪个阶段。
比较其不同点可以发现LR和MLPC模型精确度有所提高,SGDC模型精确度有所下降,LSVC模型效果基本不变。
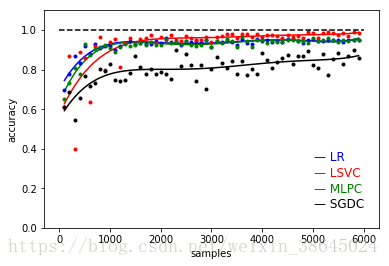
本人训练效果图
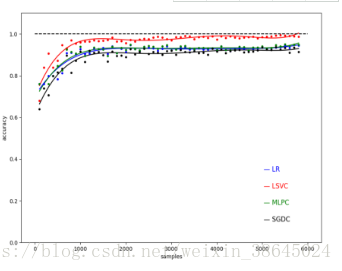
原作者训练精度
(4)原因分析
1. LR,Logistic Regression (线性模型)中的逻辑斯特回归
2. Linear SVC,Support Vector Classification (支持向量机)中的线性支持向量分类
3. MLPC,Multi-Layer Perceptron Classification (神经网络)多层感知机分类
4. SGDC,Stochastic Gradient Descent Classification (线性模型)随机梯度法求解
对于机器学习算法来讲,我们希望算法或者说是训练出来的模型具有较好的泛化能力。其实也就是说要求在同样数据集下训练出来的模型对更广泛的测试(预测)数据都具有较好的预测能力,反过来讲,当算法已经确定的前提下,如果训练用的数据集和测试用的数据集,样本分布更为相似,则训练出来的模型会具有更好的预测能力。
由于样本不平衡,导致样本不是总体样本的无偏估计,从而可能导致我们的模型预测能力下降。原作者的数据进行选取的时候由于是遍历文件夹内的数字,而我们在产生数字的时候每个文件夹内数字并不相同,这就使得在进行模型参数估计的时候,并不合理。代码改进后对特征选取的时候每个数字选取的数量相等,因此进行模型估计的时候,其实每个数字所产生的特征数量是相同的,因此模型效果会更好。
而其中LR,Logistic Regression和MLPC,Multi-Layer Perceptron Classification两种模型进行参数估计的时候,以来的是全局的输入量,也就是说每个输入量都会对模型参数产生影响;反之,Linear SVC模型的思想是产生一个分类的超平面,使得离平面较近的数据点的距平面距离尽量的远,因此整个训练数据的分布对Linear SVC的影响较小,但值得注意的是Linear SVC在进行模型训练的时候一般耗时较长。SGDC,Stochastic Gradient Descent Classification我一直认为是一个算法进行模型求参数的时候的一个方法,不理解这里。
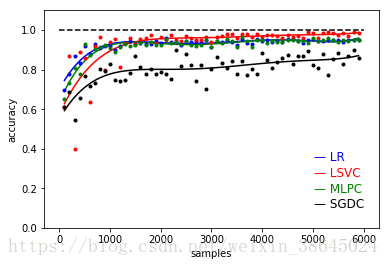
(5)总结
sklearn逻辑回归(Logistic Regression,LR)类库使用小结

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









