




sqoop简介
sqoop是一个数据交换工具,最常用的两个方法是导入导出;导入导出的参照物是hadoop,向hadoop导数据就是导入。
前提条件:必须保证hive、hadoop集群正常启动
安装
上传安装包
[root@localhost usr]# mkdir sqoop
[root@localhost usr]# cd sqoop
[root@localhost sqoop]# sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
解压并配置环境变量
[root@localhost sqoop]# tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
[root@localhost sqoop]#vi /etc/profile
[root@localhost sqoop]#source /etc/profile

修改配置文件
[root@localhost sqoop]# cd /usr/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf
[root@localhost sqoop]# cp sqoop-env-template.sh sqoop-env.sh
[root@localhost sqoop]# vi sqoop-env.sh
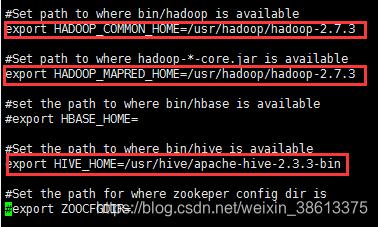
添加架包
将MySQL驱动架包复制到"/usr/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib"
设置MySQL允许远程连接(如果MySQL以前设置过,可以不用再设置)
[root@localhost sqoop]#mysql
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;("root"为进行远程连接的密码,不是登录密码)
mysql> FLUSH PRIVILEGES;(刷新权限)
MySQL与hadoop集群的操作
查询MySQL中的数据库与数据表
[root@localhost lib]# sqoop list-databases --connect jdbc:mysql://192.168.215.157:3306 --username root --password root
[root@localhost lib]# sqoop list-tables --connect jdbc:mysql://192.168.215.157:3306/hive --username root --password root
注:“192.168.215.157"是安装MySQL的虚拟机IP,“root"是进行远程连接的密码,不是登录MySQL的密码,”–username"是指定用户,”–password "是远程连接的密码,"hive"是MySQL中的一个数据库名。
将MySQL中的数据表上传到hadoop集群
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root -table person -m 1;
注:“test “指定MySQL中的数据库名,”-table"指定数据库中的数据表"person”,"-m “指定上传到hadoop集群中,保存的份数(如果数据表中没有主键,必须指定”-m 1"或者"–split-by 字段名",如果有主键,追好也带上);执行完该语句后,数据表会保存在"/user/root/表名"目录下(即使当前没有创建此文件夹,执行该语句后,系统会自动生成);并且使用该语句每个表只能上传一次(因为使用该语句上传的数据表会保存在"/user/root/表名"目录下,当同一个数据表第二次上传时,保存路径与第一次完全一致,在hadoop中不允许这样做)
将MySQL中的数据表中的部分字段上传到hadoop集群
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root -table person --columns 'name,ages' -m 1;
注:"–columns"指定数据表上传的字段," ‘name,ages’“数据表中的字段,字段与字段之间用逗号(”,")隔开。
将MySQL中的数据表多次(删除式)上传到hadoop集群
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root -table person --delete-target-dir -m 1
注:"–delete-target-dir"表示"如果hadoop集群中已经存在了与要上传数据表同名的文件,会先将原文件删除掉,然后再上传"。
将MySQL中的数据表多次(保留式)上传到hadoop集群
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --append -m 1
注:" --append"表示以附加的形式上传文件,保存路径也为"/user/root/表名",此过程不会删除已存在的文件(所以"–append"不能与"–delete-target-dir"同时使用),只是在"/user/root/表名"下添加一个文件(即只有文件的编号不同)
将MySQL中的数据表上传到hadoop集群中指定的目录下
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --target-dir '/sqoop' --fields-terminated-by '\t' -m 1
注:"–target-dir" 指定保存的目录,"/sqoop"文件保存的文件夹,"–fields-terminated-by"指定字段用什么隔开,"\t"表示使用制表符隔开字段(默认情况下,即不写"–fields-terminated-by"参数时,使用逗号","进行隔开)。
将MySQL中的数据表中满足指定条件(简单条件)是数据上传到hadoop集群中
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --where 'ages>13' --target-dir '/sqoop' -m 1 -append
注:"–where" 指定满足的条件,"ages>13"表示具体的条件,他必须使用引号引起了(单引号和双引号都可以)。
将MySQL中的数据表中满足指定条件(复杂条件)是数据上传到hadoop集群中
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --query ‘select * from person where ages > 11 and $CONDITIONS’ --target-dir ‘/sqoop’ -m 1 -append
注:"–query"指定完整的查询语句(貌似sqoop不支持模糊查询(如果使用MySQL语句中的模糊查询,不会报错,但是没有查询结果));并且"–query"不能与"–table"同时使用(因为"完整的查询语句中已经有表名了");并且必须有"and $CONDITIONS"。此外,查询语句必须使用引号引起了,如果使用双引号("")时,“and $CONDITIONS"必须写成这样”$CONDITIONS"。
将MySQL中的数据表(表中含有"null")上传到hadoop集群中
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --target-dir '/sqoop' --fields-terminated-by '\t' -m 1 --null-string "" --null-non-string "false" -append
注:"–null-string"指定处理字符类型的空值," “” “表示字段类型为"String"类型的"null"用空格(”")代替,"–null-non-string"指定处理非字符类型的空值,"false"表示字段类型为非"String"类型的"null"用空格(false)代替。
将MySQL集群中的文件压缩到hadoop中
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --target-dir 'sqoop/td' -m 1 -z -append
注:"‘sqoop/td’“指定将压缩文件上传到HDFS中的路径,但是这个路径有个前缀”/user/root",即压缩文件的真实路径为"/user/root/sqoop/td"," -z"表示以".gz"的格式上传。
将hadoop集群中的文件加载到MySQL中
[root@localhost ~]# sqoop export --connect "jdbc:mysql://192.168.215.157:3306/zoo?useUnicode=true&characterEncoding=utf-8" --username root --password root --export-dir '/sqoop/part-m-00011' --table person -m 1 --fields-terminated-by ','
注:"?useUnicode=true&characterEncoding=utf-8"指定编码格式,如果不指定,导入到MySQL中的数据会出现中文乱码;"–fields-terminated-by ‘,’“指定hadoop文件中各个字段的隔离符号(因为MySQL中数据表的指定分隔符为逗号(”,"),所以只能将hadoop中以逗号","为隔离符的文件导入MySQL中);"person"是MySQL中的数据表,必须提前创建好(表中的字段数据类型必须与文件中的保持一致)。
MySQL与hive集群的操作
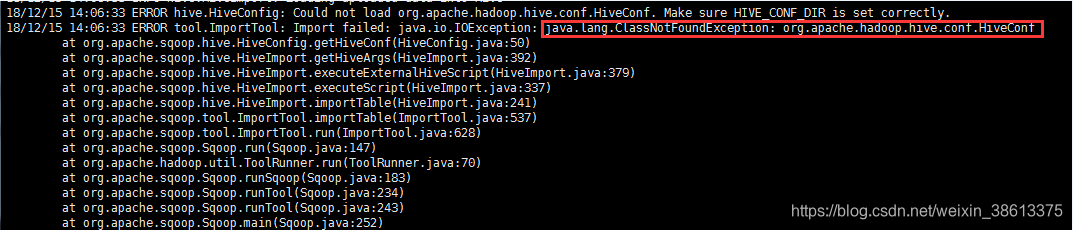
添加架包(将"hive"中的"hive-common-2.3.3.jar"复制到"sqoop"中)
[root@localhost ~]# cd /usr/hive/apache-hive-2.3.3-bin/lib/
[root@localhost lib]# cp hive-common-2.3.3.jar /usr/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib/
如果不添加架包会出现如下错误:
将MySQL中的数据表导入hive的指定的数据库中
将mysql中的数据表导入到hive的普通数据表
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.215.157:3306/test --username root --password root --table person --target-dir '/sqoop2' --hive-import --hive-overwrite --hive-database zoo --hive-table person --fields-terminated-by ',' -m 1
注:“person"是MySQL中的数据表,“person"是hive中的表(名字可以任意起,并且不需要提前创建,在导入的过程中系统会自动创建),”–hive-database"自动将MySQL中的表导入到hive中指定的数据库(如果不写此参数,默认导入hive的默认数据库(default)中),”–hive-overwrite"表示覆盖以前的数据,如果不带此参数,着以追加的形式将数据添加在表单尾部,"–target-dir ‘/sqoop2’ “是一个虚拟的路径,执行该过程并不会创建这样一个目录,他只是一个临时的目录,但是,如果不行这个参数,默认会在”/user/root/表明"创建临时目录(如果"/user/root/“目录下已经存在里与表名相同的文件,系统就会报错,并且该语句不支持”-append"参数,可以使用" --delete-target-dir "参数,但是使用该参数后,会将已经存在的文件(与上传的表同名的文件,执行完后不会会在生成新的,这样做会导致文件丢失))。
将mysql中的数据表导入到hive的分区数据表
[root@localhost ~]# sqoop import --connect jdbc:mysql://192.168.64.130:3306/zoo \
--username root \
--password root \
--table people \
--fields-terminated-by ',' \
--m 1 \
--target-dir /user/hive/warehouse/zoo.db/book/pubid=3 \
--delete-target-dir
hive (zoo)>msck repair table book
注:其中,“pubid=3"是分区字段。此过程可以将mysql中的数据表导入到hive的分区表中,完成批量导入操作,但是分区表的分区此时还处于"亚状态”,所以必须使用"msck repair table book"来修复分区表,使用分区表的状态处于正常状态;否则无法将完成文件内容与分区表的映射。
MySQL中的表导入到hive的实质
将MySQL中的数据导入到hive中其实就是将MySQL中的数据导入到HDFS中(因为hive的所以数据本身就存储在HDFS中("/user/hive/warehouse/数据库名.db/表名"),只不过hive通过映射的方式,将HDFS中的数据映射到hive数据库中,如果将"/user/hive/warehouse/"目录删除掉后,hive中的数据将全部丢失)。
将hive中的数据表导入MySQL的指定的数据库中
hive数据表与mysql数据表的字段数量和数据类型一一对应。
[root@localhost ~]# sqoop export --connect "jdbc:mysql://192.168.215.157:3306/test?useUnicode=true&characterEncoding=utf-8" --username root --password root --table person --export-dir /user/hive/warehouse/zoo.db/person/part-m-00000 --input-fields-terminated-by ','
mysql数据表比hive数据表多一个主键自增字段。
sqoop export \
--connect "jdbc:mysql://192.168.64.130:3306/zoo?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password root \
--table course \
--export-dir /user/hive/warehouse/zoo.db/course \
--input-fields-terminated-by "," \
--null-string '\\N' \
--null-non-string '\\N' \
--columns no,name
其中,“course"是mysql中的数据表,“no,name"是mysql数据表中的字段名。
注:”?useUnicode=true&characterEncoding=utf-8"解决中文乱码;” --export-dir"指定hive导出的路径,"/user/hive/warehouse/zoo.db/person/part-m-00000"hive导出的具体文件,"–input-fields-terminated-by ‘,’“指定从hive中导入到MySQL中文本字段的隔离符,“person"为MySQL中的数据表,此表必须提前创建,创建时,表单字段即各字段类型必须与hive表中的一致,否则无法成功导入。
在导出前,必须确保MySQL中的数据库的编码为"utf-8”,复制会出现” ERROR mapreduce.ExportJobBase: Export job failed!"的错误。

















 5414
5414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









