




 本文详细介绍了一个关于HDFS的应用实例,即通过Java程序模拟产生日志文件,并使用Shell脚本定时将这些日志文件上传至HDFS进行分析。文章包括了Java程序的编写、log4j配置、日志文件的生成、Shell脚本的设计以及日志文件的周期性上传至HDFS的全过程。
本文详细介绍了一个关于HDFS的应用实例,即通过Java程序模拟产生日志文件,并使用Shell脚本定时将这些日志文件上传至HDFS进行分析。文章包括了Java程序的编写、log4j配置、日志文件的生成、Shell脚本的设计以及日志文件的周期性上传至HDFS的全过程。
本文介绍一个关于hdfs的实例,那就是将应用程序产生的日志文件,定时放到hdfs上以便分析
一,我们写一个java程序模拟产生日志的过程
package com.lyz.bigdata.log;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import java.util.Date;
import java.text.SimpleDateFormat;
/**
*@Author:759057893@qq.com Lyz
*@Date: 2019/2/10 15:10
*@Description:
**/
public class GenerateLog {
public static void main(String[] args) throws Exception {
Logger logger = LogManager.getLogger("testlog");
int i =0;
while(true){
logger.info(new Date().toString()+"...I love you....");
i++;
Thread.sleep(500);
if(i>1000000)
break;
}
}
}
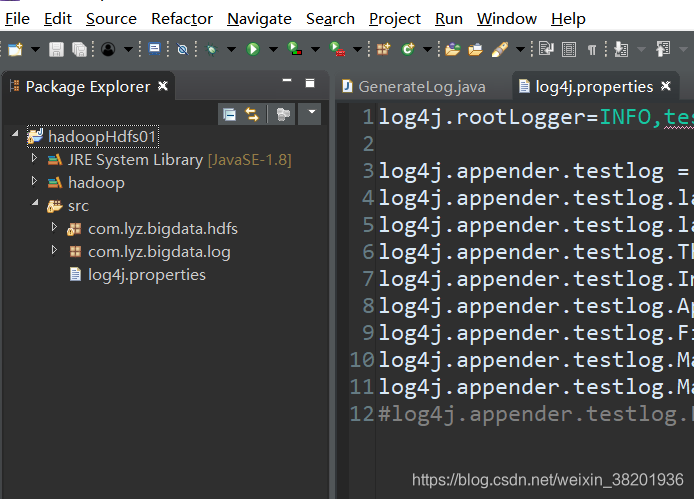
该程序模拟产生日志,程序正常运行需要配置log4j.properties文件,在src/下新建log4j.properties,内容如下:
log4j.rootLogger=INFO,testlog
log4j.appender.testlog = org.apache.log4j.RollingFileAppender
log4j.appender.testlog.layout = org.apache.log4j.PatternLayout
log4j.appender.testlog.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.testlog.Threshold = INFO
log4j.appender.testlog.ImmediateFlush = TRUE
log4j.appender.testlog.Append = TRUE
log4j.appender.testlog.File = /home/hadoop/logs/log/access.log
log4j.appender.testlog.MaxFileSize = 10KB
log4j.appender.testlog.MaxBackupIndex = 20
#log4j.appender.testlog.Encoding = UTF-8
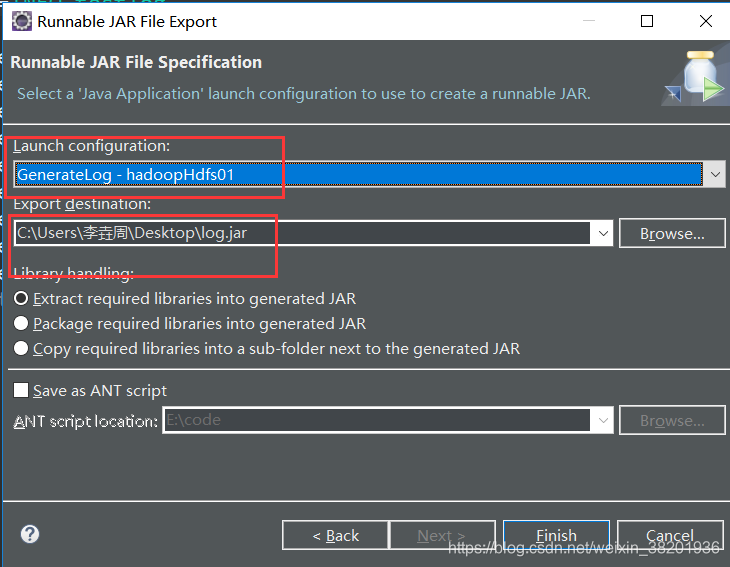
将程序通过eclipse 打包 命名为(log.jar)
打包过程—— 鼠标右键 export ——java ——runable jar file
打包成功后 在虚拟机中创建文件夹
1 hadoop fs -mkdir -p /data/clickLog/20190225/ #日志文件上传到hdfs的根路径
2 mkdir -p /home/hadoop/logs/log/ #日志文件存放的目录
3 mkdir -p /home/hadoop/logs/toupload/ #待上传文件存放的目录

4 将打包成功的 log.jar 放到集群中
1) 先 安装 lrzsz 自动导入安装包 yum install -y lrzsz
2) 拖动 jar 包 进入集群中
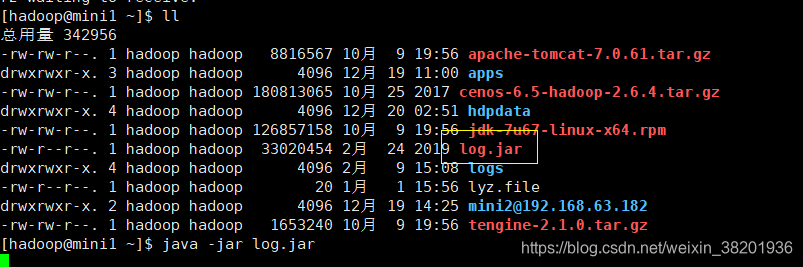
3) 在集群中运行jar 包

二,我们写一个shell脚本,我们把它命名为:upLoadFileToHdfs.sh,脚本定时将产生的日志放到hdfs上面,内容如下:
#!/bin/bash
#set java env
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#版本1的问题:
#虽然上传到Hadoop集群上了,但是原始文件还在。如何处理?
#日志文件的名称都是xxxx.log1,再次上传文件时,因为hdfs上已经存在了,会报错。如何处理?
#如何解决版本1的问题
# 1、先将需要上传的文件移动到待上传目录
# 2、在讲文件移动到待上传目录时,将文件按照一定的格式重名名
# /export/software/hadoop.log1 /export/data/click_log/xxxxx_click_log_{date}
#日志文件存放的目录
log_src_dir=/home/hadoop/logs/log/
#待上传文件存放的目录
log_toupload_dir=/home/hadoop/logs/toupload/
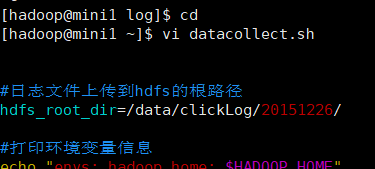
#日志文件上传到hdfs的根路径
hdfs_root_dir=/data/clickLog/20190225/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
创建后,在虚拟机上创建文件
vi datacollect.sh 然后将上面创建的粘贴进去 保存
chmod +x datacollect.sh 对datacollect.sh 加上运行权限

重开一个mini1 的窗口 然后 运行 输入 ./datacollect.sh 运行

运行之后就会将产生的log日志上传到hdfs中。
如果想周期性运行该脚本,可以配置crontab服务,执行crontab -e,加入一行:
*/1 * * * * sh /root/uploadFileToHdfs.sh //该语句表示每1分钟执行一次脚本,更多规则详询百度
保存退出即可实现周期性运行脚本。
至此,模拟将日志文件周期性上传到hdfs就结束了。


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











