



 本文探讨了在使用EasyUI框架时返回JSON数据可能导致的安全隐患及性能问题,并提供了三种解决方案,包括使用Lambda表达式、System.Linq.Dynamic库以及前端动态字段选择。
本文探讨了在使用EasyUI框架时返回JSON数据可能导致的安全隐患及性能问题,并提供了三种解决方案,包括使用Lambda表达式、System.Linq.Dynamic库以及前端动态字段选择。
目录
前言
最近在用EasyUI搭建框架,上周写的一篇文章没想到有这么多人看,呵呵,
看到好多人要我网站的地图插件,http://www.5imvc.com/,本来是想写的,结果本周都在忙框架的事情,明天有时间写写吧
(http://www.cnblogs.com/linfei721/archive/2013/06/02/3114174.html 地图的代码)
回到正题,在搭建框架的时候,无意发现自己的一个坏习惯,返回Json数据时会导致安全问题和性能的损耗,不知道其他人会不会有这习惯,写出来大家讨论下
问题
我在用LINQ返回数据习惯不写Selet(s=>字段),直接返回全部数据,代码:
var json = db.ReportInfo.Take(100);
return Json(json);
这样的代码看起来没什么问题,但是仔细想想却发现了问题,先看看json返回的数据
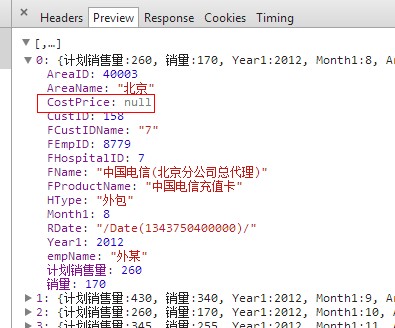
CostPrice 字段为成本价,这字段一般情况下是不让所有人看的,如果是用户表,这样也会把密码泄露出来,不管加密还是没加密,这样都不好
解决办法1:拉姆达表达式
其实这就像我们在写SQL一样,select * from,都知道这个 * 会很影响性能,在MVC中这样会让很多敏感字段暴露出来,代码改成:
var json = db.ReportInfo.Take(100).Select(s => new { AreaName = s.AreaName, FCustIDName = s.FCustIDName, FName = s.FName, FProductName = s.FProductName, HType = s.HType, 销量 = s.销量, 计划销售量 = s.计划销售量, RDate = s.RDate });
return Json(json);
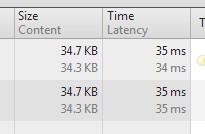
然后在来看看两种写法的性能差异
没写select
改写后
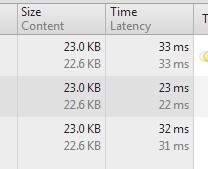
因为我这是测试数据,字段较少,速度这块不是很明显,但是大家可以看看文件大小,如果一个库中字段很多,但是你页面只需要其中几个,这样浪费了很多无用数据
解决办法2:System.Linq.Dynamic
好吧,问题到这里应该完了,但是上面的代码太麻烦,每次都写 AreaName = s.AreaName .......这样的代码,
在网上找了下,终于发现了一个好东西 System.Linq.Dynamic,看名字大家应该知道了,就是动态Linq,这东西Nuget里有,直接去下载
安装完后导入命名空间
using System.Linq.Dynamic;
改成代码:
var json = db.ReportInfo.Take(100).Select("new (AreaName,FCustIDName,FName,FProductName,HType,销量,计划销售量,RDate)"); return Json(json);
解决办法3:System.Linq.Dynamic + 自定义插件
其实在后台限制字段是最安全的,下面介绍个字段过多,解决性能但不安全的方法
在回到界面起,这是EasyUI中datagrid的写法
<table id="list_data" cellspacing="0" cellpadding="0"> <thead> <tr> <th field="AreaName" sortable="true">省区</th> <th field="FName" sortable="true">商业公司</th> <th field="FProductName" sortable="true">产品名称</th> <th field="HType" sortable="true">类型</th> <th field="销量" sortable="true">数量</th> <th field="计划销售量" sortable="true">计划</th> <th field="RDate" sortable="true">销售日期</th> </tr> </thead> </table>
其实可以把这里需要的字段传给后台,这样我们后台就什么代码就不用写了,前台配置什么就返回什么json,自定义一个jQuery的插件,代码如下:
$.fn.extend({
//获取界面字段
fieldSelect: function (attr) {
var str = Array();
if (attr != undefined) {
//循环增加属性值
$(this).each(function (index, e) {
var value = $(this).attr(attr);
//防止重复
if (jQuery.inArray(value, str) == -1)
str.push(value);
});
str = str.join(",");
}
return str;
}
});
这插件的作用就是把th中field属性拼接成字符串,使用方法
var f = $("#list_data tr:eq(0)>th").fieldSelect("field");
//返回结果是AreaName,FCustIDName,FName,FProductName,HType,销量,计划销售量,RDate
$.post("url",{fieldSelect : f},function(data){
.....
});
后台代码:
var json = db.ReportInfo.Take(100).Select(string.Format("new ({0})", Server.UrlDecode(Request.Form["fieldSelect"])));
return Json(json);
好了,这样就是前台配置什么后台就返回什么json的数据,但是注意这里的参数别人是可以伪造的,所以并不安全,但是可以达到缩小传送数据的目的
结束
我也是随便想想,不知道大家有什么想法或我哪里想的不对的欢迎讨论

















 5177
5177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









