




 Apache Flink 是一个用于处理无界和有界数据的流处理框架,擅长流批处理,提供精确的时间控制和状态化。Flink 支持事件时间处理,包括水印和迟到数据处理,以及多种状态管理特性,如 ProcessFunction、DataStream API 和 SQL & Table API。此外,Flink 具有高可用性和故障恢复机制,如检查点和Savepoint,广泛应用于事件驱动应用、数据分析和数据管道。
Apache Flink 是一个用于处理无界和有界数据的流处理框架,擅长流批处理,提供精确的时间控制和状态化。Flink 支持事件时间处理,包括水印和迟到数据处理,以及多种状态管理特性,如 ProcessFunction、DataStream API 和 SQL & Table API。此外,Flink 具有高可用性和故障恢复机制,如检查点和Savepoint,广泛应用于事件驱动应用、数据分析和数据管道。
前言
在目前开源的大数据引擎中,流计算有Flink,Storm,Kafka Stream等,批处理(离线计算)有Spark, MApReduce等。而同时支持流处理和批处理的计算引擎,只有两种选择:一个是Apache Spark,一个是Apache Flink。
从技术,生态等各方面的综合考虑,Spark 的技术理念是基于批来模拟流的计算(我们习惯将之称为批流处理)。而Flink则完全相反,它采用的是基于流计算来模拟批计算(简称为为流批处理)。我们无法片面的说出谁好谁坏,尽管二者都可以应用在流处理和批处理的计算引擎,但正如南国之前提到的二者出发的目的不一样,关于Spark相关的知识分析,南国在之前的博客中有涉及,当然我更建议读者查看Spark的官网。
从这篇博客开始,让我们一起打开Flink的大门,去探索实时计算的宠儿。
基础架构
官网定义:Apache Flink 是一个框架和分布式处理引擎,用于在无边界(unbounded)和有边界(bounded)数据流上进行有状态的计算。这句话提取定义 最重要的关键词就是有状态的流计算。
Flink处理有界和无界数据
数据可以视为无界或者有界来处理:
- 无界流 :有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流 :有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
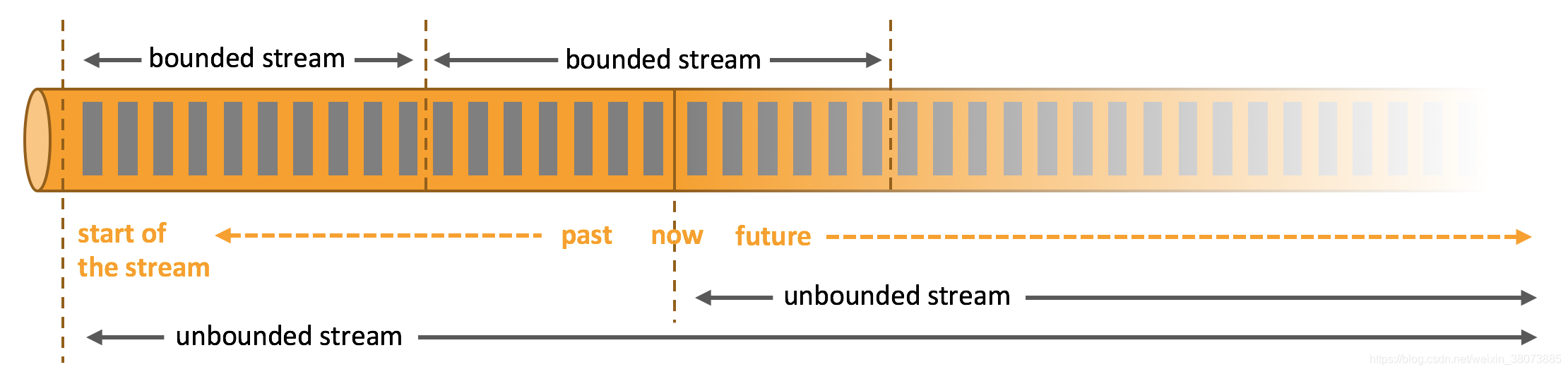
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
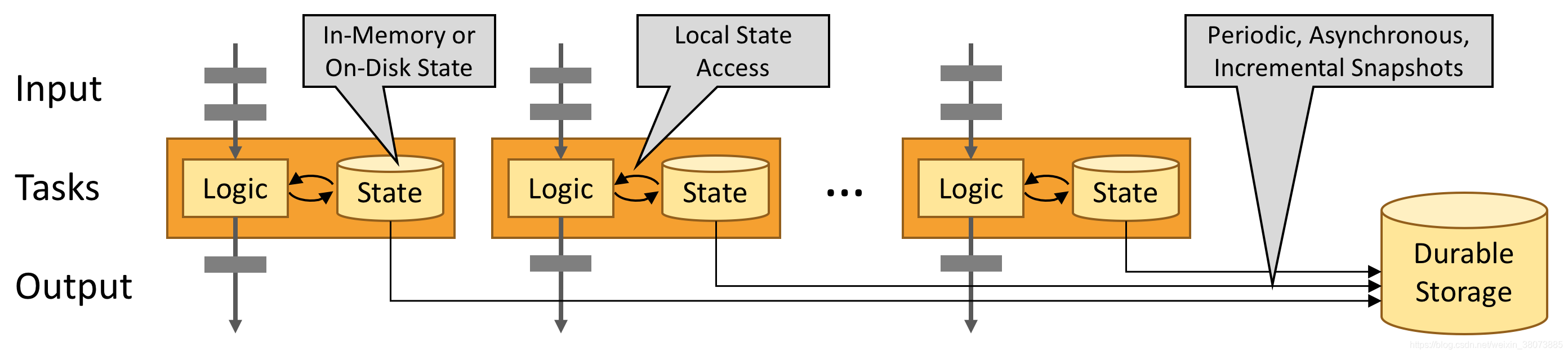
流计算应用的基础组件
这里我们从流(Streams)、状态(state)、时间(time)的支持度来进行阐述。
流 stream
流是流处理的基本元素。它拥有着多种特征。这些特征决定了流如何以及何时被处理。Flink 是一个能够处理任何类型数据流的强大处理框架。
- 有界 和 无界 的数据流:流可以是无界的;也可以是有界的,例如固定大小的数据集。Flink 在无界的数据流处理上拥有诸多功能强大的特性,同时也针对有界的数据流开发了专用的高效算子。
- 实时 和 历史记录 的数据流:所有的数据都是以流的方式产生,但用户通常会使用两种截然不同的方法处理数据。或是在数据生成时进行实时的处理;亦或是先将数据流持久化到存储系统中——例如文件系统或对象存储,然后再进行批处理。Flink 的应用能够同时支持处理实时以及历史记录数据流。
状态 state
每个重要的流应用程序都是有状态的。也就是说,只有在个别事件上应用转换的应用程序不需要状态。任何运行基本业务逻辑的应用程序都需要记住事件或中间结果,以便在稍后的时间点访问它们,例如在接收到下一个事件时或在特定的时间段之后。
所谓状态就是计算过程中产生的中间计算结果,每次计算新的数据进入到流式系统中都是基于中间状态结果的基础上进行运算,最终产生正确的统计结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









