






 本文详细介绍了循环神经网络(RNN)、长短期记忆网络(LSTM)及门控循环单元(GRU)的基本概念、结构原理及其在序列数据处理中的应用。通过对这些模型的深入解析,帮助读者理解其在解决梯度消失和梯度爆炸问题上的优势。
本文详细介绍了循环神经网络(RNN)、长短期记忆网络(LSTM)及门控循环单元(GRU)的基本概念、结构原理及其在序列数据处理中的应用。通过对这些模型的深入解析,帮助读者理解其在解决梯度消失和梯度爆炸问题上的优势。
RNN 、LSTM、GRU
@(RNN | LSTM | GRU)
0.RNN(Recurrent Neural Networks 循环神经网络)
RNN是一种用于处理序列数据的神经网络。相比一般的神经网络来说,它能处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JuQ7Gf8h-1614754032578)(./1610594866096.png)]](https://i-blog.csdnimg.cn/blog_migrate/08ab06d461b5bc48c67fd247c9230e16.png)
这里:
x 为当前状态下数据的输入, h表示接收到的上一个节点的输入。
y 为当前节点状态下的输出,而 h’为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h’ 与 x 和 h 的值都相关。
而 y 则常常使用 h’ 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的y如何通过 h’ 计算得到往往看具体模型的使用方式。
通过序列形式的输入,我们能够得到如下形式的RNN。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2UI8tuyS-1614754032584)(./1610595290583.png)]](https://i-blog.csdnimg.cn/blog_migrate/ea42cc6342bc7bd223f835c15f85dd50.png)
1.LSTM
什么是LSTM?
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
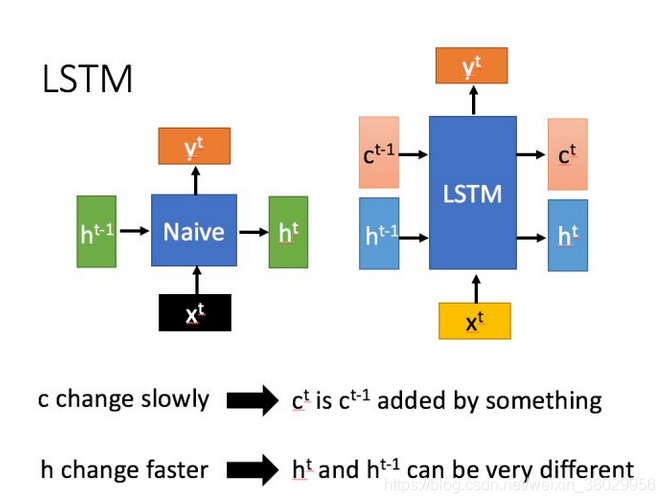
相比RNN只有一个传递状态h^t,LSTM有两个传输状态,一个 c^t (cell state),和一个 h^t(hidden state)。(Tips:RNN中的h^t 对于LSTM中的 c^t)
其中对于传递下去的 c^t 改变得很慢,通常输出的c^t 是上一个状态传过来的 c^(t-1) 加上一些数值。
而 h^t 则在不同节点下往往会有很大的区别。
深入LSTM结构
下面具体对LSTM的内部结构来进行剖析。
首先使用LSTM的当前输入 x^t 和上一个状态传递下来的 h^(t-1) 拼接训练得到四个状态。
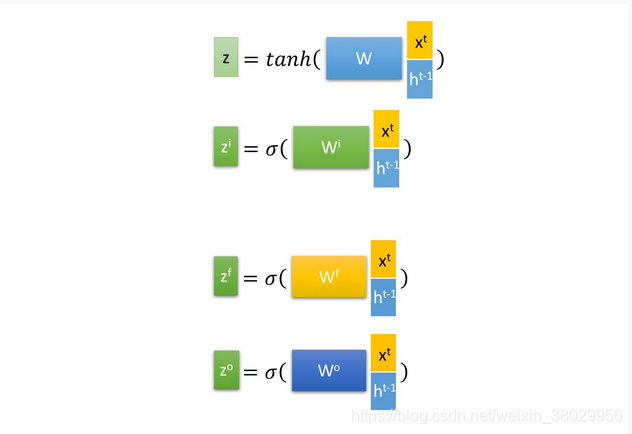
其中, z^f, zi,zo是由拼接向量乘以权重矩阵之后,再通过一个 sigmoid 激活函数转换成0到1之间的数值,来作为一种门控状态。而 z 则是将结果通过一个 tanh 激活函数将转换成-1到1之间的值(这里使用 tanh 是因为这里是将其做为输入数据,而不是门控信号)。
下面开始进一步介绍这四个状态在LSTM内部的使用。(敲黑板)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HTcp5EW8-1614754032601)(./1610596140291.png)]](https://i-blog.csdnimg.cn/blog_migrate/5f397e0d4653ff4620e51ec45b670d02.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GQ7JhG6R-1614754032608)(./1610602851663.png)]](https://i-blog.csdnimg.cn/blog_migrate/9edc45ebd1f1f75d1b162e24139b8fc5.png) 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。
是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1GD2i1jJ-1614754032614)(./1610602877988.png)]](https://i-blog.csdnimg.cn/blog_migrate/8c6095f6955a377ffd8b3cc83d4fc308.png)
则代表进行矩阵加法。
核心思想
LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XseT8Q9g-1614754032624)(./1610688110782.png)]](https://i-blog.csdnimg.cn/blog_migrate/338609f0848d11b74d2999b3f51b4092.png)
下一步是确定什么样的新信息被存放在细胞状态中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xO2FRBp4-1614754032628)(./1610688128244.png)]](https://i-blog.csdnimg.cn/blog_migrate/f7ae2bbf6edde49370e362589d74fbd0.png)
我们把旧状态与 ft 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 it∗C~t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WpuCebCy-1614754032636)(./1610688144131.png)]](https://i-blog.csdnimg.cn/blog_migrate/c1d35aa93df5fe4176068145a0cc99df.png)
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PmVERSU0-1614754032645)(./1610688169110.png)]](https://i-blog.csdnimg.cn/blog_migrate/86ce6dcf287ddb422cc32f2b3cd83018.png)
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。
图中最上面的一条线的状态即 s(t) 代表了长时记忆,而下面的 h(t)则代表了工作记忆或短时记忆。
#####LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的zf(f表示forget)来作为忘记门控,来控制上一个状态的xt 哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 x^t 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的z 表示。而选择的门控信号则是由 z^i(i代表information)来进行控制。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过z^0 来进行控制的。并且还对上一阶段得到的 c^o进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 yt往往最终也是通过ht 变化得到。
将上面两步得到的结果相加,即可得到传输给下一个状态的 c^t 。也就是上图中的第一个公式。
GRU
GRU 可以看作是LSTM的一种变种。(Gated Recurrent Unit)GRU可以把LSTM中的遗忘门和输入们用更新们来替代。
把遗忘Ht和输入门Ct进行合并,在计算当前时刻更新信息的方法和LSTM差不多。但是参数少了1/3,不容易过拟合。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u6H2NVCa-1614754032651)(./1610681877750.png)]](https://i-blog.csdnimg.cn/blog_migrate/3bbdaa1c21df8342f429170f795e6887.png)
####接下来我们把以上的图分解并计算出它们**
1、计算出重置门:Rt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vaa0UlKj-1614754032656)(./1610681966128.png)]](https://i-blog.csdnimg.cn/blog_migrate/c581c9e13878ac6d322ce1aa413072f3.png)
我们先计算出重置门Rt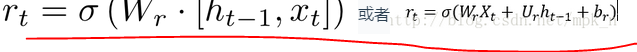
即可
2、计算出更新门:Zt
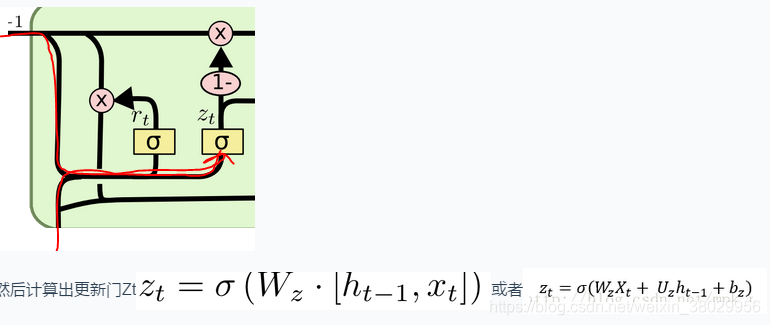
3、计算出候选记忆单元:~Ht
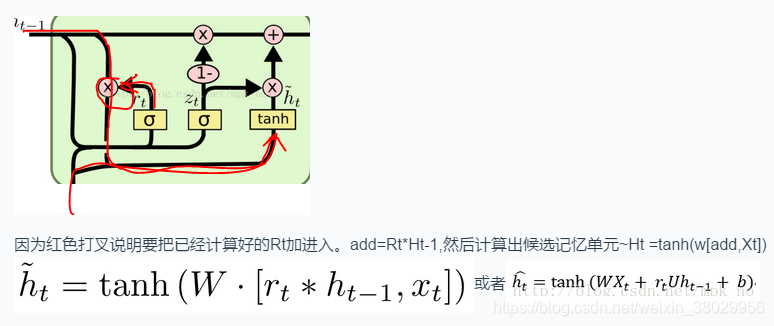
3、计算出当前时刻记忆单元:Ht
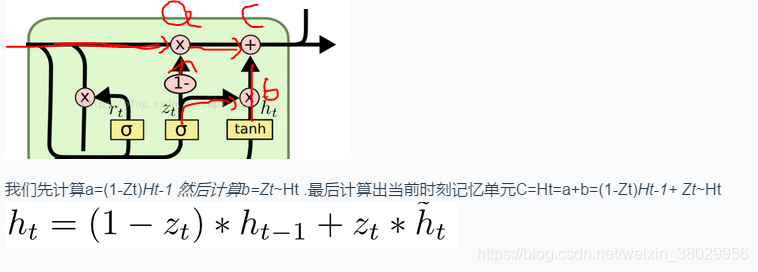

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









