






 Facebook团队提出TensorMask,一种用于密集对象实例分割的新方法。该方法采用4D张量表示,克服了传统方法的局限,实现了与Mask R-CNN相当的分割效果。
Facebook团队提出TensorMask,一种用于密集对象实例分割的新方法。该方法采用4D张量表示,克服了传统方法的局限,实现了与Mask R-CNN相当的分割效果。
TensorMask: A Foundation for Dense Object Segmentation
这一次,Facebook的陈鑫磊、何恺明等人,又从全新的角度,再次解决了实例分割任务中的难题:
他们提出一种通用的实例分割框架TensorMask,弥补了密集滑动窗口实例分割的短板。
在COCO数据集上进行测试实例分割结果可以发现,TensorMask的效果可以比肩Mask R-CNN。
消息来源(量子位):何恺明、陈鑫磊最新研究:提出实例分割新方法TensorMask,效果比肩Mask R-CNN
Abstract
滑动窗口对象检测器(Sliding-window object detectors)在密集、规则的网格上生成边界框对象预测,这种方法得到了迅速的发展,并得到了广泛的应用。相比之下,现代实例分割方法主要由这样的方法控制,它首先检测对象的边界框(bounding boxed),然后裁剪和分割这些区域,就像Mask R-CNN所普及的那样。在这项工作中,我们研究了密集滑动窗口实例分割(dense sliding-window instance segmentation)的范例,这是一个令人惊讶的研究。我们的核心观察是,该任务与其他密集预测任务(如语义分割semantic segmentation或边界对象检测bounding-box object detection)在本质上是不同的,因为每个空间位置的输出本身就是一个几何结构,具有自己的空间维度。为了将其形式化,我们将密集实例分割作为一个超过4D张量的预测任务,并提出了一个名为TensorMask的通用框架,该框架显式地捕获了这个几何图形,并在4D张量上生成了新的运算符。我们证明tensor view在baselines上获得了很大的增益,可以解释这种结构,其结果可以与Mask R-CNN相媲美。这些有希望的结果表明,TensorMask可以作为dense mask预测的新进展和更全面地理解任务的基础。代码不久后会开源。
1. Introduction
滑动窗口范例sliding-window paradigm通过在每个窗口上放置一组密集的图像定位寻找目标objects,这是计算机视觉中最早也是最成功的概念之一[37,39,9,10],它自然地与卷积网络[20]相连接。然而,虽然今天的最好的目标检测表示是通过滑动窗口预估来生成初始候选区域,并对这些候选区域进行细化处理,得到更准确的预测,如Faster R-CNN[34]和Mask R-CNN[17]分别用于跳框对象检测和实例分割。这类方法已经主导了COCO detection challenges[24]。
- [34]S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
- [17] K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask R-CNN. In ICCV, 2017.
近年来,bounding-box object detectors避开了细化步骤,专注于直接使用sliding-window预测,以SSD[27]和RetinaNet[23]为例,已经见证了复苏,并显示了有希望的结果。相比之下,该领域在密集滑动窗口实例分割方面并没有取得同等的进展;对于Mask预测,没有类似于SSD / RetinaNet的直接、密集的方法。为什么密集的方法在框检测方面蓬勃发展,而在实例分割方面却完全缺失?这是一个具有根本科学意义的问题。The goal of this work is to bridge this gap and provide a foundation for exploring dense instance segmentation.
我们的主要观点是,定义dense mask representations的核心概念,以及这些概念在神经网络中的有效实现,这些都是缺乏的。与边界框不同的是,边界框具有固定的低维表示,而不考虑比例,segmentation masks可以从更丰富、更结构化的表示中获益。例如,每个mask本身是一个2D空间映射,较大对象的mask可以从较大空间映射的使用中获益。为dense masks开发有效的表示是实现密集实例分割dense instance segmentation的关键一步。
为了解决这个问题,我们定义了一组用高维张量表示Mask的核心概念,这些概念允许探索用于densemask预测的新型网络体系结构。为了证明该方法表征的优越性,我们对几种网络进行了实验研究。我们的框架,称为TensorMask,建立了第一个密集的滑动窗口实例分割系统,其结果接近于Mask R-CNN。
TensorMask表示的核心思想是使用结构化的4D张量表示空间域上的Mask。这一观点与之前的工作形成了对比,之前的工作是对与类无关的对象建议进行分段,比如使用非结构化3D张量的DeepMask[31]和InstanceFCN[7],其中Mask被打包到第三通道轴中。通道轴与表示对象位置的轴不同,它没有明确的几何意义,因此很难操作。通过使用基本的通道表示,我们失去了使用结构数组将Mask表示为2D实体(类似于MLPs[35]和ConvNets[20]用于表示2D图像的区别)的机会。
与这些面向通道的方法不同,我们建议利用四维形状张量(V, U, H, W ),其中,(H, W)表示目标位置,(V, U)表示相对Mask位置,这两者是几何子张量,即,它们的轴有明确的单位和几何意义w.r.t.图像。这种从非结构化通道轴上的编码Mask到使用结构化几何子张量的视角转变,使得定义新的操作和网络体系结构成为可能。这些网络可以直接在(V, U)具有几何意义的子张量,包括坐标变换、上/下标度和尺度金字塔的使用。
在TensorMask框架的支持下,我们在一个四维张量的标度索引列表上建立了一个金字塔结构,我们称之为张量双金字塔。与特征金字塔类似,特征金字塔是一个多尺度的特征映射列表,张量双金字塔包含一个包含形状的4D张量列表 ,
。这个结构一一个金字塔形的几何子张量(H, W)和(V, U),但是朝着相反的方向发展。这种自然的设计捕捉了大物体具有高分辨率masks的理想特性,其大致空间定位(大k)和小对象具有低分辨率masks和精细空间定位(小k)。
我们将这些组件结合成一个网络主干和训练程序,紧跟着RetinaNet[23],其中我们的dense mask预测器扩展了原始的dense bounding box预测器。通过详细的实验,我们评估了TensorMask框架的有效性,并说明了明确捕捉该任务的几何结构的重要性。最后,我们展示了TensorMask与对应的Mask R-CNN产生了相似的结果(见图1和图2)。


2. Related Work
Classify mask proposals. 现代实例分割任务是由Hariharan等人[15]引入的(在COCO[24]普及之前)。在他们的工作中,针对这项任务提出的方法包括首先生成object mask proposals[38,1],然后将这些proposals分类为[15]。在早期的工作中,classify-mask-proposals方法用于其他任务。例如,Selective Search[38]和原始的R-CNN[12]分类mask proposals,获得box detections和语义分割结果;这些方法可以方便地应用于实例分割。这些早期的方法依赖于前深度学习时代方法计算的自下而上的mask proposals[38,1];我们的工作与由DeepMask[31]首创的用于mask object proposals的密集滑动窗口dense sliding-window方法更为密切相关。我们将很快讨论这种联系。
Detect then segment.现在主流的实例分割范式包括首先用一个框检测对象,然后使用框作为向导对每个对象进行分割[8,40,21,17]。也许最成功的检测然后分段方法的实例是Mask R-CNN[17],它扩展了更快的R-CNN[34]检测器与一个简单的Mask预测器。基于Mask R-CNN的方法[26,30,4]主导了最近挑战的排行榜[24,29,6]。与在bounding-box预测不同的是,在滑动窗方法[27,33,23]和基于区域的方法region based[11,34]都蓬勃发展的地方,在实例分割领域,对密集滑动窗方法的研究一直缺乏。我们的工作旨在缩小这一差距。
Label pixels then cluster.第三类实例分割方法(例如,[3,19,2,25])建立在为语义分割开发的模型之上[28,5]。这些方法用一个类别和一些辅助信息来标记每个图像像素,集群算法可以使用这些辅助信息将像素分组到对象实例中。这些方法得益于语义分割的改进和对较大对象的高分辨率Mask的原生预测。与detect-then-segment方法相比,label-pixels-then-cluster方法在流行基准上的精度落后[24,29,6]。TensorMask没有使用全卷积模型来进行密集像素标记,而是探索了构建全卷积模型的框架(即,密集滑动窗)用于Dense Mask预测的模型,其中每个空间位置的输出本身就是二维空间地图 。
Dense sliding window methods.据我们所知,目前还没有用于密集滑动窗口实例分割的方法。提出的TensorMask框架是第一个这样的方法。最接近的方法是与类无关的Mask proposal生成相关的任务,特别是像DeepMask[31, 32]和InstanceFCN[7]这样的模型,它们应用卷积神经网络以密集的滑动窗口方式生成mask proposals。与这些方法类似,TensorMask也是一个密集的滑动窗口模型,但它跨越了一个更具表现力的设计空间。DeepMask和InstanceFCN可以自然地表示为与类无关的TensorMask模型,但是TensorMask支持性能更好的新架构。此外,与这些类无关的方法不同,TensorMask在mask预测的同时执行多类分类,因此可以应用于实例分割任务。
3. Tensor Representations for Masks
TensorMask框架的核心思想是使用结构化的高维张量来表示一组密集滑动窗口中的图像内容(例如Mask)。
考虑在宽度W和高度h的特征图上的V x U大小的窗口滑动,可以用一个形状(C, H, W),其中每个Mask由 C=V·U 像素参数化。这是在DeepMask[31]中使用的表示。
然而,这种表示的基本精神实际上是一个具有形状(V, U, H, W)。子向量 (V, U)表示Mask为二维空间实体。tensor不是将通道维C看作是一个黑盒,其中有一个V x U Mask,而是支持表示密dense mask的几个重要概念,下面将讨论这些概念。
3.1. Unit of Length
在我们的框架中,每个空间轴的长度单位(或简单的单位)是理解4D张量的必要概念。直观地说,轴的单位定义了沿轴的一个像素的长度。不同的轴可以有不同的单位。
H和W轴的单位,像表示,可以设置为stride w.r.t.输入图像(res4 of ResNet-50 [18] ,
)。类似地,V和U轴定义另一个2D空间域和有自己的单位,像
表示。沿着V或U轴移动一个像素对应于转移
输入图像像素。单位
并不等于单位
,我们的模型会从中受益。
定义是必要的,因为如果没有指定单位,张量形状(V; U; H; W )是模糊的。例如,(V; U)代表一个V x U的窗口在图像像素,如果图像像素 ,但是2V x 2U窗口如果图像像素
。单位以及它们如何由于向上/向下缩放操作而变化是多尺度表示的核心(3.6中有更多相关信息)。
3.2. Natural Representation
通过单位的定义,我们可以形式化地描述一个(V; U; H; W )张量。在我们最简单的定义中,这个张量表示窗口在(H;W)。我们称之为自然表示。表示作为单位的比例,正式我形式们有:
![]() ,式中'x'为笛卡尔积。从概念上讲,张量可以看作是这个域中的一个连续函数。为了实现这一目标,我们必须将4D张量作为一个在采样点上定义的离散函数进行栅格化。我们假设采样率为每单位一个样本,样本位于整数坐标(例如,如果U=3,则
,式中'x'为笛卡尔积。从概念上讲,张量可以看作是这个域中的一个连续函数。为了实现这一目标,我们必须将4D张量作为一个在采样点上定义的离散函数进行栅格化。我们假设采样率为每单位一个样本,样本位于整数坐标(例如,如果U=3,则)。这种假设允许相同的值U代表两轴的长度的单位(例如,
)和同样数量的离散样本存储的轴。这对于处理离散长度的神经网络产生的张量是很方便的。
图3(左)展示了一个例子,当V = U = 3和等于1。自然表示是直观的,并且很容易解析为网络的输出,但是它并不是深层网络中惟一可能的表示,下面将对此进行讨论。
3.3. Aligned Representation
在自然表示中,一个子张量(V, U)位于(y, x),代表值在抵消像素点而不是直接在(y, x);当使用卷积来计算特征时,保持输入像素和预测输出像素之间的像素对像素对齐可以带来改进(这与RoIAlign[17]的动机类似)。接下来,我们描述了张量视角下dense mask的像素对齐表示。形式上,我们将对齐表示定义为

为对齐表示中的单位比。
这里是子张量在像素
总是描述在这个像素处取的值,即它是对齐的。子空间
不表示单个mask,而是枚举所有重叠像素的
,窗口中的mask值
。图3(右)展示了一个例子,当
(9个重叠窗口)和
是1。
注意,我们在对齐的表示中表示张量为(坐标/单位也是一样)这是在命名张量[36]的精神和证明是有用的。
我们的对齐表示与InstanceFCN[7]中提出的instancesensitive score映射有关。我们证明(在A.2中)这些分数映射的行为类似于我们的对齐表示,但是在,这使得它们没有对齐。实验结果表明,该方法具有较好的效果。
3.4. Coordinate Transformation
我们引入了自然表示和对齐表示之间的坐标转换,因此它们可以在单个网络中互换使用。这使我们在设计新颖的网络体系结构时具有额外的灵活性。
为了简单起见,我们假设这两种表示中的单位是相同的: 和
,因此
(对于更一般的情况下见a . 1)。比较自然表示与对齐表示的定义,我们得到了x的以下两个关系u, x:
,
。
,求解这个方程
和
给:
和
。同样的结果也适用于y;那么从对齐表示法(
)到自然表示法(
)的变换是
![]()
我们称这个变换为align2nat。同样地,解出x和u的这组关系,就得到了nat2align的逆变换:![]() 。
。
虽然本文中展示的所有模型都只使用了align2nat,但是为了完整起见,我们给出了这两种情况。
没有限制,这些转换可能涉及非整数坐标索引一个张量,例如如果
不是整数。因为我们只允许整数坐标在我们的实现中,我们采用一个简单的策略:当op align2nat,我们确保α是一个正整数。我们可以满足这个约束在α改变单位/缩小操作,所述下一个。
3.5. Upscaling Transformation
所述对齐表示允许使用coarse子张量,生成更细的(V, U)子张量,这很有用。图4演示了这个转换,我们调用align2nat,然后进行描述。
上行align2nat操作接受一个作为输入的张量。
比期望输出值λ粗(所以它的单位是λ大)。它在
域λ,减少底层单元λ。接下来,align2nat op将输出转换为自然表示。完整的align2nat操作如图4所示。

正如我们的实验所证明的那样,up align2nat op可以有效地生成高分辨率mask,而不需要在之前的feature map中膨胀通道计数。这进而支持新的体系结构,如下所述。
3.6. Tensor Bipyramid
在multi-scale box检测中,通常使用低分辨率的feature map来提取较大尺度的对象[10,22],这是因为在低分辨率的map上,固定大小的滑动窗口对应于输入图像中的较大区域。这也适用于multi-scale mask检测。然而,与一个无论大小都由四个数字表示的盒子不同,mask的像素大小必须随对象大小进行缩放,以保持恒定的分辨率密度。因此,我们不总是使用V x U单位来表示不同尺度的mask,而是根据尺度来调整mask像素的数量。
考虑自然表示(V;U;H;W)在最精细级别的feature map上。在这里,(H;W)区域分辨率最高(最小单位)。我们期望这一层处理最小的对象,因此(V;U)域分辨率最低。据此,我们构建了一个金字塔,金字塔逐渐减小(H;W)和增加(V;U),形式上,我们把张量双锥定义为
因为单位是相同的在所有的水平,一个
mask有
个输入图像的像素。在(H, W)领域,因为单位
和k,增加的数量预测mask减少对于较大的mask,。注意,每层的总尺寸是相同的(为V·U·H·W)。tensor双金字塔可以使用swap_align2nat操作来构造,下面将进行描述。
然后对(H;W)进行子采样,得到最终形状。up_align2nat和subsample的组合,如图5所示,称为swap align2nat:交换这个op之前和之后的单元。为了提高效率,不需要计算形状(2kV)的中间张量;2谷;H;W)向上对齐2nat,这是禁止的。这是因为在这个中间张量中,只有一小部分值出现在子采样后的最终输出中。因此,虽然图5显示了概念计算,但在实际中,我们将swap align2nat实现为一个单独的op,该op只执行必要的计算,且复杂度O(V·U·H·W)与k无关。

4. TensorMask Architecture
现在,我们展示了由TensorMask表示启用的模型。这些模型有一个在滑动窗口中生成mask的mask预测头和一个用于预测对象类别的分类头,类似于滑动窗口对象检测器中的box 回归和分类的head[27,23]。Box预测对于TensorMask模型来说是不必要的,但是可以很容易地包括进去。
4.1. Mask Prediction Heads
我们的mask预测分支连接到卷积主干上。我们使用FPN[22]生成一个具有大小![]() ,每层k有固定数量的通道C,这些映射用作每个预测头的输入: mask、类和框。头部的重量在不同级别之间共享,而不是在任务之间共享。
,每层k有固定数量的通道C,这些映射用作每个预测头的输入: mask、类和框。头部的重量在不同级别之间共享,而不是在任务之间共享。
Output representation.我们总是使用自然表示(3.2)作为网络的输出格式。任何表示(自然的、对齐的等等)都可以在中间层中使用,但是它将被转换为输出的自然表示。这种标准化将损失定义从网络设计中解耦出来,使得使用不同的表示更加简单。此外,我们的mask输出是与类无关的。该窗口总是预测一个mask,而不考虑类;通过分类头预测mask的类别。与类无关的mask预测避免了将输出大小乘以类的数量。
Baseline heads.我们考虑一组四个baseline head,如图6所示。每个头部接受一个形状的输入特征图(C;H;W)对于任何(H;W)。然后,它应用一个具有适当数量输出通道的11个卷积层(带有ReLU),这样将其重新构造为一个4D张量就可以生成下一层所需的形状,表示为conv整形。图6a和6b是使用自然对齐表示的简单头部。在这两种情况下,我们为1x1conv使用V·U个输出通道,后一种情况下使用align2nat。图6c和图6d分别是使用自然表示法和对齐表示法的缩放头。他们的输出通道1 1 conv 少于在简单的正面。
在baseline TensorMask模型中,这四个头中的一个被选中并连接到所有的FPN水平。输出形成一个金字塔![]() 。参见图7。对于每一个head,输出滑动窗口总是相同的单元特性映射它幻灯片:
。参见图7。对于每一个head,输出滑动窗口总是相同的单元特性映射它幻灯片:水平。

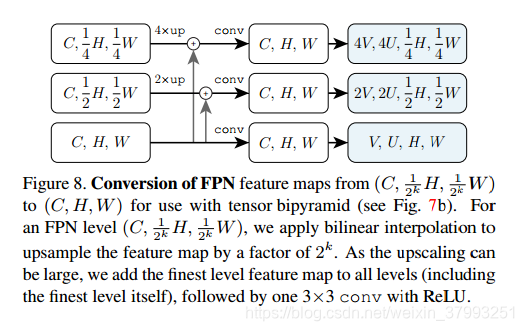
Tensor bipyramid head.与baseline heads不同,tensor bipyramid head(3.6)接受精细分辨率特征图(H, W)所有级别。图8显示了对FPN的微小修改以获得这些映射。对于每一个产生的层次,现在全部(C, H, W),我们首先使用conv+reshape生成合适的4D张量,然后使用swap align2nat运行mask prediction head,如图7b所示。张量双锥模型是本文研究的最有效的张量mask形式。
4.2. Training
Label assignment.我们使用DeepMask分配规则[31]的一个版本来标记每个窗口。一个满足三个条件的窗口w.r.t.一个ground-truth mask m是正的:
(i)包容:该窗口完全包含m,且m的较长边(以图像像素为单位)至少是较窗口长边的1/2, ![]() 。
。
(ii)中心:m的边界框的中心是在一个单位(σVU)窗口中心的L2距离。
(iii)唯一性:没有其他Mask 满足其他两个条件。
如果m满足这三个条件,则将窗口标记为正例,其ground-truth mask、object category和box由m给出。否则,将窗口标记为负例。
与基于IoU的滑动窗口检测器(如RPN[34]、SSD[27]、RetinaNet[23])中box的分配规则不同,我们的规则是mask驱动的。实验表明,我们的规则可以很好地工作,即使只使用1或2个窗口大小,一个高宽比为1:1,与之相比,例如,RetinaNet’s 9的多尺度和高宽比。
Loss.对于mask prediction head,采用逐像素二值分类的方法。在我们的设置中,滑动窗口内的ground-truth mask通常具有较大的空白,导致前景和背景像素之间的不平衡。因此使用二叉叉,而是我们使用焦损失[23]解决不平衡,特别是我们用FL与γ= 2和α= 1:5。窗口的mask损失在窗口中的像素上取平均值(注意,在张量双金字塔中,窗口大小随级别而变化),mask总损失在所有正窗口上取平均值(负窗口不会导致mask损失)。的分类,我们又采用与![]() 和
和![]() 。对于box回归,我们使用无参数1损失。总损失是所有任务损失的加权和。
。对于box回归,我们使用无参数1损失。总损失是所有任务损失的加权和。
Implementation details.我们的FPN实现紧跟[23];每个FPN级由4个带有ReLU的C通道的33个conv层输出(而不是原来的FPN[22]中的一个conv)。与头部一样,重量在不同级别之间共享,但不是在任务之间。此外,我们发现FPN中自上而下和横向连接的平均(而不是对[22]求和)提高了训练的稳定性。我们 使用FPN级别2到7 (k=0, ... ,5)mask和盒分支中的四个conv层用C=128通道,分类分支用C=256(与RetinaNet[23]相同)。除非注明,我们使用ResNet-50[18]。
对于训练,所有模型都是从ImageNet预训练权重初始化的。我们使用尺度抖动,其中较短的图像边是从[640,800]像素[16]随机采样。遵循SSD[27]和YOLO[33],它们训练模型的时间(∼65和160个epoch)比[23,17]长,我们采用“6×”调度[16](∼72 epoch),这改进了结果。小批量大小是16个图像在8个gpu。基础学习率为0.02,迭代1k的线性热身[14]。其他超参数保持与[13]相同。
4.3. Inference
推理类似于密集的滑动窗口对象检测器。对于较短的图像,我们使用800像素的单一比例尺。我们的模型为每个滑动窗口输出一个mask预测、一个类得分和一个预测框。非最大抑制(NMS)应用于在回归框上使用框IoU的得分最高的预测,遵循[22]中的设置。为了在原始图像分辨率下将预测的soft mask转换为二进制mask,我们使用了与Mask R-CNN[17]相同的方法和超参数。
5. Experiments
我们报告了COCO实例分割[24]的结果。所有的模型都是按照∼118k train2017的图片进行训练的,并在5k val2017图像上进行了测试。最终结果在test-dev上。我们使用COCO Mask的平均精度(用AP表示)。当报告框AP时,我们将其表示为APbb。
5.1. TensorMask Representations
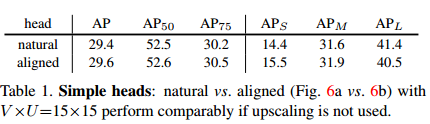
首先,我们研究了使用V =U=15和ResNet-50-FPN骨干的Mask的各种张量表示。我们在表2中报告了定量结果,并在图2和图9中进行了定性比较。

Simple heads.表1比较了自然表示法与简单头对齐表示法(图6a与图6b)。这两种表示法表现相似,边缘间隙为0.2 AP。简单的自然头部可以被认为是深度掩模[31]的一个类特定变体,具有FPN主干[22]和焦损失[23]。由于我们的目标是使用低分辨率的中间表示,接下来我们将研究向上伸缩的头部。
Upscaling heads.表2a比较了自然表示法与向上缩放头对齐表示法(图6c与图6d)。输出大小固定在V x U =15 x 15。给定一个升级因子λ,图6中的conv中 VU通道,例如,9通道 λ= 5(如果没有升级)和225个通道。准确率的差异大大型λ:一致变异提高自然头上AP + 15.6(115%)当λ= 5。图9a(自然)与图9c(对齐)显示了明显的视觉差异。高档对齐头仍然产生急剧大λ的面具。这张量双锥体是至关重要的,我们有一个输出
![]() ,这是实现大升级系数
,这是实现大升级系数![]() (例如,32);见图5
(例如,32);见图5
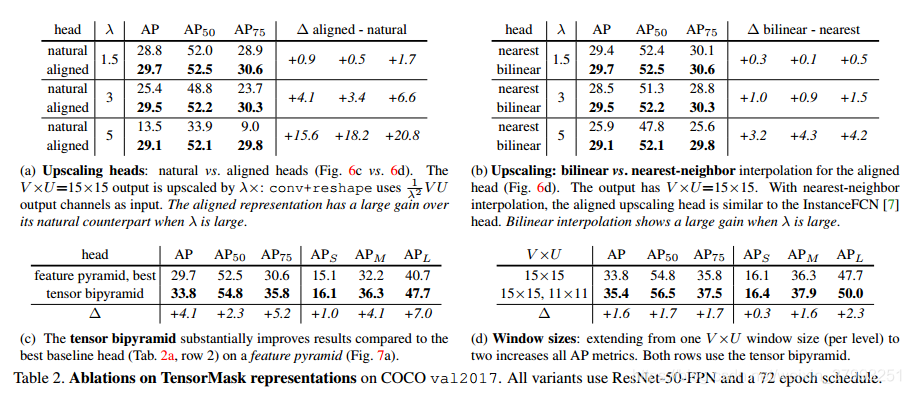
Interpolation.我们观察在选项卡。2 b在近邻插值,双线性插值收益率固体改进尤其是λ很大(∆美联社= 3.2)。当物体重叠时,这些插值方法会导致明显的视觉差异:参见图9b(未对齐)与图9c(对齐)。
Tensor bipyramid.用张量双金字塔模型替换最佳特征金字塔模型,得到4.1 AP的较大改进(表2c)。在这里,掩码大小是vu =15 15在k=0级,是32V 32U=480 480对于k=5;参见图7 b。对于大型对象(例如,k=5时),更高分辨率的掩码具有明显的好处:APL跳过了7.0个点。这种改进并不是以窗口更密集为代价的,因为k=5的输出在![]() 决议。
决议。
再次,我们注意到,这是棘手的,例如,一个4802通道conv.缩放对准头与双线性插值是关键。
Multiple window sizes.到目前为止,我们对所有模型使用了一个窗口大小(每级),即V x U =15 x 15。类似于RPN[34]中的anchors的概念也用于当前的检测器[33,27,23],我们将我们的方法扩展到多个窗口大小。我们设![]() ,每层有两个正面。Tab. 2d显示了拥有两个窗口大小的好处:它将AP增加1.6个点。更多的窗口大小和宽高比是可能的,表明改进的空间。
,每层有两个正面。Tab. 2d显示了拥有两个窗口大小的好处:它将AP增加1.6个点。更多的窗口大小和宽高比是可能的,表明改进的空间。
5.2. Comparison with Mask R-CNN
表3总结了test-dev上最好的TensorMask模型,并将其与当前用于COCO实例分割的主流方法Mask RCNN[17]进行了比较。我们使用Detectron[13]代码来反映自[17]发布以来的改进。我们修改它以匹配我们的实现细节(FPN平均融合、1k预热和1个box丢失)。表3第1行&放大器;验证这些细微之处的影响可以忽略不计。然后,我们使用训练时间范围的扩大和一个较长的时间表[16],这产生了2 AP的增长(表3行3),并建立一个公平和坚实的基线进行比较。
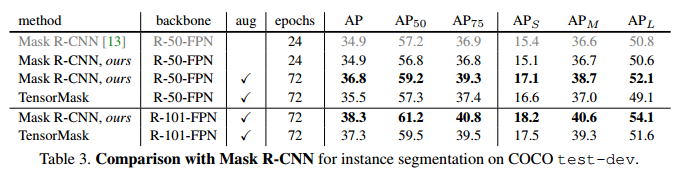
Tab. 2d中最好的TensorMask在test-dev上达到了35.5 mask AP (Tab. 3 row 4),接近于mask R-CNN对应的s 36.8。在ResNet-101中,TensorMask实现了37.3 mask AP,与mask R-CNN相比有1.0 AP差距。这些结果表明,密集滑动窗方法可以缩小检测然后分段系统的间隙(2),定性结果如图2、10和11所示。
我们在A.3中报告了TensorMask的box AP。此外,与Mask R-CNN相比,TensorMask的一个有趣的特性是与box无关。事实上,我们发现盒子和面具的联合训练只比面具训练带来了边际收益,见A.4。
速度方面,最好的R-101-FPN TensorMask在V100 GPU上运行速度为0.38s/im(包括所有后处理),而Mask R-CNN为0.09s/im。在密集滑动窗口(>100k)中预测mask会导致计算开销,而Mask R-CNN对100个最终框进行稀疏预测。加速是可能的,但是超出了这项工作的范围。
Conclusion.
TensorMask是一个密集的滑动窗口实例分割框架,它在定性和定量上都首次接近于成熟的Mask R-CNN框架。它为实例分割研究确立了概念互补的方向。我们希望我们的工作将创造新的机会,使双方蓬勃发展。


















 3471
3471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









