






 本文提出了一种联合学习方法,用于开放域语义分析。该方法结合了从知识库(如WordNet)学习和从原始文本学习的训练方案,以大规模的方式解决了语义角色标注和词义消歧的问题。
本文提出了一种联合学习方法,用于开放域语义分析。该方法结合了从知识库(如WordNet)学习和从原始文本学习的训练方案,以大规模的方式解决了语义角色标注和词义消歧的问题。
计划完成深度学习入门的126篇论文第二十八篇,蒙特利尔大学的Bengio领导关于Joint Learning用于Open-Text研究语义分析及意义表示的论文。
ABSTRACT&INTRODUCTION
摘要
Open-text语义分析器(semantic parsers)的目的是通过推断相应的语义表示(meaning representation)来解释自然语言中的任何语句。不幸的是,由于缺乏直接监督的数据,大型系统不容易使用机器学习。
我们提出了一种方法,通过结合从知识库(如WordNet)学习和从原始文本学习的训练方案,学习如何将MRs分配到广泛的文本中(使用一个包含70,000多个单词的字典映射到40,000多个实体)。该模型通过在这些不同数据源上运行的多任务训练过程,联合学习单词、实体和MRs的表示形式。因此,该系统最终在一个简洁的框架内提供了在语义解析上下文中进行知识获取和词义消歧的方法。对这些不同任务的实验表明了该方法的前景。
介绍
人工智能的一个关键目标一直是使计算机能够自动解释文本并以正式的形式表达其含义。Semantic parsing(Mooney, 2004)正是为了构建这样的系统来解释用自然语言表达的语句。语义分析器的目的是分析句子意义的结构,从形式上讲,这包括将自然语言的句子映射成逻辑意义表示(MR)。这个任务似乎太艰巨了,无法手工完成(因为大量的知识工程可能需要这样做)因此,机器学习似乎是一个很有吸引力的途径。另一方面,机器学习模型通常需要许多带标签的例子,而收集这些例子的成本也很高,尤其是当正确地标注需要语言学家的专业知识时。
由于这需要高度注释的训练数据和/或专门为一个领域构建的MRs,因此此类方法通常只有有限的词汇表(几百个单词)和相应有限的MR表示。例如,美国地理数据集1只处理城市、河流和州的数量和相对位置等事实,大约有800个事实。或者,第二行研究,可以称为open domain(或open-text),致力于学习将MR与任何一种自然语言句子联系起来(Shi和Mihalcea, 2004;Poon和Domingos, 2009)。在这种情况下,由于无法使用捕获深层语义结构的MRs标记大量的自由文本,所以监督较弱。因此,模型推断出更简单的MRs;这也称为浅语义解析。
本文主要研究open domain范畴。我们的目标是产生以下形式的MRs:relation(subject; object),即与主题和对象参数的关系,其中产生的三元组的每个组件都引用一个消除了歧义的实体。这个过程在图1中进行了描述,并在第2节中进行了详细说明。对于一个给定的句子,我们从两个阶段来推断MR:
- 语义角色标注步骤预测语义结构;
- 消歧步骤为每个相关单词分配一个对应的实体,使所学习的能量函数最小化。
对于步骤(1),我们使用现有的方法。我们的主要贡献是为执行步骤(2)建立了一个新的推理模型来自多个数据源的数据,以克服缺乏强有力的监管。该系统规模庞大,拥有超过70,000个单词的字典,可以映射到超过40,000个消歧实体。
我们的基于能量的模型被训练来联合捕捉单词、实体和这些词的组合之间的语义信息。这是在分布式表示中编码的,其中学习每个符号的低维嵌入向量(或简单地嵌入到下面)。我们的语义匹配能量函数(在第3节中介绍)旨在混合这些嵌入,以便为合理的组合分配较低的能量值。
像WordNet (Miller, 1995)和ConceptNet (Liu和Singh, 2004)这样的资源以实体之间的关系(e.g. has part( car; wheel) );但是不要将这些知识与原始文本(句子)联系起来。另一方面,像Wikipedia这样的文本资源并不是基于实体的。正如我们在第4节中所示,我们的训练过程基于跨不同数据集的多任务学习,包括上面提到的三个。这样,由文本和实体之间的关系导出的MRs就嵌入(并集成)在同一个空间中。这使我们能够通过使用大量的间接监督和很少的直接监督来学习对原始文本进行消歧。该模型学习使用常识性知识(如实体间的WordNet关系)来帮助消除歧义,即选择单词的正确WordNet意义。
由于open-text语义分析没有标准的评估方法,所以我们根据不同的标准来评估我们的方法,以反映其不同的属性。第6节给出的结果考虑了两个基准:词义消歧(WSD)和知识获取(WordNet)。我们还证明了我们的系统可以进行知识提取的可能性,即通过对原始文本进行多任务处理来学习WordNet中不存在的新的常识关系。
2 Semantic Parsing Framework
本节介绍我们用来对自由文本执行语义解析的特定框架。
2.1 WordNet-based Representations (MR)
我们考虑用于语义分析的MRs是。REL为关系符号,A0,…, An是它的参数。注意,可以递归地构造几个这样的表单来构建更复杂的结构。我们希望解析open-domain
的原始文本,因此必须考虑大量的关系类型和参数。我们使用WordNet定义REL和Ai参数(Shi和Mihalcea, 2004)。WordNet在其图形结构中包含了全面的知识,其节点(称为同步集)对应senses,而边缘定义了这些senses之间的关系。每个同步集都与一组共享这种感觉的单词相关联。然而,他们通常由8位码标识清楚原因我们表明本文的同义词集连接它的一个词汇,它的词性标记(NN名词,VB为动词,JJ形容词,RB副词)。例如score_NN_1表示名词“score”的第一个意思,也包含单词“mark”和“grade”,score_NN_2表示第二个意思(即乐曲的书面形式)。
我们使用三元组(lhs、rel、rhs)表示WordNet中的关系实例,其中lhs描述关系的左侧、rel类型和rhs的右侧。例如(score_NN_1, _hypernym, evaluation_NN_1)或(score_NN_2, _has_part, _musical_notation_NN_1),我们过滤了出现在少于15个三胞胎中的synsets,以及出现在少于5000个三胞胎中的关系类型。得到一个统计量为41,024个synsets和18种关系类型的图;共有70116个不同的单词属于这些synsets。对于我们最终预测的MRs,我们将把REL和Ai参数表示为WordNet synsets的元组(因此REL可以是任何动词,并且不受限于18个WordNet关系之一)。
2.2 Inference Procedure
Step (1): MR structure inference
我们的语义解析包括两个阶段,如图1所示。第一个阶段是对文本进行预处理,并对MR.的结构进行推理。在这个阶段我们使用的是标准的方法,我们工作的主要新奇之处在于我们对步骤(2)的学习算法。

我们使用SENNA software2 (Collobert et al., 2011)来执行part-of-speech记(POS)、tagging、lemmatization和semantic role labeling(SRL)。下面,我们将引理词和POS标记(如score NN或along VB)的连接称为引理。注意,没有整数后缀,这是引理与同步集的区别:引理在语义上允许有歧义。SRL步骤包括为与每个命题的动词关联的每个语法参数分配一个语义角色标签。这是至关重要的,因为它将被使用来推断MR的结构。
我们只考虑符合以下模板的句子:(主语、动词、直接宾语)。在这里,模板的三个元素都与一组引理词(即多词短语)相关联。SRL用于将句子结构成(lhs =主语,rel =动词,rhs =宾语)模板,注意在原始文本中顺序不一定是主语/动词/直接宾语(例如在被动句中)
总之,这一步从一个句子开始,要么拒绝它,要么输出一个三元组引理,一个用于主语,一个用于关系或动词,一个用于直接宾语。为了完成我们的语义解析(或MR),必须将引理转换为synsets,也就是说,我们仍然必须执行消除歧义,这在步骤(2)中进行。
Step (2): Detection of MR entities
第二步是识别句子中表达的每个语义实体。给定一个关系三元组(lhslem、rellem、rhslem),其中三元组的每个元素都与一组引理相关联,生成一个对应的三元组(lhssyn、relsyn、rhssyn),其中引理被synsets替换。这一步是一种形式的所有单词词义消歧在特定的设置,即。w.r.t.逻辑形式的语义解析步骤(1)。根据引理,这可以是简单的(一些二战前题如电视节目NN和NN对应一个同义词集)或非常具有挑战性的(_run_VB可以映射到33个不同的同义词集和神经网络运行10)。因此,在我们提出的语义分析框架中,MRs对应于三组synset (),它们可以重组为relsyn (lhssyn, rhssyn)的形式,如图1所示。
由于该模型是围绕关系三元组构建的,因此将MRs关系和WordNet关系转换为同一方案。例如,WordNet关系(score_NN_2, _has_part, _musical_notation_NN_1)与我们的MRs符合相同的模式,WordNet关系类型有part扮演动词的角色。
3 Semantic Matching Energy
本节介绍了本文的主要贡献,我们使用一个能量函数将引理和WordNet实体嵌入到相同的向量空间中(参见(Lecun et al., 2006),以介绍基于能量的学习)。该语义匹配能量函数用于预测给定引理的合适的同步集。这是通过近似地搜索一组与观察引理兼容的同步集来实现的,即一组最小化能量的同步集。
3.1 Framework
我们的模型设计的主要概念如下:
- 命名的符号实体(synsets、关系类型和引理)都与一个联合的d维向量空间相关联,称为\嵌入空间”,遵循了之前在神经语言模型中的工作(参见(Bengio, 2008))。第i个实体被分配给一个向量
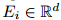 ,这些向量是模型的参数,通过共同学习可以很好地完成语义分析任务。
,这些向量是模型的参数,通过共同学习可以很好地完成语义分析任务。 - 与特定三元组(lhs、rel、rhs)关联的语义匹配能量值由参数化函数
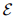 计算,该函数首先将所有符号映射到它们的嵌入中。
计算,该函数首先将所有符号映射到它们的嵌入中。 - energy function
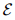 还必须能够处理可变大小的参数,因为例如,句子的主语部分可能有多个引理。能量函数E被优化为训练实例比其他可能的符号配置更低。因此,语义匹配能量函数可以区分实体的似是而非似是而非的组合,从而为引理选择最可能的意义。
还必须能够处理可变大小的参数,因为例如,句子的主语部分可能有多个引理。能量函数E被优化为训练实例比其他可能的符号配置更低。因此,语义匹配能量函数可以区分实体的似是而非似是而非的组合,从而为引理选择最可能的意义。
3.2 Parametrization
语义匹配能量函数具有并行结构(如图2所示):首先,对(lhs, rel)和(rel, rhs)分别进行组合,然后对这些语义组合进行匹配。
输入的三元组![]()
![]()
- 输入元组中的每个符号i都映射到它的嵌入
- 所有相关联的映射进行符号在相同的元组由池聚合函数π(我们使用均值但其他可信的候选项包括若干这类元素统计数字的和、最大值和组合):
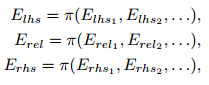
![]() 表示左侧元组的第j个单独元素,以此类推
表示左侧元组的第j个单独元素,以此类推
- 分别与lhs和rel参数关联的embeddings,
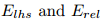 用于在Erel表示的关系类型上下文中为lhs构造一个新的关系相关的嵌入Elhs(rel),对于rhs也是类似的
用于在Erel表示的关系类型上下文中为lhs构造一个新的关系相关的嵌入Elhs(rel),对于rhs也是类似的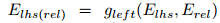
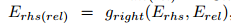 ,
,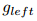 和
和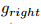 是参数化函数,其参数在训练过程中进行调优。
是参数化函数,其参数在训练过程中进行调优。 - 能量由左右两边的变换嵌入计算得到:
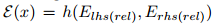 ,其中h是一个可以硬编码或参数化的函数。如果是后者,则在训练期间调整参数
,其中h是一个可以硬编码或参数化的函数。如果是后者,则在训练期间调整参数
能量函数的许多参数化是可能的(例如,g和h的非线性、线性等公式),我们只探索了几个。在本文中,我们只给出了双线性设置(在第6节提出的实验中表现最好):g函数是双线性层,h是点积。更准确地说,我们使用了:
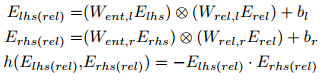
这对双线性参数化是有吸引力的,因为操作⊗允许编码连词lh和rel和rhs rel。
4 Multi-Task Training
为了训练能量函数E的参数,我们对所有训练数据资源进行循环,并使用随机梯度下降(Robbins and Monro, 1951)。也就是说,我们重复以下步骤:

步骤4中的常数1是边距。梯度步骤需要一个学习λ。第5步中的规范化有助于从模型中移除缩放自由度。上述算法适用于除XWN和Wku外的所有数据源。在这种情况下,正三联由引理(作为上下文)和由其synset替换的消歧引理组成。与Wikipedia不同,这是标记为data的,所以我们确定这个synset是真正意义上的。因此,为了提高训练效率和产生更有鉴别性的消歧,在概率为12的步骤3中,我们要么从C中随机抽取样本,要么从与这个消歧引理(即它的其他含义的集合)对应的剩余候选集中抽取样本。包含实体表示的矩阵E是通过复杂的多任务学习过程学习的,因为所有关系和所有数据源都使用一个嵌入矩阵(每个嵌入矩阵实际上对应于符号元组的不同分布,即,另一项任务)。因此,实体的嵌入包含来自所有关系和数据源的分解信息,其中实体涉及到lhs、rhs甚至rel(对于谓词)。对于每个实体,模型都必须了解它如何以许多不同的方式与其他实体交互。
5 Related Work
我们的方法在基于能量的模型构建以及如何将多个任务和训练资源统一起来以实现其语义分析目标方面都是独创的。然而,它与许多以前的作品有关系。Shi和Mihalcea(2004)提出了一个基于规则的开放文本语义分析系统,该系统使用WordNet和FrameNet (Baker et al., 1998), Giuglea和Moschitti(2006)提出了一个连接WordNet、VerbNet和PropBank (Kingsbury和Palmer, 2002)的模型,用于使用树内核进行语义分析。最近提出了一种基于Markov-Logic Networks的无监督语义分析方法,该方法也可用于信息获取(Poon和Domingos, 2009,2010)。但是,它没有像所提议的方法那样将MRs连接到现有的本体,而是构造了一个新的本体,并且不利用现有的知识。自动信息提取是许多模型和演示的主题(Snow等,2006;耶茨等,2007;Wu and Weld, 2010;但是它们都不依赖于联合嵌入模型。有些方法直接针对丰富现有资源,正如我们在这里使用WordNet所做的那样(Agirre et al., 2000;Cuadros和Rigau, 2008;但是这些都不需要学习。
最后,之前的几项工作的目标是通过自动获取示例(Martinez et al., 2008)或通过连接不同的知识库(Havasi et al., 2010)来使用额外的知识来改进水务署。据我们所知,基于能量的模型还没有应用到语义分析中,但是已经为其他NLP任务开发了方法。
Bengio等人(2003)开发了一种用于语言建模的神经单词嵌入方法(它们只对单词建模,而不是实体)。Paccanaro和Hinton(2001)开发了用于学习逻辑关系的实体嵌入(但不建模单词)。Collobert和Weston(2008)进一步开发了单词嵌入模型,并将其应用于各种NLP任务。实际上,我们使用他们的SRL系统来解决我们系统的步骤(1)(参见图1),并将重点放在步骤(2)上,但是他们没有解决这个问题。我们系统的架构也与最近门控模型(Sutskever et al., 2011)和递归自动编码器(Bottou, 2011;Socher等,2011)。
最后,Bordes等人(2011)描述了一个用于知识获取的实体嵌入模型:给定关系在训练三元组的同时,他们还会测量模型对新关系的泛化程度。他们的模型将每种关系类型嵌入到一对矩阵中,而不是使用双线性参数化。这使得关系类型具有不同的状态(它们不能显示为lhs或rhs),因此需要更多的参数。用数千个动词训练原始文本是不可能的,因此它们的模型不适合语义分析。

















 5189
5189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









