




默认账户为 ubuntu,初始密码为 gEjSY$:9B6c]f[+
export PYTHONPATH=$PYTHONPATH:/home/ubuntu/CloudSimPyEnergy
export PYTHONPATH=$PYTHONPATH:/home/ubuntu/CloudSimPy-master
rm -rf /home/ubuntu/CloudSimPyEnergy.rar
rm -rf /home/ubuntu/CloudSimPyEnergy
cd /home/ubuntu/
rar x /home/ubuntu/CloudSimPyEnergy.rar
rar x /home/ubuntu/CloudSimPy-master.rar
cd /home/ubuntu/CloudSimPyEnergy/playground/Non_DAG/launch_scripts
cd /home/ubuntu/CloudSimPyEnergy-master/playground/Non_DAG/launch_scripts
cd /home/ubuntu/CloudSimPy-master/playground/Non_DAG/launch_scripts/
python3 energy-single-process-machine5.py
python3 main-makespan.py
cd /home/ubuntu/CloudSimPyEnergy/playground/DAG/launch_scripts
cd /home/ubuntu/CloudSimPyEnergy/playground/DAG/launch_scripts
python3 test-energy-machine5.py
python3 test-energy-machine10.py
python3 PPOTest.py
python3 PG.py
特征提取方面: 共7个参数
DRL.py之中的 extract_features <machine + task>
machine: cpu, memory, power
power的归一化公式( (pow - 45) / 627 :减去的总体的最大值和最小值
task: 在feature_function.py中 : [cpu, memory, duration, task.waiting_task_instances_number]
job.csv: Jobs numer: 10 Tasks number: 93 (按照job_id, 因为程序读取之后会自动按照subtime排序)
报错信息
File "/usr/lib/python3.6/multiprocessing/managers.py", line 749, in _callmethod
conn = self._tls.connection
AttributeError: 'ForkAwareLocal' object has no attribute 'connection'
如果有子进程在使用Manage()对象时,在父进程不能使用这个对象,所以要等所有子进程结束即需使用p.join()后方可在父进程使用Manage()的对象。
python如何在主进程中终止子进程并清理子进程的资源。
p.terminate()
p.terminate(): # 如何终止进程并释放资源
pool.apply_async(test, args=)如何传递自定义参数对象
不是僵尸进程的问题,就是内存不够用
每次开启8条线程去收集,7个参数。
machine5/multiprocess/
任务集中无依赖关系的命名为随机字符串
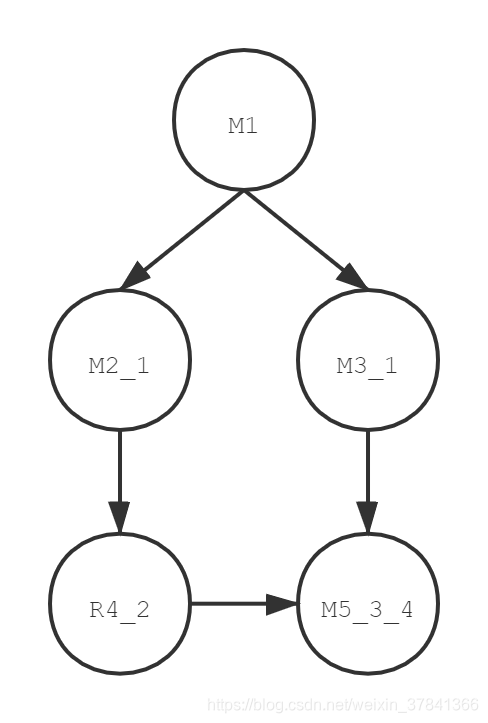
一个工作集(job)为一个DAG, 其中每个节点对应一个任务集(task), 如果task2依赖任务1,那么任务2的中任务实例都不能比任务1中的实例优先执行。只有当一个任务集中的任务实例都执行完毕,才能进入finished状态。
比如说Job_A, 包含5个任务集,每个任务集由名称标记。
| 任务编号 | 任务名称 | 解释 |
| task1 | M1 | 表示是一个独立任务,无需等待其他任务执行完成即可启动 |
| task2 | M2_1 | 任务2的启动依赖任务1的结束 |
| task3 | M3_1 | 任务3的启动依赖任务1的结束 |
| task4 | R4_2 | 任务4的启动依赖任务2的结束 |
| task5 | M5_3_4 | 任务5的启动依赖任务3和任务4的结束 |
在一个DAG中,只需关注数字,任务名称的第一个字母和依赖无任何关系。比如(R和M可以忽略,避免引起混淆)
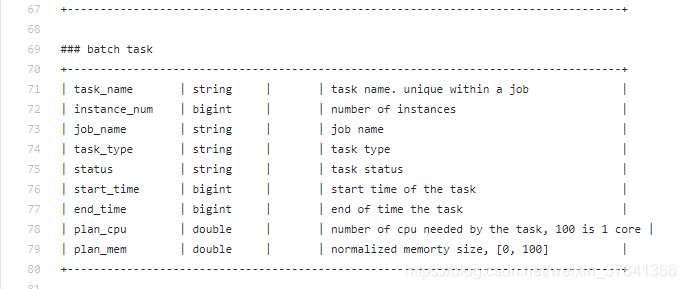
对batch task文件进行处理
- 处理程序中: task_id; 在程序中处理的时候需要去掉第一个字母 R2_1变成 2_1,(另外如果task_id以"task"开头则表示这是一个不具有依赖关系的独立任务,刚开始就需要判断, 然后将其task_id替换为0即可)
- csv中: start_time改成submit_time
- csv中: 添加一个duration字段 end_time - submit_time
- csv中: 将plan_cpu改成cpu后并且/100
- 处理程序中: job_name改成job_id 在处理时需要去掉"j_前缀"(也可以无需处理)
- csv中: instance_num改成instances_num
- 去掉状态为waiting和Failed的任务
具体思路:
在前6个job_chunk上进行不断移动训练,观察pg算法和ppo算法的收敛性,以及对比效果, 对每次收敛后的结果值 和random , FIFO, round robin算法进行对比
注意:每次更换job_chunk时,需对特征的设置初始化,视每个工作块的具体情况而改变。都迭代500次
再后4个job_chunk上进行测试,对比这5种算法的差异
job_chunk_1Jobs number: 10
Tasks number: 29
Task instances number mean: 5.344827586206897
Task instances number std 13.068192134336279
Task instances cpu mean: 0.8741935483870967
Task instances cpu std: 0.216969957687745
Task instances memory mean: 0.33245161290322583
Task instances memory std: 0.11787003195419271
Task instances duration mean: 68.02580645161291
Task instances duration std: 77.34680579238628
job_chunk_2
Jobs number: 10
Tasks number: 64
Task instances number mean: 5.890625
Task instances number std 13.611940056780114
Task instances cpu mean: 0.7493368700265252
Task instances cpu std: 0.24999912051572956
Task instances memory mean: 0.4118832891246684
Task instances memory std: 0.1617294041653373
Task instances duration mean: 15.061007957559681
Task instances duration std: 10.459926918127232
def features_normalize_func(x):
y = (np.array(x) - np.array([70.4, 17, 262.88, 0.874, 0.4119, 15.061, 5.891, 1.167, 1.167, 1.5, 1.833, 1.833])) / np.array(
[35.508, 8.367, 231.479, 0.250, 0.162, 10.460, 1, 0.897, 0.897, 0.957, 1.572, 1.572])
return y
[cpu, memory, duration, task.waiting_task_instances_number]
job_chunk_3
Jobs number: 10
Tasks number: 48
Task instances number mean: 13.416666666666666
Task instances number std 52.961791783217535
Task instances cpu mean: 0.5069099378881987
Task instances cpu std: 0.0696235527230905
Task instances memory mean: 0.48448757763975153
Task instances memory std: 0.17494511517600547
Task instances duration mean: 209.32142857142858
Task instances duration std: 92.05327299323277
def features_normalize_func(x):
y = (np.array(x) - np.array([70.4, 17, 262.88, 0.507, 0.485, 209.321, 13.417, 1.167, 1.167, 1.5, 1.833, 1.833])) / np.array(
[35.508, 8.367, 231.479, 0.0696, 0.175, 92.053, 52.962, 0.897, 0.897, 0.957, 1.572, 1.572])
return y
job_chunk_4
Jobs number: 10
Tasks number: 43
Task instances number mean: 51.883720930232556
Task instances number std 179.85526601057884
Task instances cpu mean: 0.741371582250112
Task instances cpu std: 0.24973890710188876
Task instances memory mean: 0.4256207978484985
Task instances memory std: 0.07868517002341387
Task instances duration mean: 568.4778126400718
Task instances duration std: 526.9640441558946
def features_normalize_func(x):
y = (np.array(x) - np.array([70.4, 17, 262.88, 0.741, 0.426, 568.478, 51.884, 1.167, 1.167, 1.5, 1.833, 1.833])) / np.array(
[35.508, 8.367, 231.479, 0.2497, 0.0787, 526.964, 179.855, 0.897, 0.897, 0.957, 1.572, 1.572])
return y

















 1704
1704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









