




1hive元数据管理
- 1库,表的基本信息,包括表名,存储类型及地址,分区信息列等
- 2已经注册的UDF相关信息
- 3用户,权限相关信息
2spark ThriftServer
- 1 spark sql处理
- 2sql语法解析
- 3逻辑执行计划生成及优化
- 4物流执行计划及优化
3表,分区与桶
- 内外表
- 数据格式(推荐parquet存储)
- 分区(基于文件目录index)
- 桶(大表join)
4hive表小文的数量影响namenode的性能和稳定
1产生:
- 动态分区插入数据,产生大量的小文件,从而导致map数量剧增。
- reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的)。
- 数据源本身就包含大量的小文件。
2影响:
- hdfs角度: 小文件的文件信息要保存在namenode的内存中的,对namenode的内存有很大的压力
- hive角度:小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
- 压缩:小文件的压缩性能会产生影响
3解决方案:
源头解决:
- 使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件。
- 减少reduce的数量(可以使用参数进行控制)。
- 少用动态分区,用时记得按distribute by分区。
已经存在小文件
- 使用hadoop archive命令把小文件进行归档。
- 重建表,建表时减少reduce数量。
- 通过参数进行调节,设置map/reduce端的相关参数,如下:
设置map输入合并小文件的相关参数:
//每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
设置map输出和reduce输出进行合并的相关参数:
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
5数据表的列类型应该基于业务含义
例子:如果int类型,用string类型存储
1不同类型压缩会影响
2你在处理的过程中可能要类型换行,需要时间
6表之间join关联比较消耗性能,表反范式可能更好(数据冗余)
两个表如何频繁进行join时候,我们可以设计成一个表中,因为hdfs存储比较便宜,牺牲存储实现更高的查询效率
7sql优化
- 1不要在sql使用星号
- 2使用limit,除非你确定表数据有多少行,否则表过大加载到内存中,可能ThriftServer就会oom,挂掉
- 3Cross join可能导致task数量过多(笛卡尔积关联)
-
4Container killed by YARN for exceeding memory limits. 2.5 GB of 2.5 GB physical memory used. Consider boosting
-
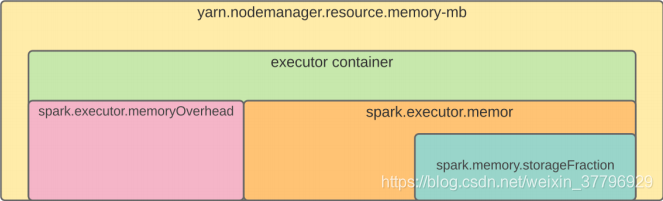
-
join操作,尽量使用broadcast join减少shuffe数据
8排序
- order by 全局排序,只有一个reduce Task用于排序
- sort by 只保证一个reuduce内部有序,常常和distribute by 一起,按照key1分组,按照key2排序
- distribute by 保证相同的key分发到到相同的reduce task中
- cluster by=Distribute by +sort by on some key
9数据倾斜
- 转换为broadcast join
- adaptive exection (调整执行策略)1动态调整shuffle partition数量

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









