




 本文介绍了一种使用Redis处理导入数据中重复项的方法,通过将数据存入Redis的Set集合来判断并标记重复数据,从而避免重复数据的多次导入。
本文介绍了一种使用Redis处理导入数据中重复项的方法,通过将数据存入Redis的Set集合来判断并标记重复数据,从而避免重复数据的多次导入。
之前写了一篇关于重复数据的处理,请先参考上篇关于重复数据的处理,文章:https://mp.youkuaiyun.com/editor/html/108664938 ,但是这种处理只能用数据库的存量数据来匹配导入的数据是否是重复的,并不能解决数据集本身重复的问题。
意思就是,导入的excel数据本来重复了,如果数据库没有和这两条数据一样的数据,那么这两条数据都会导入成功!但我们原意是只想导入重复的第一条,第二条错误(重复)数据输出到excel表格,提供给用户,如下重复数据(数据库没有以下两条数据,因此不做处理两条都是导入成功的!)

这两条数据本身重复,而excel解析这两条数据进入校验类IExcelVerifyHandler校验,是一条条进去的。你也可以在进入校验类后写个for循环遍历处理,但是这样做用户不知道哪条数据是重复的,不能有很好的用户体验
因此,需要把每一条导入的数据记录下来,加上数据库的数据,共同来匹配。这里我想到了引入第三方中间件Redis来记忆数据,选择Set集合作为存储结构。
逻辑是这样的,流程图如下:
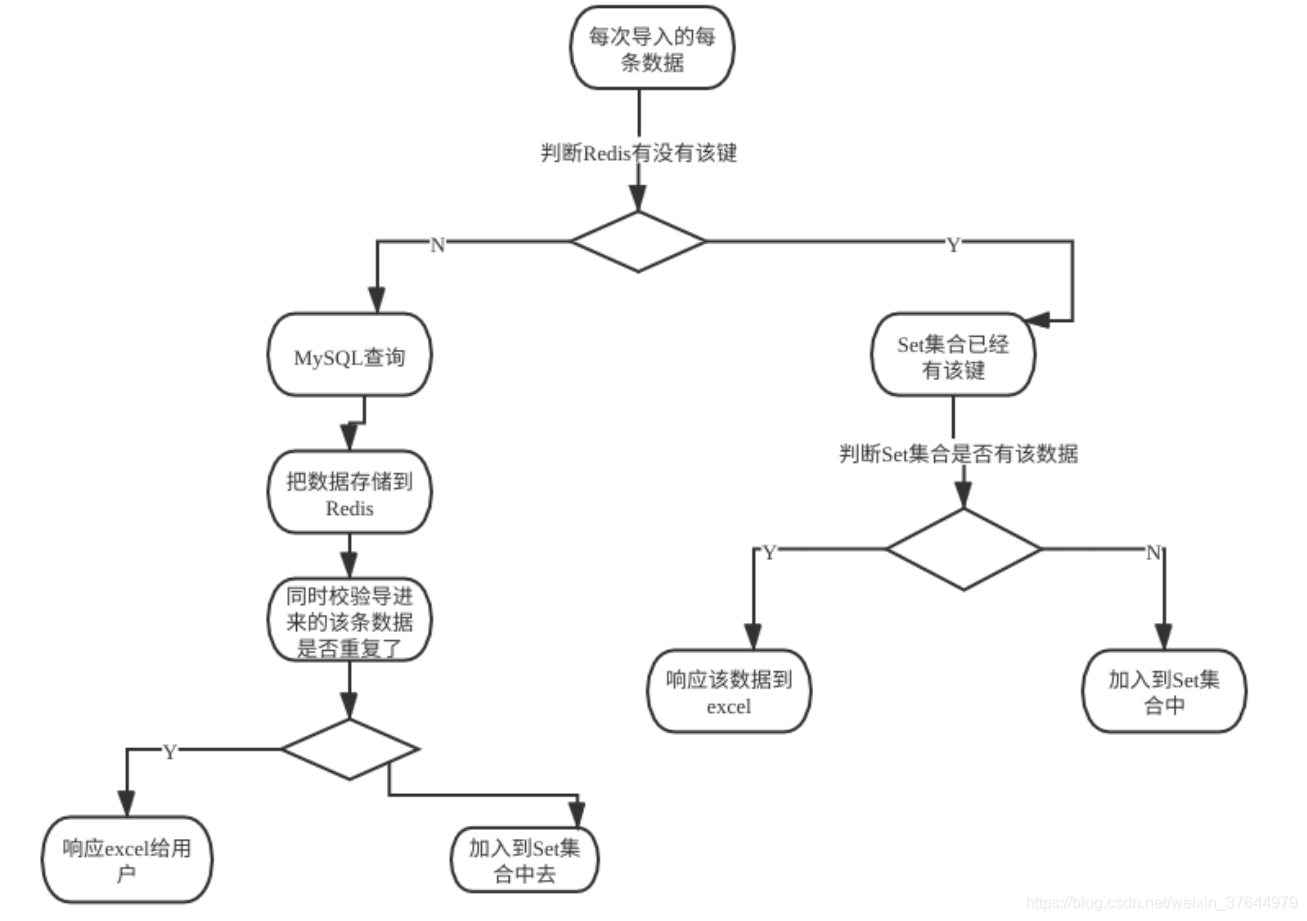
这样每次导进来的数据先去Set集合查一遍,看是否存在,在做具体的处理,代码如下:
//引入第三方中间件来存储导入的铺位号做校验!
if (JedisUtils.hasKey(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey())) {
Boolean aBoolean = JedisUtils.isMember(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),bunkCode);
if (aBoolean) {
joiner.add("该行xxx重复!");
}else {
JedisUtils.sadd(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),bunkCode);
JedisUtils.expire(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getExpireTime());
if (collect.contains(bunkCode)) {
joiner.add("该行xxx重复!");
}
}
} else {
JedisUtils.sadd(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),collect.toArray());
JedisUtils.expire(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getExpireTime());
if (collect.contains(bunkCode)){
joiner.add("该行xxx重复!");
}else {
JedisUtils.sadd(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),bunkCode);
JedisUtils.expire(RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getKey(),RedisKeyEnum.PMS_ADMIN_BUNK_CODE_KEY.getExpireTime());
}
}把错误的信息加入到joiner,如果joiner不为空,就会返回excel文件给用户
if (joiner.length() != 0) {
return new ExcelVerifyHandlerResult(false, joiner.toString());
}这样就能做到重复数据的处理

















 2462
2462




 到【灌水乐园】发言
到【灌水乐园】发言







