




1. 协议
| 协议类型 | 事务 | 持久化 | 代表MQ | 其它描述 |
|---|---|---|---|---|
| AMQ | 支持 | 支持 | RabbitMQ, ActiveMQ | 金融行业,在可靠性消息处理上有优势 |
| MQTT | 不支持 | 不支持 | RabbitMQ, ActiveMQ | 计算能力有限、低带宽、网络不稳定的场景 |
| OpenMessaging | RocketMQ | 流处理领域 | ||
| Kafka协议 | 不支持 | 支持 | Kafka | 消息内部通过长度来分隔,由一些基本数据类型组成 |
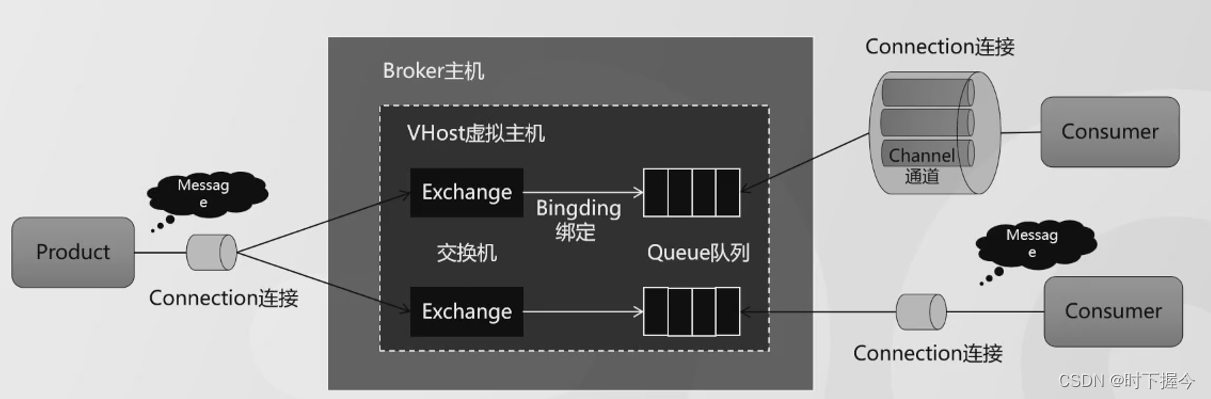
2. RabbitMQ架构原理
- 交换机类型
① 直连Direct,使用明确的绑定键,适用于业务目的明确的场景
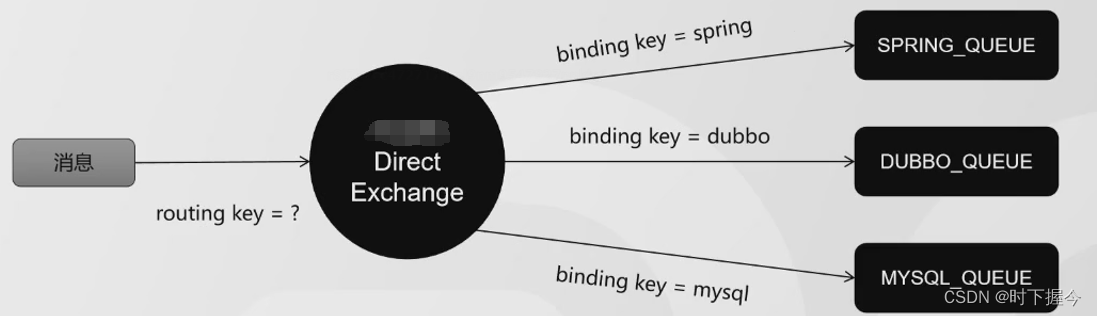
② 主题TOPIC
使用支持通配符的的绑定键。适用于根据业务主题过滤消息的场景。
#代表匹配0个或者多个单词;*代表匹配不多不少一个单词;每个单词用点号隔开
③ 广播Fanout
无需绑定键。适用于通用类业务消息。

3.内存管理
内存调整的两种模式,相对模式和绝对模式
- 相对模式
rabbitmqctl set_vm_memory_high_ watermark <fraction>
fraction为内存阈值,默认是0.4, 表示RabbitMQ使用的内存超过系统内存的40%时,会产生内存告警
- 绝对模式
rabbitmqctl set_vm_memory_high_watermark absolute <value>
absolute:绝对值,固定大小,单位为KB、MB、GB
- 内存换页
vm_memory_high_watermark_paging_ ratio=0.5
在RabbitMQ达到内存阈值并阻塞生产者之前,会尝试将内存中的消息换页到磁盘,以释放内存空间。当换页阈值大于1时,相当于禁用了换页功能
4.磁盘控制
rabbitmqctl set_disk_free_limit <limit>
rabbitmqctl set_disk_free_limit mem_relative <fraction>
# limit 为绝对值,KB、MB、GB
# fraction 为相对值,建议 1.0~2.0 之间
# rabbitmq.conf
disk_free_limit.relative=1.5
# disk_free_limit.absolute=50MB
RabbitMQ 通过磁盘阈值参数控制磁盘的使用量,当磁盘剩余空间小于磁盘阈值时,RabbitMQ 同样会阻塞生产者,避免磁盘空间耗尽。
磁盘阈值默认 50M,由于是定时检测磁盘空间,不能完全消除因磁盘耗尽而导致崩溃的可能性,比如在两次检测之间,磁盘空间从大于 50M 变为 0M。
一种相对谨慎的做法是将磁盘阈值大小设置与内存相等
5. RabbiMQ 插件管理
插件列表: rabbitmq-plugins list
启用插件:rabbitmq-plugins enable xxxx
卸载插件:rabbitmq-plugins disable xxxx
6. 死信
适用于
① 订单过期关闭;
② 消息被消费者拒绝并且未设置重回队列:(NACK || Reject ) && requeue == false;
③ 队列达到最大长度,超过了 Max length(消息数)或者 Max length bytes(字节数)
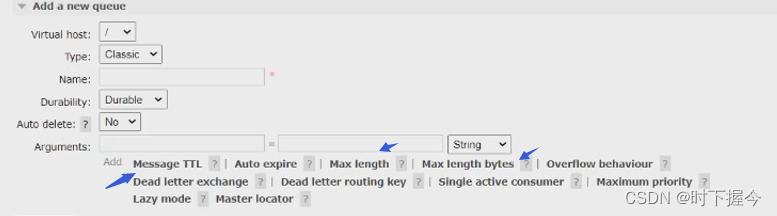
6.1 死信队列
队列的消息过期属性:x-message-ttl
RabbitMQ 的消息也有单独的过期时间属性
如果同时指定了 Message TTL 和 Queue TTL,则小的那个时间生效。
消息过期以后,如果没有任何配置,直接丢弃,可以通过配置让这样的消息变成死信(Dead Letter)
- 创建一个死信交换机 DLX(Dead Letter Exchange)
- 创建一个死信队列 DLQ(Dead Letter Queue,绑定死信交换机,通过"#"绑定,代表无条件路由
- DLX 实际上也是普通的交换机,DLQ 也是普通的队列
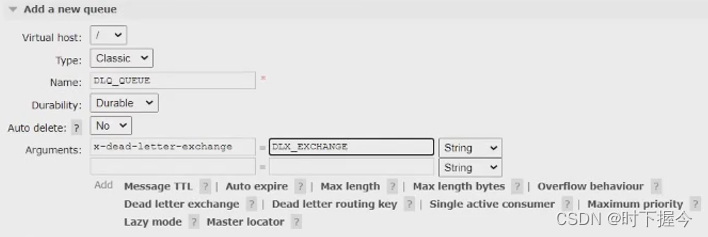
队列指定了 DLX,就会发送到 DLX。如果 DLX 绑定了 DLQ,就会路由到 DLQ。
流转原理
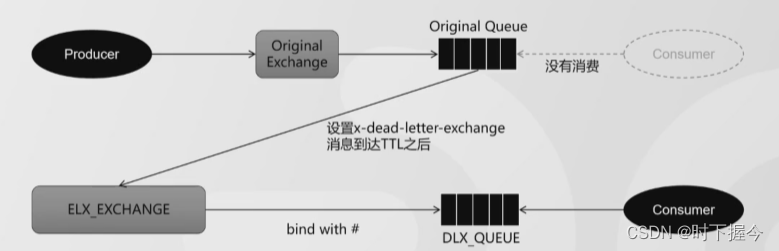
使用死信队列实现延时消息的缺点:
① 如果统一用队列来设置消息的 TTL,当梯度非常多的情况下,比如 1 分钟,2分钟,5 分钟,10 分钟,20 分钟,30 分钟……需要创建很多交换机和队列来路由消息。
② 如果单独设置消息的 TTL,则可能会造成队列中的消息阻塞——前一条消息没有出队(没有被消费),后面的消息无法投递(比如第一条消息过期 TTL 是 30min,第二条消息 TTL 是 10min。10 分钟后,即使第二条消息应该投递了,但是由于第一条消息还未出队,所以无法投递)。
6.2 延时插件
① cd /usr/lib/rabbitmq/lib/rabbitmq_server-3.8.11/plugins
② wget
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/3.8.9/
rabbitmq_delayed_message_exchange-3.8.9-0199d11c.ez
③启用 rabbitmq_delayed_message_exchange
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
④重启 rabbitmq
service rabbitmq-server restart 或者 rabbitmq-server restart
⑤ 声 明 一 个 x-delayed-message 类 型 的 Exchange 来 使 用
delayed-messaging 特 性 。 x-delayed-message 是 插 件 提 供 的 类 型 , 并 不 是
RabbitMQ 本身的(区别于 direct、topic、fanout、headers)
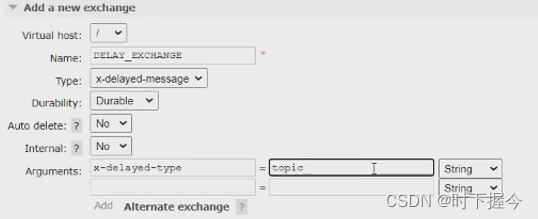
本质:定时器取出过期消息,违背了队列先进先出的原则,经延时插件路由到延时队列。要求消息实现持久化
7. 高可用集群方案
RabbitMQ集群里,至少有一个磁盘节点,它用来持久保存我们的元数据,如果RabbitMQ是单节点运行,则默认就是磁盘节点。但是为了提高性能,其实不需要所有节点都是disc的节点,根据需求分配即可。
#加入集群时设置节点类型
rabbitmqctlchange_cluster_node_type disc|ram
磁盘节点
将元数据(包括队列名字属性、交换机的类型名字属性、绑定、vhost) 放在磁盘中。未指定类型的情况下,默认为磁盘节点。
内存节点
就是将元数据都放在内存里,内存节点的话,只要服务重启,该节点的所有数据将会丢失。
7.1 普通集群模式
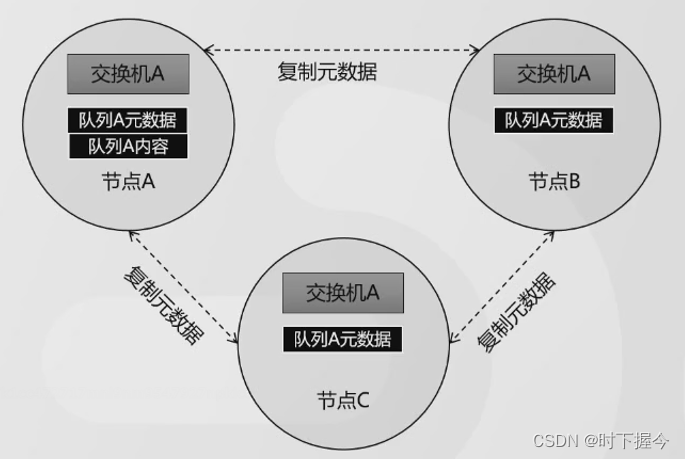
一个节点作为Master,存储元数据,其它节点作为Slave,从Master复制元数据
7.2 镜像集群模式
- 一个节点作为Master,存储元数据和数据,其它节点作为Slave,从Master复制元数据和数据。
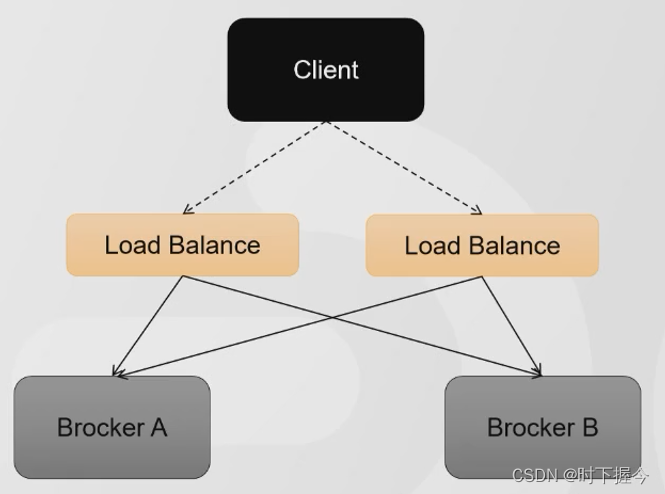
- 需要一个负载均衡的组件(例如HAProxy,LVS,Nignx),由负载的组件来做路由。这个时候,只需要连接到负载组件的IP地址就可以
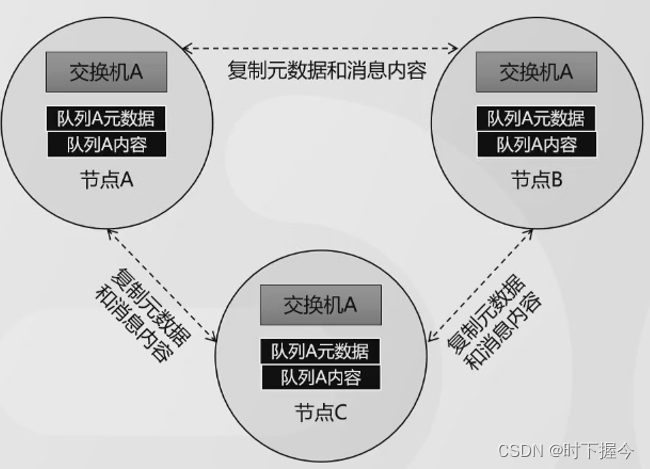
由普通集群模式 转变为 镜像集群模式的操作:
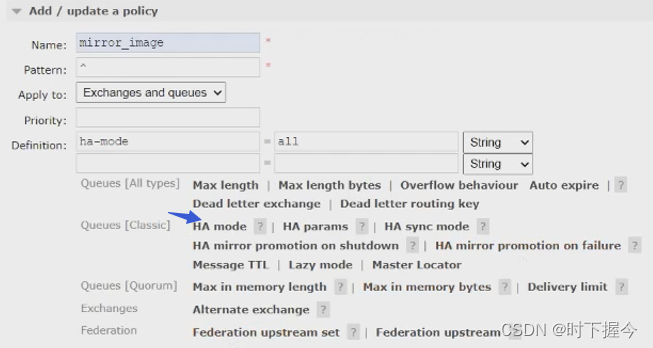
7.3 基于HAproxy+Keepalived搭建高可用
如果负载的组件也挂了,客户端就无法连接到任意一台MQ的服务器。所以负载软件本身也需要做一个集群(双机热备)。
两个Keepalived抢占一个VIP192.168.8.149。谁抢占到这个VIP,应用就连接到谁,来执行对MQ的负载
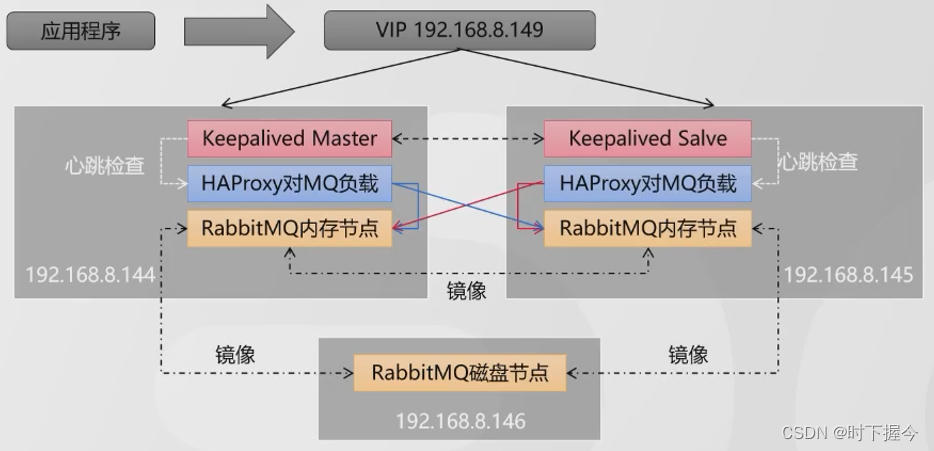
Keepalived挂了一个节点,没有影响,因为BACKUP会变成MASTER,抢占VIP。HAProxy挂了一个节点,没有影响,VIP会自动路由的可用的HAProxy服务,RabbitMQ挂了一个节点,没有影响,HAProxy会自动负载到可用的节点
8.可靠性投递
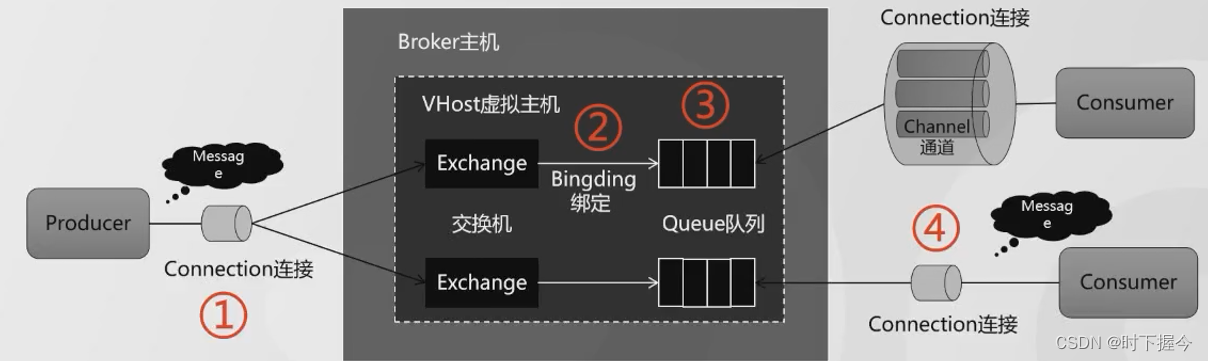
8.1 消息从生产者发送到Broker
Broker不给应答,生产者不断地发送。
两种确认机制
第一种Transaction(事务)模式,第二种Confirm(确认)模式
① Transaction(事务)模式

② Confirm(确认)模式
- 普通确认模式

这种发送1条确认1条的方式,发送消息的效率不太高 - 批量确认
批量的数量的确定。对于不同的业务,到底发送多少条消息确认一次?数量太少,效率提升不上去。数量多的话,比如我们发1000 条消息才确认一次,如果前面999条消息都被服务端接收了,如果第1000条消息被拒绝了,那么前面所有的消息都重发。
- 异步确认模式
异步确认模式需要添加一个ConfirmListener,并且用一个SortedSet来维护一个批次中没有被确认的消息。
8.2 消息从Exchange路由到Queue
消息无法路由到正确队列
两种解决办法:
一是让服务端重发给生产者,
二是让交换机路由到另一个备份的交换机
8.3 消息在Queue中存储
RabbitMQ的服务或者硬件发生故障,比如系统宕机、重启、关闭等等,可能会导致内存中的消息丢失
四种解决方案:队列持久化,交换机持久化,
消息持久化,集群部署
8.4 消费者订阅Queue并消费消息
如果消费者收到消息后没来得及处理即发生异常,或者处理过程中发生异常,会导致④失败。服务端应该以某种方式得知消费者对消息的接收情况,并决定是否重新投递这条消息给其他消费者。
没有收到ACK的消息,消费者断开连接后,RabbitMQ会把这条消息发送给其他消费者。
如果没有其他消费者,消费者重启后会重新消费这条消息
消费者给Broker默认自动ACK应答,消费者会在收到消息的时候就自动发送ACK,而不是在方法执行完毕的时候发送ACK
若等消息消费完毕或者方法执行完毕才发送ACK,需要先把自动ACK设置成手动ACK。即把autoAck设置成false
这个时候RabbitMQ会等待消费者显式地回复ACK后才从队列中移去消息
8.5 其它保障消息可靠性的方案
生产者最终确定消费者有没有消费成功的方式
8.5.1 消费者回调
调用生产者AP;发送响应消息给生产者
8.5.2 消息补偿
约定超时时间;定时任务重发;梯度式重发;重发消息要控制次数;
8.5.3 消息幂等性
用户对于同一操作发起的一次或者多次请求,最后的结果都
是相同的,这就是幂等性
避免消息的重复消费:
① 每一条消息生成一个唯一的业务 ID,通过日志或者消息落库来做重复控制。
② 业务要素一致(付款人 ID、商户 ID、交易类型、金额、交易地 点、交易时间)可能是同一笔消息
8.5.4 消息的顺序性
消息的顺序性指的是消费者消费消息的顺序跟生产者生产消息的顺序是一致的。
一个队列有多个消费者时,一个队列仅有一个消费者的情况才能保证顺序消费(不同的业务消息发送到不同的专用的队列)
9.实践经验分享
9.1 信息落库 + 定时任务
将需要发送的消息保存在数据库中,可以实现消息的可追溯和重复控制,需要配合定时任务来实现…
① 将需要发送的消息登记在消息表中
② 定时任务一分钟或半分钟扫描一次,将未发送的消息发送到 MQ 服务器,并且修改状态为已发送
9.2 减少连接数
在发送大批量消息的情况下,创建和释放连接依然有不小的开销。我们可以跟接收方约定批量消息的格式,比如支持 JSON 数组的格式,通过合并消息内容,可以减少生产者/消费者与Broker 的连接。
建议单条消息不要超过 4M(4096KB),一次发送的消息数需要合理地控制

















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









