



1 hive架构设计和工作原理
1.1 hive架构设计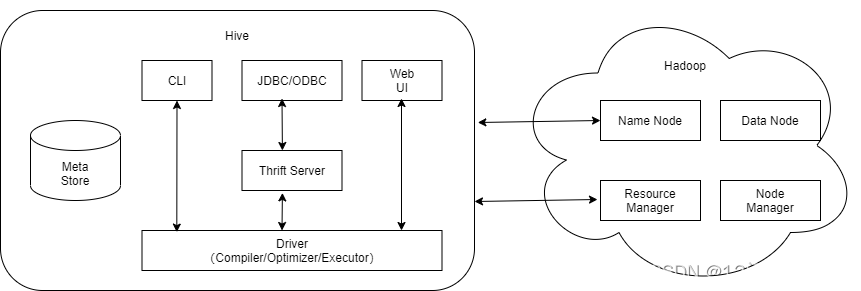
- Web UI:Hive的用户接口层,CLI即Shell命令,CLI最常用。
- Meta Store:Hive将元数据存储在数据库中,连接到这些数据库(MySQL、derby)的模式分三种:单用户模式、多用户模式、远程服务器模式。元数据包括Database、表名、表的列及类型、存储空间、分区、表数据所在目录等。
- Driver:完成HQL的查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。生产的查询计划存储在HDFS中,并由MapReduce调用执行。
- Hadoop:Hive的数据存储在HDFS中,针对大部分的HQL查询请求,Hive内部自动转换为MapReduce任务执行。
1.2 hive工作原理
Driver组件完成HQL查询语句从词法分析、语法分析、编译、优化、以及生成逻辑执行计划的生成。生成的逻辑执行计划存储在hdfs中,并随后由MapReduce调用执行。
最重要的结论:hive是基于Hadoop的数仓工具,把存储在hdfs上的结构化数据看做事一张二维表格,提供类似于SQL的操作方式,简化分布式应用程序的编写,底层实际上还是运行MapReduce程序,所以你在对Hive的SQL的优化的时候,一定要注意,你其实在优化MapReduce,而不是把MySQL中的SQL优化技巧生搬硬套上来。
2 hive性能调优
2.1 调优概述
Hive作为大数据领域常用的数据仓库组件,在平时设计和查询时要特别注意效率。影响Hive效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、Job或I/O过多、MapReduce分配不合理等等。对Hive的调优既包含Hive的建表设计方面,对HQL语句本身的优化,也包含Hive配置参数和底层引擎MapReduce方面的调整。
在具体调优方面,可以从以下一些角度考虑:
- Hive的建表设计
- HQL语法和运行参数层面
- Hive 架构层面
- Hive 数据倾斜
总之,Hive调优作用:在保证业务结果不变的前提下,降低资源的使用,减少任务的执行时间。
由于Hive底层的SQL其实运行的是MapReduce,不适用于MySQL调优。所谓的调优,在资源固定不变的情况下,不够才需要调优!一切调优都比不上直接增加资源。
2.2 调优须知
- 对于大数据计算引擎来说,数据量大不是问题,数据倾斜是个问题。
- Hive的复杂HQL底层会转换多个MapReduce并行或者串行,Job数比较多的作业运行效率相对比较低下。
- 在使用Hive进行数据分析时,常见的聚合操作比如sum、count、max、min、UDAF等,不怕数据倾斜问题,MapReduce在Mapper阶段预聚合操作,使数据倾斜不成问题。
- 好的建表设计,模型设计事半功倍。
- 设置合理的MapReduce的Task并行度,能有效提升性能。
- 了解数据的分布,自己动手解决数据倾斜问题是个不错的选择。除去通用的优化方式外,开发人员可以通过业务逻辑准确有效的解决数据倾斜问题。
- 数据量较大的情况下,慎用count(distinct),group by容易产生倾斜问题。
- 对小文件合并,是行之有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对任务的整体调度效率也会产生积极的正向影响。
- 优化时把握整体,单个作业最优不如整体最优。
- 优化MySQL的SQL技巧,真不一定适用于hive。
2.3 表设计层面调优
hive的建表设计层面调优,主要讲的怎么样合理的组织数据,方便后续的高效计算。
2.3.1 利用分区表进行优化
当一个hive表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建分区表,该字段即为分区字段。
注:实际开发过程中,可以以日期作为分区表的分区字段。
2.3.2 利用分桶表进行优化
当需要多个表进行join的时候,可以用到分桶表进行存储。 解决方案:
- 两个表都需要按照连接的key进行分桶
- 分桶数量需要成倍数关系
分区和分桶的本质类似,即把数据分成多个不同的类别,区别就是规则不一样,或者说划分数据的粒度不一样!
分区:按照key值进行,一个分区下,包括的是这个key下的所有记录。
分桶:按照key值进行hash散列,一个桶下存在多个不同的key。
2.3.3 选择合适的文件存储格式
存储格式一般需要根据业务进行选择,实际过程中,绝大多数表都采用TextFile与Parquet两种存储格式之一。TextFile是最简单的存储格式,它是纯文本记录,也是hive的默认格式,其磁盘开销比较大,查询效率低,但它更多地是作为跳板来使用。RCFile、ORC、Parquet等格式的表都不能由文件直接导入数据,必须用TextFile来做中转。
Parquet和ORC都是Apache旗下的开源列式存储格式。列式存储比起传统的行式存储更适合批量OLAP查询,并且也支持更好的压缩和编码。尤其是对于宽表,尽量使用ORC、Parquet这些列式存储格式。因为对于列式存储的表,每一列的数据在物理上是存储在一起的,hive查询时只会变量需要列数据,大大减少处理的时间。
注:这也是实际操作中从ods层开始,需要通过ORC进行存储的原因之一,压缩+列式存储(查询)。
2.3.4 选择合适的压缩格式
压缩算法适用于IO密集型任务,而不是计算密集型任务。hive底层是MapReduce执行,其性能瓶颈在网络IO和磁盘IO。因此数据压缩可以很好的提高任务执行速度,但是在压缩过程中需要消耗CPU。实际上,在任务执行过程中,CPU的压力并不大,数据压缩则充分利用率空闲的CPU。
常见的压缩算法包:gzip、lzo、snappy、bzip2。对于压缩方式的选择需要考虑压缩比率、压缩解压速度、是否支持split。通常一些压缩算法不支持数据分隔,只能从起始位置读。
2.4 HQL语法和运行层面
HQL语句和运行参数层面,主要说明如何写出高效的HQL,以及如何利用一些控制参数来调优HQL执行。这是HQL执行里面的一个点。
2.4.1 查看hive执行计划
使用explain查看执行计划,添加extended关键字可以查看更加详细的执行计划。逻辑执行计划是一个Operator Tree。其中select对应FetchOperator节点、from对应TableScanOperator节点、where+having对应FilterOperator。
2.4.2 裁剪操作
裁剪包括列裁剪和分区裁剪。列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区。当列很多或者数据量大时,如果select *或者不指定分区,全列扫描和全表扫描效率都很低。
在查询的过程中只选择需要的分区,可以减少读入的分区数目,减少读入的数据量。
2.4.3 合并小文件
大数据技术组件最怕的问题之二:存储组件--->海量小文件。
SQL需求:1000000M = 100000 * 10M 100000个小文件
Map输入合并
# Map端输入,合并文件之后按照block的大小分割(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
# Map端输入,不合并
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









