




 本文全面解析HashMap的工作原理,包括数组、链表、红黑树的优劣,深入探讨HashMap的内部结构、put方法、扩容机制及并发缺陷。并对比Java7与Java8的差异,以及ConcurrentHashMap的线程安全实现。
本文全面解析HashMap的工作原理,包括数组、链表、红黑树的优劣,深入探讨HashMap的内部结构、put方法、扩容机制及并发缺陷。并对比Java7与Java8的差异,以及ConcurrentHashMap的线程安全实现。
HashMap
第一部分:基础入门
1.数组的优劣
优:读取速度快,直接数组下标取出
劣:空间大小固定,不能扩展
2.链表的优劣
优:空间大小不固定,易插入
劣:只存头节点,索引速度很慢,需要遍历
3.4.散列表
数组中保存的数据是一个链表。
5.哈希

第二部分:HashMap原理讲解
1.HashMap的继承体系结构
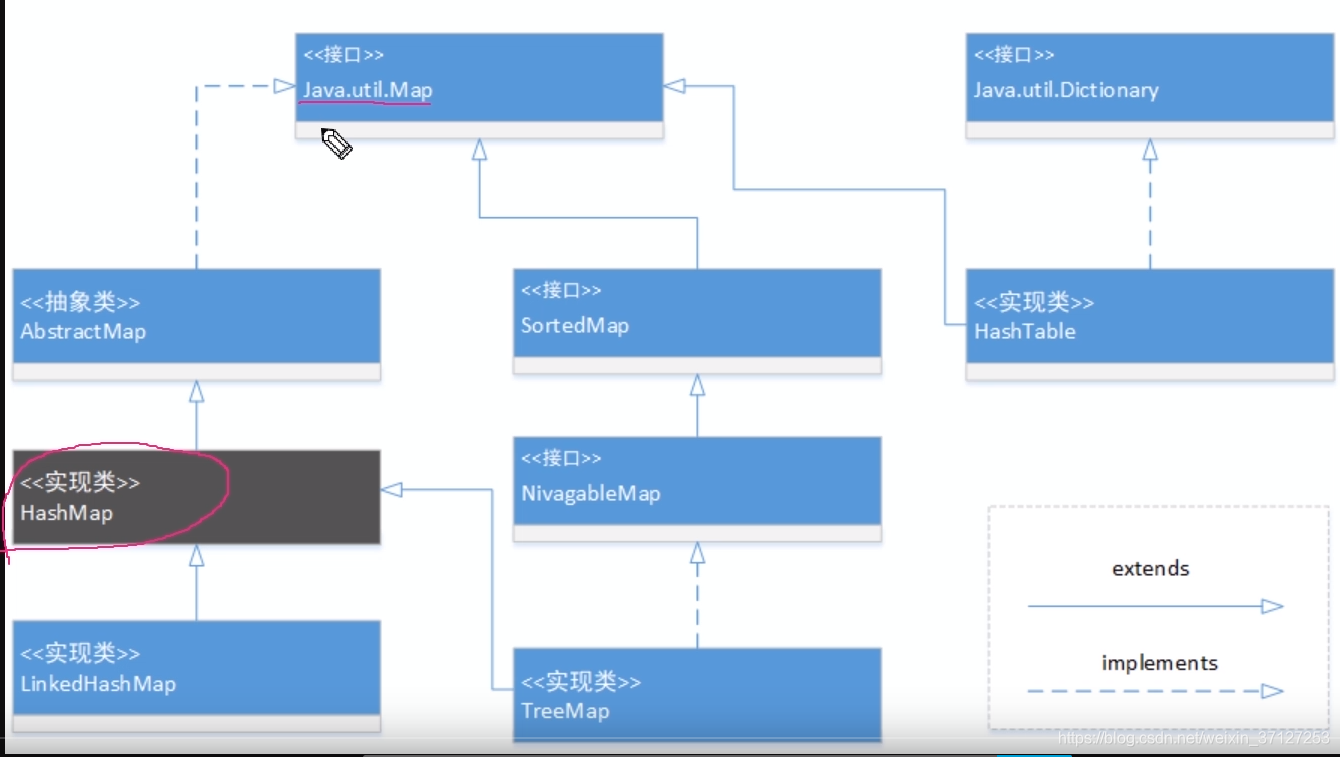
java8之前:HashMap是一个Entry对象的数组。数组中的每一个Entry元素,又是一个链表的头节点。
java8之后:是一个Node如下定义。
2.Node数据结构分析

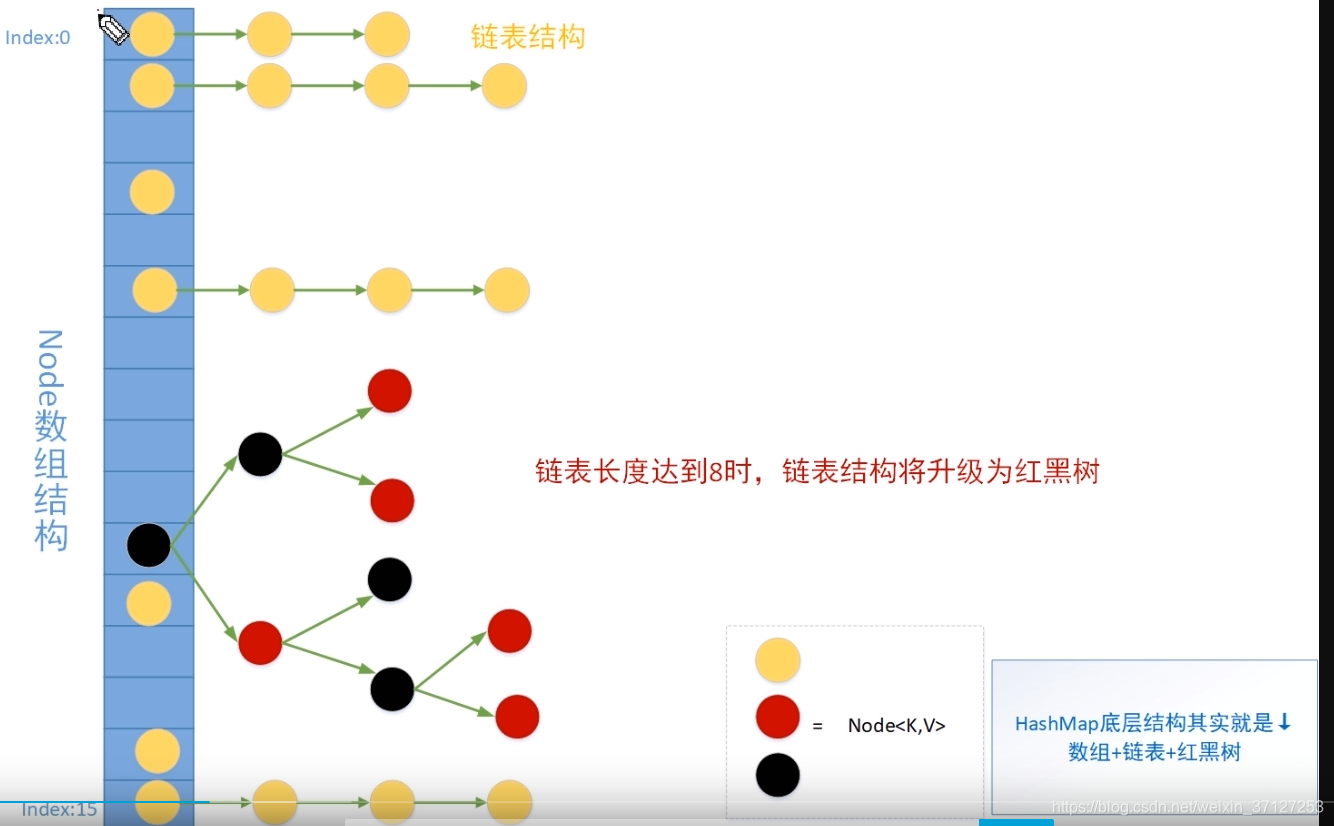
3.底层存储结构
默认数组长度16。
数组+链表+红黑树
jdk7以前 数组+链表 头插法(设计者认为后来的数据被查找的概率大) 有可能形成环。
第四小节有附加,讲解形成环,因为并发。
jdk8之后 数组+链表+红黑树 尾插法
4.put数据原理分析
5.Hash碰撞
两个Node节点的Hash出来的数组下标一致。
6.什么是链化
就是因为 Hash碰撞,节点开始以链表的形式存储,
7.jdk8为什么引入红黑树
解决链表长度过长,提高查找效率
8.扩容原理
空间换时间,提高查找效率。
第三部分:手撕源码
1.HashMap核心属性分析
1.为什么数组大小为2的倍数?
为了让一个元素的key经hash运算后落在数组范围内,且数据相对分散,肯定采用取模操作%。但是,“模”运算的消耗还是比较大的,源代码中采用了与运算的操作,hash值与len-1,这里只有当len为2的指数倍,才能出现h%len=h&(len-1)。让数据均于分布,若是其它数据会导致,某个值更容易出现,或者不会出现的情况。

为什么是16?只要是2的倍数都行。


2.负载因子为什么是0.75.
这个值是根据概率泊松分布得出,扩容size*0.75,即不会让数组中的值过度碰撞,造成查询时间复杂度的变大,也不会数组空间还很多就扩容。0.75时时间复杂度与空间复杂度上的一个平衡点。

树降级层链表默认值6.UNTREEIFY_THRESHOLD=6
3.什么时候树化
树化的另一个参数:当hash表中的所有元素个数超过64时,才会允许树化。MIN_TREEIFY_CAPACITY=64
当所有元素超过64且单个节点元素大于8,使用红黑树。

threshold=capacity*0.75
2.构造方法分析
2.1 4个构造方法:
2.1.1第一个:
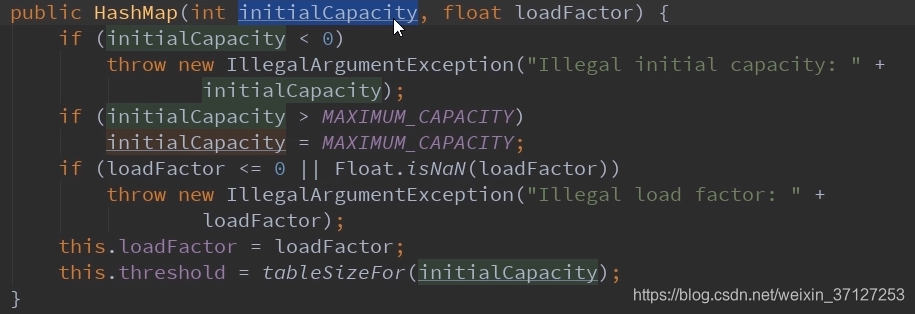
做了一些基本的初始合法校验。
最后一行的tableSizeFor方法,就是保证数组长度为2的次方,保证数组大小为最接近当前传入值(且大于)的一个值。

为什么这样操作就能是2的倍数。可以看这个链接为什么是2的倍数
核心思想:这样移动,就会让最高位1后,全部变为1,即为0x01111111的形式,然后return再加个1,自然变成0x10000000的形式,就为2的倍数了,且最接近给的值。
2.1.2第二个

2.1.3第三个

2.1.4第四个

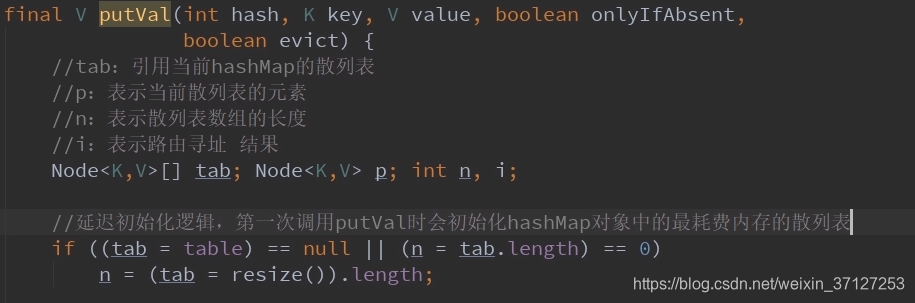
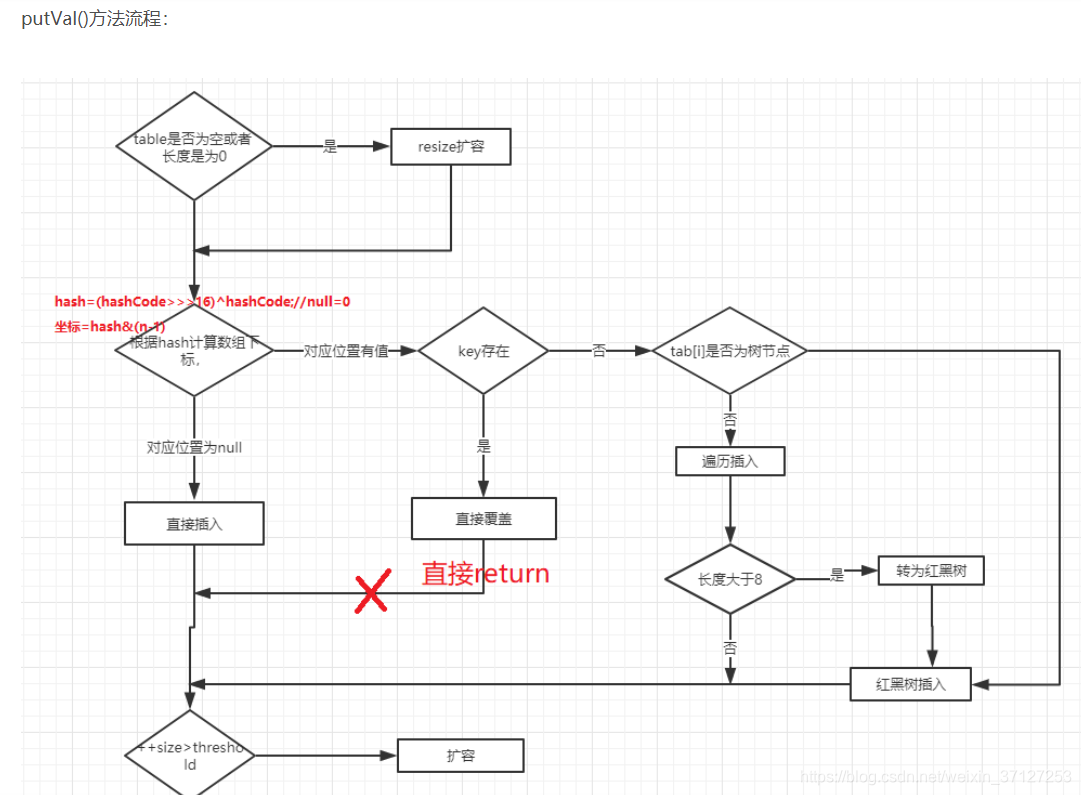
3.HashMap的put方法

put方法套的putval方法,里面又有个hash(key)
先看hash
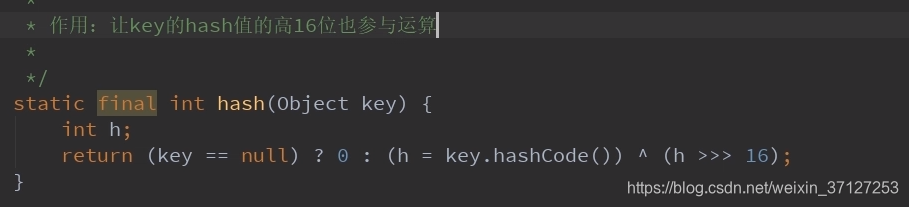
由函数可见:当key为null时,放在数组的0号位置。
让高16位也参与路由(求index)运算。
putval
4.扩容方法分析
什么时候扩容?
当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1024 < 1000, 也就是说为了让0.75 * capcity> 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
0.75*数组容量>你的现有元素个数
resize主要的两个步骤:
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash(并发情况下有可能形成链表环)
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
第四部分:附加
1.Hashmap并发下的缺陷
上面已经提到高并发下的rehash易形成一个链表环。
假设一个HashMap已经到了Resize的临界点。此时有两个线程A和B,在同一时刻对HashMap进行Put操作。就容易产生环。
链接:https://zhuanlan.zhihu.com/p/31614195 别忘记插入过程是头插。就好理解了。
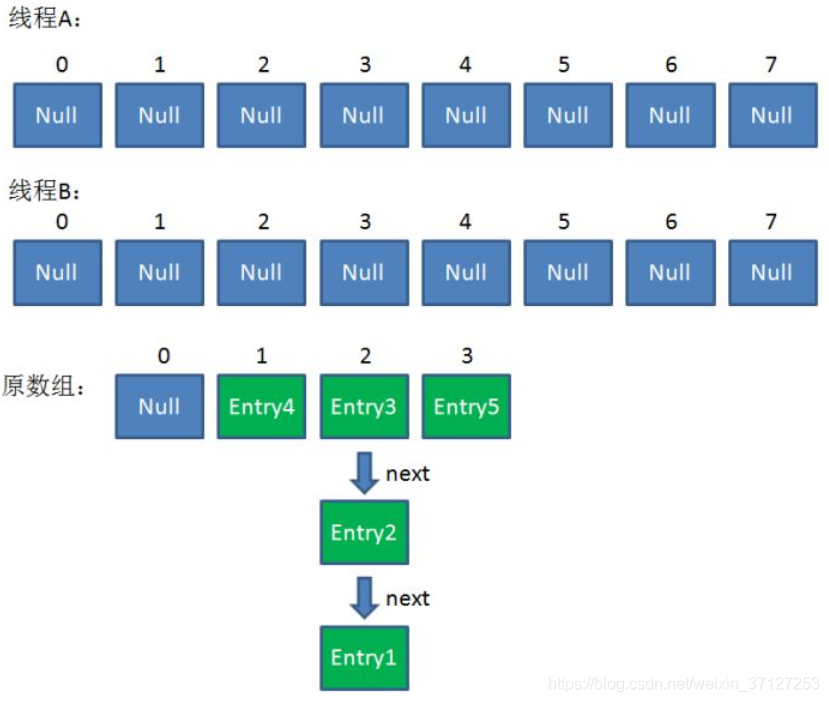
1.假设现在线程A,B同时插入两个值,均会触发扩容。
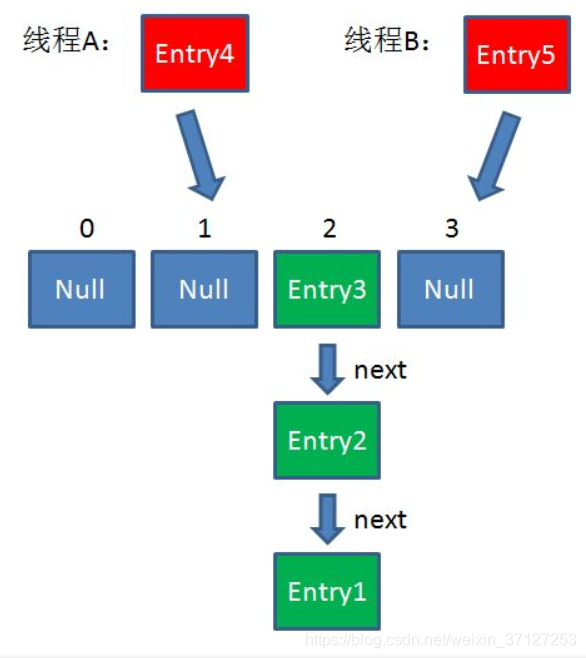
2.插入后扩容
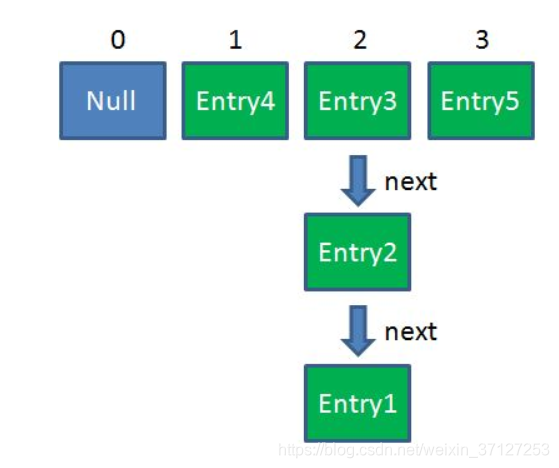
3.扩容完成,开始rehash。
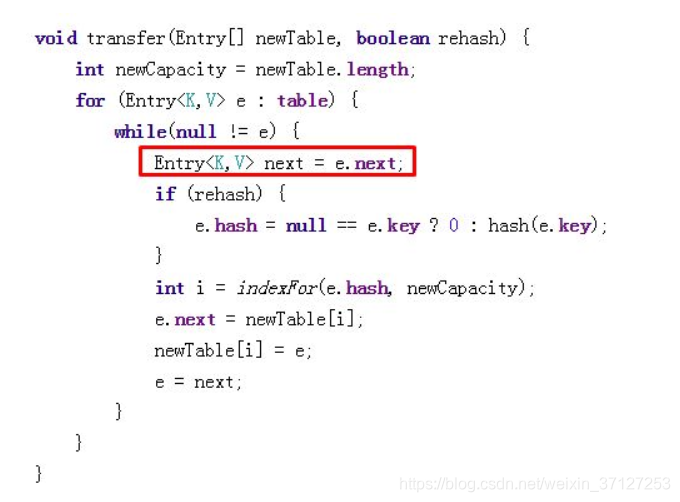
rehash代码:
4.现在假设线程B rehash 到,entry3,刚执行到上方红框处。此时源数据还在,
e=entry3;
e.next=entry2,现在线程B挂起,A开始畅通执行完毕。
5.线程A执行完毕情况,此时源数据已经不再,B再rehash是从A中取值。
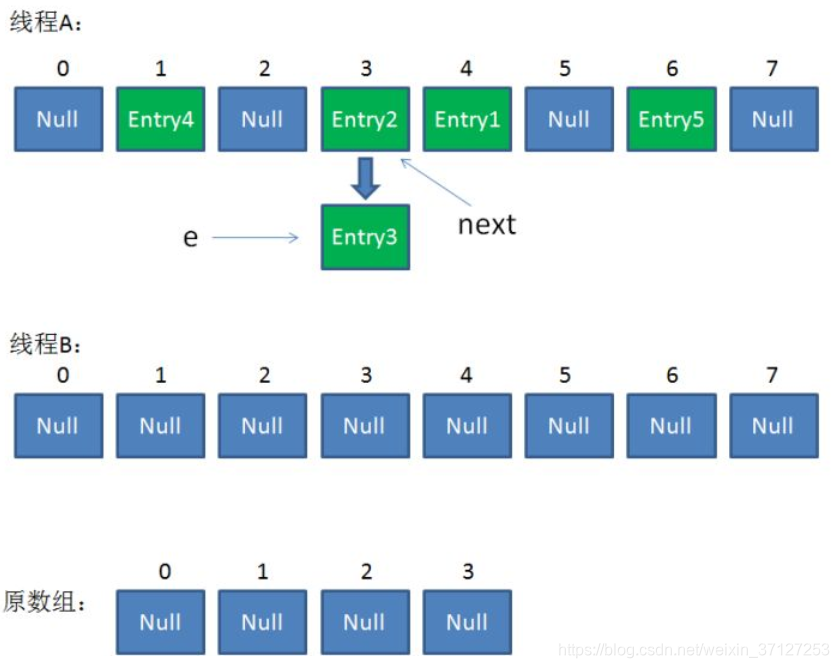
6.此时因为没有加锁,B接着上面,插入,插入entry3之后,开始插入entry2,entry2插入后,接着插入,开始读数据,此时读到的entry2.next为entry3,(而不是源数据中entry2.next=entry1),然而entry3早已插入,这样由于头插法就形成了个环。
这时若调用get一个不存在的值,它的key的hash正好为3,那么就会进入一个死循环。
为什么高并发情况下hashmap可能出现死循环。
2.jdk8中的不同
1.java8中链表节点的数据类型发生了改变,Entry变为Node,因为java8中引入了而红黑树。
java7 transient Entry<k,v>[] table
java8 transient Node<k,v>[] table
2.通过红黑树让查询更有效率(O(n)—>O(Log(n)))
3.让扩容时重哈希(rehash)的成本变得更小
因为定位操作是与运算,只要看原hash值的高一位是1还是0,是0就不动,是1就加oldcap。
扩容后的元素要么在原位置,要么在原位置再移动2次幂的位置,整个过程只需要使用一个**位运算符<<**就可以了。我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,

整个过程梳理
3.什么是ConcurrentHashMap
看见一个讲ConcurrentHashMap比较详细的博客,可以参考
想要避免HashMap的线程安全问题有很多办法,改用HashTable或者Collections.synchronizedMap.但是性能差,无论读操作还是写操作都加锁,(读操作没必要加锁,JUC中的读写锁),给整个的集合都加锁,导致其他线程阻塞。
ConcurrentHashMap怎么保证线程安全?怎么实现高性能的读写?与Hasp对比的特别之处
segment
分段:同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。ConcurrentHashmap采用锁分段技术,每个segment读写高度自治,互不影响。
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。 ``
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
从上述可知,ConcurrentHashMap在读写时需要二次定位。首先定位Segment再定位数组下标。
缺点:Size方法
ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。


















 4846
4846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









