







欢迎来到 雲闪世界。当你在某个领域工作足够长的时间后,你会永远记住一些课程、概念、课程和老师。
例如,我妈妈是一名教师,她记得那位让她第一次爱上哲学的代课老师。
我的跆拳道师傅永远记得他小时候上的第一堂跆拳道课,以及他内心的兴奋。
我是一名机器学习工程师。从专业上来说,机器学习是我最喜欢的东西,也可能是我最了解的学科。
我永远记得的一堂课是,我读本科期间的第一位机器学习教授描述了分类和回归之间的区别。分类任务的一个例子是根据电子邮件的文本识别它是否是垃圾邮件。回归任务的一个例子是根据房屋的特征(例如大小、位置等)预测房屋的价格。
我们将一组特征定义为具有 k 列和 n 行的矩阵(表)X 。在分类和回归任务中,输出都是具有 n 个条目(与X的行数相同)的向量y 。不同之处在于,在分类任务中, y 的条目是整数。参考前面的示例,y_1=0表示第一封电子邮件不是垃圾邮件,y_1=1表示第一封电子邮件是垃圾邮件。在回归任务中, y的条目是实数。参考房价示例,y_1 = 123780表示我们要预测的 1 号房子的价格为 123780。
现在,回归任务可以用多种方式来解决。实际上,有很多种方式……也许有太多方式无法处理。如果我们有这么多方法来解决一个问题,那么选择正确的方法可能非常困难。随着人工智能和点击诱饵标题的爆炸式增长,选择最佳方法变得越来越困难,因为许多文章和论文声称对每个回归问题都有最终解决方案(购买我的课程即可获得待售代码!!!)。
事实是,每个数据集都应该用特定的算法来解决,这取决于数据的特定属性和我们想要实现的特定要求。
这篇博文旨在为用户提供一份友好的指南,指导您如何使用最佳的回归任务:
- 数据集的线性/多项式线性
- 数据集的复杂性
- 数据集的维数(列数)
- 需要概率 输出
为了本研究,我们将只考虑传统的机器学习方法(没有神经网络),因为我们主要关注小型合成数据集。
你准备好摇滚了吗?🎸
我们开始吧。
1. 回归分类法
这是我们可以在回归任务中使用的“经验法则”分类法:
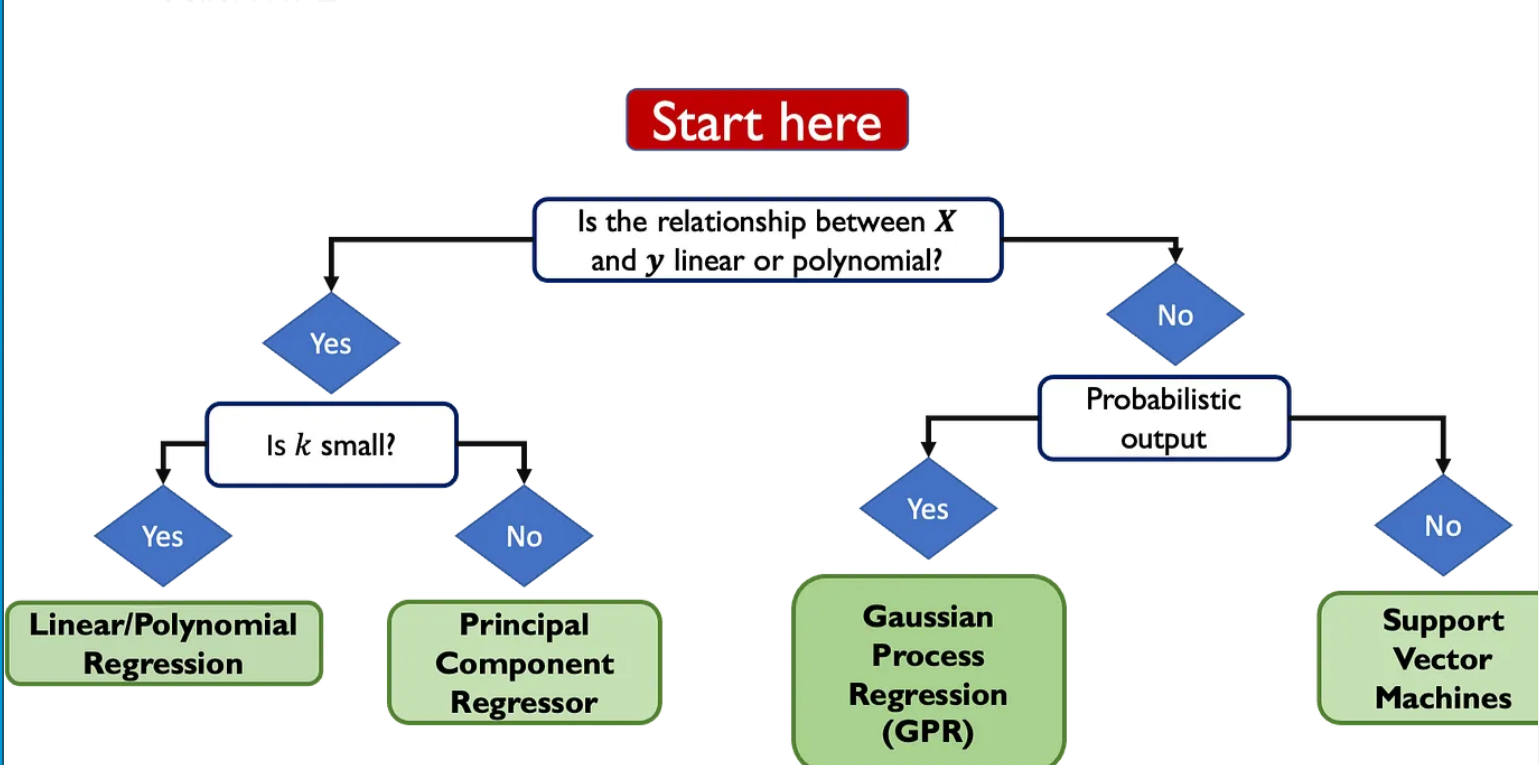
或者,用文字表达:
X 和 y 之间的关系是线性的还是多项式的?
是的:
k 是否很小?(其中 k 表示预测变量的数量)
是:使用线性/多项式回归。
否:使用主成分回归量。
不:
需要概率输出吗?
是:使用高斯过程回归(GPR)。
否:使用支持向量机(SVM)。
在本文中,我将首先用文字描述每一种方法,然后使用 Python。
2.线性/多项式回归
让我们从线性/多项式回归开始。
图片由作者制作
2.1 解释
这可以说是我们所拥有的最简单的回归情况,并且当我们的输入矩阵X与我们想要的目标(输出)Y线性相关时就会发生这种情况。
换句话说,如果我们有X矩阵 并且想要找到Y,我们的估计将是:
其中W是权重矩阵,w_0 是所谓的截距。
关于是否将此方法视为机器学习方法或仅仅是统计解决方案,存在很多争论。这是因为最佳权重矩阵W(和截距 w_0)是通过称为最优最小二乘法 (OLS)的方法找到的。该方法为我们提供了一个非常简单的W最佳值方程,即:
因此,最佳权重集不是通过迭代或数值方法求解的(就像在标准机器学习方法中一样)。
因此,这种方法可以被视为一种纯统计的、非常简单的方法。尽管它很简单,但当输入和输出通过线性或多项式依赖关系相关时,该方法对于线性和多项式情况都非常有效。
对于多项式依赖关系,我们可以应用上面看到的相同方程,但我们需要将X转换为多项式特征矩阵。这意味着在X中创建额外的列,表示原始特征(例如 X²、X³ 等)的幂,直到达到所需的多项式次数。
2.2 代码
有很多笔记本详细解释了线性回归,从头开始实现线性回归是一项非常好的练习。
话虽如此,线性和多项式回归的代码都非常简单。
对于线性回归
- 模拟X阵列(从1到20,100个点)
- 模拟相应的Y数组
- 从sklearn调用LinearRegression对象
- 进行绘图和打印可视化
对于多项式回归,唯一的不同之处在于 1 和 2 之间有一个额外的步骤,其中矩阵X被转换为矩阵X_poly,其中X_poly = [X,X², X³ ..., X^k]。
正如我们已经说过的,我们本质上是在多项式数据上训练线性模型。这是 3 次多项式的示例:
以下是剧情:
3. 主成分回归器
图片由作者制作
3.1 解释
现在,在某些情况下,您的数据集具有大量列(维度),我们称之为“ k ”。
在这种情况下(或 k-ase?哈哈),也许您的目标Y与数据集的主成分分析* (PCA)成分相关。
*主成分分析 (PCA) 是一种广泛使用的降维技术,它可以识别数据变化最大的方向(主成分)。它将原始变量转换为一组不相关的新正交变量(主成分),有效地降低维数,同时保留数据中的大部分方差。我在 本文中根据实践经验讨论了 PCA 。
例如,让我们以 k=2 的情况为例。我知道这有点奇怪,因为这种方法通常用于较大的 k,但我这样做只是因为可视化 2D 图比可视化 1000D 图更容易 :)
3.2 代码
因此,在这种二维情况下,假设第一维与第二维线性相关,如下所示:
现在我们要做的就是在这个 2D 数据集上拟合 PCA。我们可以用几行代码来完成:
- 从 sklearn 调用 PCA
- 在数据集X上进行拟合
- 转换数据集并将结果存储在另一个变量X_PCA中
这就是情节,我们现在可以看到这两个变量并不相关(如果 PCA 做得好的话就应该是这样的):
现在在这个玩具例子中,让我们考虑目标Y与 PCA 分量 2 相关的情况。在这种情况下,如果我们只是尝试进行线性回归,我们就会失败(正如年轻人所说),因为它看起来像这样:
不可能从这个坏家伙那里得到任何线性回归。
尽管如此,如果我们绘制 PCA 分量与Y 的关系图,我们会立即看到一些我们非常喜欢的东西:
组件 PCA 2 与我们的目标 Y 之间存在明显的关系。
这意味着我们可以轻松地对单个变量(k'=1)而不是 k=2 个变量进行线性回归。
我们是这样做的:
这就是剧情。比以往更顺畅 :)
4.高斯过程回归器
图片由作者制作
4.1 解释
我妻子总是说“小心谨慎总比事后后悔好”:有时你不仅想要给定X时目标Y的预测,还想要预测的不确定性。换句话说,我们希望有一些边界,我们知道我们可以自信地找到我们的预测。
一种方法是高斯过程回归 (GPR)。 “高斯过程”是随机变量的集合。这些随机变量遵循联合高斯分布。
我们如何使用这些联合高斯分布?通过对训练集中观察到的目标进行调节,可以从 n 个训练案例和测试案例的输出的 n + 1 维联合高斯分布中获得新变量x_test的预测分布。
我在这篇博文中讨论了高斯过程回归。
4.2 代码
一切都可以用几行代码完成:
现在,正如您所看到的,输入不是线性和/或多项式,但可以使用高斯过程回归进行建模,因此该方法也可以用于非线性预测。
GPR 尤其以选择最佳核的复杂性而闻名,从统计学角度来说,最佳核就是我们用来计算预测的矩阵的协方差。有关如何选择最佳核的指南可 在此处找到。
5.支持向量回归器(SVR)
图片由作者制作
5.1 解释
支持向量回归(SVR)大量用于输入和输出关系非线性且复杂的情况。
SVR 和支持向量机 (SVM) 的一般特性是,它们使用边际概念作为我们所做的预测的置信度。让我进一步解释一下。
让我们考虑一种分类算法,其中您使用一条线来区分 A 类元素和 B 类元素。假设我给您这条线,该线右侧的所有内容都归类为“A”,而该线左侧的所有内容都归类为“B”。现在,如果某个点非常靠近该线(左侧或右侧),则对其进行分类将非常危险,因为左侧或右侧的微小变化都会完全改变对象的预测类别。简而言之,您不希望您的决策幅度很小。
SVR 的理念是增加该裕度,以便您尽可能地确信所预测的值。SVR 可以高效处理高维数据,并且可以使用不同的核函数(例如线性、多项式和径向基函数核)进行定制,以捕获数据中复杂的非线性关系。
5.2 代码
对于X和Y之间非常复杂的关系,SVR 的代码如下:
图片由作者制作
我们可以看到,SVR 在正确猜测这种行为方面做得相当不错:
6. 其他方法
我想坦白地说:这个分类法很简洁。因为简洁,所以它不可能很长,也不可能全面涵盖所有方法(要做到这一点需要一篇 15 页以上的论文)。
我想给你另外三种执行回归任务的方法,这样你就知道还有更多的方法:
- XGBoost 回归器。这是一个非常流行的回归器,它使用增强框架,其中模型按顺序进行训练。每个新模型都会尝试纠正先前模型所犯的错误。
- 决策树和随机森林。决策树根据特征值将数据分成子集,形成用于预测的树结构。随机森林通过组合来自多个随机树的预测来提高准确性。众所周知,随机森林可以防止过度拟合。
- 神经网络。这是众所周知的,每天都会出现在新闻中 :) 神经网络由相互连接的节点层组成,可以学习复杂的模式,使其能够灵活地用于在回归任务中建模非线性关系。
7. 结论
在这篇博文中,我们讨论了回归方法。具体来说,我们做了以下事情:
- 我们描述了回归和分类之间的区别。
- 我们确定了确定最佳回归算法需要考虑的事项。
- 我们根据问题的复杂性、输入的列数(特征)以及概率输出的需求建立了分类法。
- 我们通过示例和编码练习描述了线性/多项式回归方法、高斯过程回归、支持向量机和主成分回归器。
- 我们简要描述了其他针对上下文的回归方法。
- 感谢关注
- 订阅频道(https://t.me/awsgoogvps_Host) TG交流群(t.me/awsgoogvpsHost)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









