



 本文详述了Linux下的各种实用命令,如VIM、lsof、top等,涵盖了文件操作、进程管理、资源监控等多个方面。深入解析了进程创建、调度、锁机制以及零拷贝技术等核心概念,是Linux系统管理和开发人员的必备指南。
本文详述了Linux下的各种实用命令,如VIM、lsof、top等,涵盖了文件操作、进程管理、资源监控等多个方面。深入解析了进程创建、调度、锁机制以及零拷贝技术等核心概念,是Linux系统管理和开发人员的必备指南。
一:基本命令
1. VIM
(1)打开与退出
vi fle:打开文件 file
:q :退出 vi 编辑器
:wq:保存缓冲区的修改并退出编辑器
:q!:不保存直接退出
:w 保存缓冲区内容至默认的文件
:w file 保存缓冲区内容至 file 文件
(2)插入文本
a(append) : 在当前光标的右边插入文本
A : 在当前光标行的末尾插入文本
i (insert): 在当前光标的左边插入文本
I : 在当前光标所在行的开始处插入文本
o: 在当前行在下面新建一行
O:在当前行的上面新建一行
R:替换当前光标位置以及以后的若干文本
J:连接光标所在行和下一行
(3)删除文本
x: 删除一个字符
d: 删除一行并保存到缓冲区中,可以通过p或P访问缓冲区
nd: 删除 n 行
u: 撤销上一次操作
U: 撤销对当前行的所有操作
(4) 搜索
/word 从前向后搜索第一个出现的 word
?word 从后向前搜索第一个出现的 word
(5) 设置行号
:set nu 在屏幕上显示行号
:set nou 取消行号
(6)复制黏贴
y: 复制一行文本到缓冲区中
p:把缓冲区的内容放在当前光标之上
P:把缓冲区的内容放在当前光标之下
2. lsof
查看占用端口的进程:Isof -i 端口号
查看进程打开了哪些文件:lsof -p -pid
3. top
top -p 进程id 查看具体的进程的内存占用
top -u 用户名 查看用户的进程内存
输入 top 后出来数据了 然后输入 M 按照内存排序,输入 P 按照 CPU 排序 输入T 按照占用 CPU 的时间排序
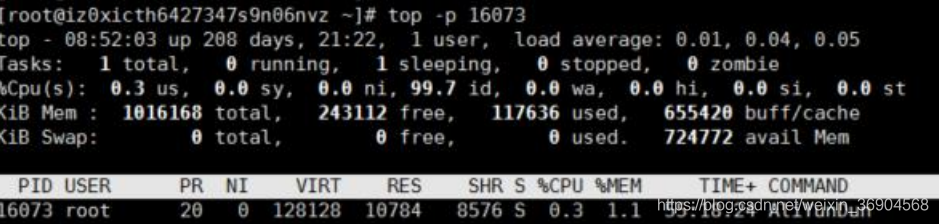
PID:进程的 ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S 表示休眠,R 表示正在运行,Z 表示僵死状态,N 表示该进程优先值为负数
%CPU:进程占用 CPU 的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的 CPU 时间,即占用 CPU 使用时间的累加值。
COMAND:进程启动命令名称
top -Hp 进程 ID:查看进程下的线程
4. 其他命令
查看一个服务器是否正常运作 ps aux
查看CPU 使用率:top命令、/proc/stat cpu
查看占用 cpu 最高的进程 ps aux|head -1、ps aux|grep -v PID|sort -rn -k +3|head
查看内存使用率:free命令、/proc/meminfo
查看占用内存最高的进程 ps aux|head -1、ps aux|grep -v PID|sort -rn -k +4|head
查看磁盘使用情况:df -h
查看网络信息:Netstat命令
查看进程端口号:netstat - apn | grep 端口号(grep -v(逐层过滤) -e(正则表达式))
查看带宽:nload
查看IO:IOTOP
查看最后登录信息:/var/log/wtmp
查看系统和服务的错误信息:var/log/message(centos)、var/log/syslog(ubuntu)
创建用户命令 aduser 用户名
查看进程的运行堆栈信息命令 gstack 进程 id
5. 查看行数指令



6. free
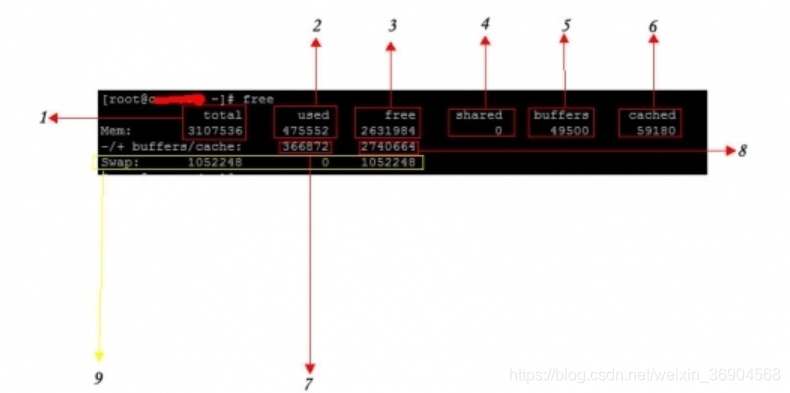
1,total:物理内存实际总量
2,used:这块千万注意,这里可不是实际已经使用了的内存哦,这里是总计分配给缓存(包含 bufers 与 cache )使用的数量,但其中可能部分缓存并未实际使用。
3,free:未被分配的内存
4,shared:共享内存
5,buffers:系统分配的,但未被使用的 buffer 剩余量
6,cached:系统分配的,但未被使用的 cache 剩余量。
7,buffers/cache used:这个是 buffers 和 cache 的使用量,也就是实际内存的使用量
8, buffers/cache free:未被使用的 buffers 与 cache 和未被分配的内存之和,这就是系统当前实际可用内存,包括 free(未分配的和)
9,swap:交换分区总量,使用量,剩余量
cache 和 buffer 的区别:
- Cache:高速缓存,是位于 CPU 与主内存间的一种容量较小但速度很高的存储器。是为了提高 cpu 和内存之间的数据交换速度而设计的。由于 CPU的速度远高于主内存,CPU 直接从内存中存取数据要等待一定时间周期,Cache 中保存着 CPU 刚用过或循环使用的一部分数据,当 CPU 再次使用该部分数据时可从 Cache 中直接调用,这样就减少了CPU 的等待时间,提高了系统的效率。
- Bufer:缓冲区,主要存在于 RAM 中,作为 CPU 暂时存储数据的区域。一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域,是为了提高内存和I/O 设备之间的数据交换的速度而设计的。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
- Swap:读取数据到内存,内存不够用,这时候把部分内存中的数据写入到磁盘上,这部分磁盘空间就是 swap
Free 中的 buffer 和 cache:(它们都是占用内存):
- buffer : 作为 bufer cache 的内存,是块设备的读写缓冲区
- cache: 作为 page cache 的内存, 文件系统的 cache。如果 cache 的值很大,说明 cahe 住的文件数很多。如果频繁访问到的文件都能被 cache 住,那么磁盘的读 IO 必会非常小。
7. grep,sed ,awk
grep 命令 :强大的文本’搜索’工具
sed :实现数据的替换,删除,增加,选取等(以行为单位进行处理)
awk : 以字段为单位进行处理(其实就是把一行的数据分割,然后进行处理)
8. 基本命令
端口监听查看:
- ss -tln 查看TCP的listen的端口
- ss -tlnp 查看哪些进程使用了监听端口
防火墙:
- systemctl status iptables (或service iptables status) 查看防火墙状态
- systemctl stop iptables(或service iptables stop) 关闭防火墙
ps命令常用用法(方便查看系统进程)
- ps a 显示现行终端机下的所有程序,包括其他用户的程序。
- ps -A 显示所有进程。
- ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
- ps -e 此参数的效果和指定"A"参数相同。
- ps e 列出程序时,显示每个程序所使用的环境变量。
- ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
- ps -H 显示树状结构,表示程序间的相互关系。
- ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
- ps s 采用程序信号的格式显示程序状况。
- ps S 列出程序时,包括已中断的子程序资料。
- ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
- ps u 以用户为主的格式来显示程序状况。
- ps x 显示所有程序,不以终端机来区分。
常用指令组合 :ps aux,然后再通过管道使用grep命令过滤查找特定的进程,然后再对特定的进程进行操作。
-
ps aux | grep program_filter_word,ps -ef |grep tomcat
-
ps -ef|grep java|grep -v grep 显示出所有的java进程,去处掉当前的grep进程。
关机 (系统的关机、重启以及登出 )
- shutdown -h now 关闭系统(1)
- init 0 关闭系统(2)
- telinit 0 关闭系统(3)
- shutdown -h hours:minutes & 按预定时间关闭系统
- shutdown -c 取消按预定时间关闭系统
- shutdown -r now 重启(1)
- reboot 重启(2)
- logout 注销
文件和目录
- cd /home 进入 ‘/ home’ 目录’
- cd … 返回上一级目录
- cd …/… 返回上两级目录
- cd 进入个人的主目录
- cd ~user1 进入个人的主目录
- cd - 返回上次所在的目录
- pwd 显示工作路径
- ls 查看目录中的文件
- ls -F 查看目录中的文件
- ls -l 显示文件和目录的详细资料
- ls -a 显示隐藏文件
- ls [0-9] 显示包含数字的文件名和目录名
- tree 显示文件和目录由根目录开始的树形结构(1)
- lstree 显示文件和目录由根目录开始的树形结构(2)
- mkdir dir1 创建一个叫做 ‘dir1’ 的目录’
- mkdir dir1 dir2 同时创建两个目录
- mkdir -p /tmp/dir1/dir2 创建一个目录树
- rm -f file1 删除一个叫做 ‘file1’ 的文件’
- rmdir dir1 删除一个叫做 ‘dir1’ 的目录’
- rm -rf dir1 删除一个叫做 ‘dir1’ 的目录并同时删除其内容
- rm -rf dir1 dir2 同时删除两个目录及它们的内容
- mv dir1 new_dir 重命名/移动 一个目录
- cp file1 file2 复制一个文件
- cp dir/* . 复制一个目录下的所有文件到当前工作目录
- cp -a /tmp/dir1 . 复制一个目录到当前工作目录
- cp -a dir1 dir2 复制一个目录
- ln -s file1 lnk1 创建一个指向文件或目录的软链接
- ln file1 lnk1 创建一个指向文件或目录的物理链接
- touch -t 0712250000 file1 修改一个文件或目录的时间戳 - (YYMMDDhhmm)
- file file1 将文件的mime类型输出为文本
- iconv -l 列出已知的编码
- iconv -f fromEncoding -t toEncoding inputFile > outputFile 通过假设给定输入文件的编码方式,从该输入文件创建新文件的并把它转换成目标编码
- find . -maxdepth 1 -name *.jpg -print -exec convert “{}” -resize 80x60 “thumbs/{}” ; 批量调整当前目录中的文件尺寸并将其发送到缩略图目录
文件搜索
- find / -name file1 从 ‘/’ 开始进入根文件系统搜索文件和目录
- find / -user user1 搜索属于用户 ‘user1’ 的文件和目录
- find /home/user1 -name *.bin 在目录 ‘/ home/user1’ 中搜索带有’.bin’ 结尾的文件
- find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
- find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
- find / -name *.rpm -exec chmod 755 ‘{}’ ; 搜索以 ‘.rpm’ 结尾的文件并定义其权限
- find / -xdev -name *.rpm 搜索以 ‘.rpm’ 结尾的文件,忽略光驱、捷盘等可移动设备
- locate *.ps 寻找以 ‘.ps’ 结尾的文件 - 先运行 ‘updatedb’ 命令
- whereis halt 显示一个二进制文件、源码或man的位置
- which halt 显示一个二进制文件或可执行文件的完整路径
磁盘空间
- df -h 显示已经挂载的分区列表
- ls -lSr |more 以尺寸大小排列文件和目录
- du -sh dir1 估算目录 ‘dir1’ 已经使用的磁盘空间’
- du -sk * | sort -rn 以容量大小为依据依次显示文件和目录的大小
- rpm -q -a --qf ‘%10{SIZE}t%{NAME}n’ | sort -k1,1n 以大小为依据依次显示已安装的rpm包所使用的空间 (fedora, redhat类系统)
- dpkg-query -W -f=’ $ {Installed-Size;10}t${Package}n’ | sort -k1,1n 以大小为依据显示已安装的deb包所使用的空间 (ubuntu, debian类系统)
用户和群组
- groupadd group_name 创建一个新用户组
- groupdel group_name 删除一个用户组
- groupmod -n new_group_name old_group_name 重命名一个用户组
- useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 “admin” 用户组的用户
- useradd user1 创建一个新用户
- userdel -r user1 删除一个用户 ( ‘-r’ 排除主目录)
- usermod -c “User FTP” -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
- passwd 修改口令
- passwd user1 修改一个用户的口令 (只允许root执行)
- chage -E 2005-12-31 user1 设置用户口令的失效期限
- pwck 检查 ‘/etc/passwd’ 的文件格式和语法修正以及存在的用户
- grpck 检查 ‘/etc/passwd’ 的文件格式和语法修正以及存在的群组
- newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
文件的权限 - 使用 “+” 设置权限,使用 “-” 用于取消
- ls -lh 显示权限
- ls /tmp | pr -T5 -W$COLUMNS 将终端划分成5栏显示
- chmod ugo+rwx directory1 设置目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限
- chmod go-rwx directory1 删除群组(g)与其他人(o)对目录的读写执行权限
- chown user1 file1 改变一个文件的所有人属性
- chown -R user1 directory1 改变一个目录的所有人属性并同时改变改目录下所有文件的属性
- chgrp group1 file1 改变文件的群组
- chown user1:group1 file1 改变一个文件的所有人和群组属性
- find / -perm -u+s 罗列一个系统中所有使用了SUID控制的文件
- chmod u+s /bin/file1 设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限
- chmod u-s /bin/file1 禁用一个二进制文件的 SUID位
- chmod g+s /home/public 设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的
- chmod g-s /home/public 禁用一个目录的 SGID 位
- chmod o+t /home/public 设置一个文件的 STIKY 位 - 只允许合法所有人删除文件
- chmod o-t /home/public 禁用一个目录的 STIKY 位
打包和压缩文件
- bunzip2 file1.bz2 解压一个叫做 'file1.bz2’的文件
- bzip2 file1 压缩一个叫做 ‘file1’ 的文件
- gunzip file1.gz 解压一个叫做 'file1.gz’的文件
- gzip file1 压缩一个叫做 'file1’的文件
- gzip -9 file1 最大程度压缩
- rar a file1.rar test_file 创建一个叫做 ‘file1.rar’ 的包
- rar a file1.rar file1 file2 dir1 同时压缩 ‘file1’, ‘file2’ 以及目录 ‘dir1’
- rar x file1.rar 解压rar包
- unrar x file1.rar 解压rar包
- tar -cvf archive.tar file1 创建一个非压缩的 tarball
- tar -cvf archive.tar file1 file2 dir1 创建一个包含了 ‘file1’, ‘file2’ 以及 'dir1’的档案文件
- tar -tf archive.tar 显示一个包中的内容
- tar -xvf archive.tar 释放一个包
- tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp目录下
- tar -cvfj archive.tar.bz2 dir1 创建一个bzip2格式的压缩包
- tar -xvfj archive.tar.bz2 解压一个bzip2格式的压缩包
- tar -cvfz archive.tar.gz dir1 创建一个gzip格式的压缩包
- tar -xvfz archive.tar.gz 解压一个gzip格式的压缩包
- zip file1.zip file1 创建一个zip格式的压缩包
- zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
- unzip file1.zip 解压一个zip格式压缩包
看文件内容
- cat file1 从第一个字节开始正向查看文件的内容
- tac file1 从最后一行开始反向查看一个文件的内容
- more file1 查看一个长文件的内容
- less file1 类似于 ‘more’ 命令,但是它允许在文件中和正向操作一样的反向操作
- head -2 file1 查看一个文件的前两行
- tail -2 file1 查看一个文件的最后两行
- tail -f /var/log/messages 实时查看被添加到一个文件中的内容
文本处理
- cat file1 file2 … | command <> file1_in.txt_or_file1_out.txt general syntax for text manipulation using PIPE, STDIN and STDOUT
- cat file1 | command( sed, grep, awk, grep, etc…) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中
- cat file1 | command( sed, grep, awk, grep, etc…) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
- grep Aug /var/log/messages 在文件 '/var/log/messages’中查找关键词"Aug"
- grep ^Aug /var/log/messages 在文件 '/var/log/messages’中查找以"Aug"开始的词汇
- grep [0-9] /var/log/messages 选择 ‘/var/log/messages’ 文件中所有包含数字的行
- grep Aug -R /var/log/* 在目录 ‘/var/log’ 及随后的目录中搜索字符串"Aug"
- sed ‘s/stringa1/stringa2/g’ example.txt 将example.txt文件中的 “string1” 替换成 “string2”
- sed ‘/^$/d’ example.txt 从example.txt文件中删除所有空白行
- sed ‘/ *#/d; /^$/d’ example.txt 从example.txt文件中删除所有注释和空白行
- echo ‘esempio’ | tr ‘[:lower:]’ ‘[:upper:]’ 合并上下单元格内容
- sed -e ‘1d’ result.txt 从文件example.txt 中排除第一行
- sed -n ‘/stringa1/p’ 查看只包含词汇 "string1"的行
- sed -e ‘s/ *$//’ example.txt 删除每一行最后的空白字符
- sed -e ‘s/stringa1//g’ example.txt 从文档中只删除词汇 “string1” 并保留剩余全部
- sed -n ‘1,5p;5q’ example.txt 查看从第一行到第5行内
- sed -n ‘5p;5q’ example.txt 查看第5行
- sed -e ‘s/00*/0/g’ example.txt 用单个零替换多个零
- cat -n file1 标示文件的行数
- cat example.txt | awk ‘NR%2==1’ 删除example.txt文件中的所有偶数行
- echo a b c | awk ‘{print $1}’ 查看一行第一栏
- echo a b c | awk ‘{print $1,$3}’ 查看一行的第一和第三栏
- paste file1 file2 合并两个文件或两栏的内容
- paste -d ‘+’ file1 file2 合并两个文件或两栏的内容,中间用"+"区分
- sort file1 file2 排序两个文件的内容
- sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
- sort file1 file2 | uniq -u 删除交集,留下其他的行
- sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
- comm -1 file1 file2 比较两个文件的内容只删除 ‘file1’ 所包含的内容
- comm -2 file1 file2 比较两个文件的内容只删除 ‘file2’ 所包含的内容
- comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
二:Linux 守护进程
- 创建子进程,父进程退出:经过这步以后,子进程就会成为孤儿进程。使用 fork()函数,如果返回值大于 0,表示为父进程,exit(0),父进程退出,子进程继续。
- 在子进程中创建新会话,使当前进程成为新会话组的组长:使用 setid()函数,如果当前进程不是进程组的组长,则为当前进程创建一个新的会话期,使当前进程成为这个会话组的首进程,成为这个进程组的组长。
- 改变当前目录为根目录:由于守护进程在后台运行,开始于系统开启,终止于系统关闭,所以要将其目录改为系统的根目录下。进程在执行时,其文件系统不能被卸下。
- 重新设置文件权限掩码:进程从父进程那里继承了文件创建掩码,所以可能会修改守护进程存取权限位,所以要将文件创建掩码清除,umask(0);
- 关闭文件描述符:子进程从父进程那里继承了打开文件描述符。所以使用 close 即可关闭
三:Linux 管道机制原理
实际上,管道是一个固定大小的缓冲区。在 Linux 中,该缓冲区的大小为 1 页,即 4K 字节,使得它的大小不象文件那样不加检验地增长。
使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的 write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供 write()调用写。
读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的 read()调用将默认地被阻塞,等待某些数据被写入,这解决了 read()调用返回文件结束的问题。
四:linux 锁
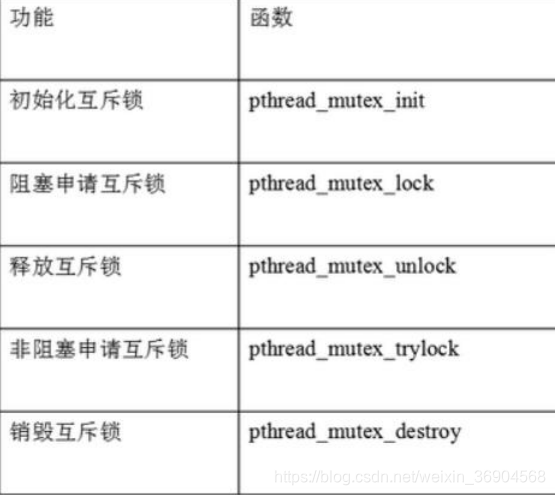
互斥锁:互斥锁只能有对一个线程使用,就是用来互斥的。
自旋锁:自旋锁上锁后让等待线程进行忙等待而不是睡眠阻塞,而信号量是让等待线程睡眠阻塞。忙等待浪费了处理器的时间,但时间通常很短,在 1 毫秒以下。
五:linux 进程调度
1. 进程类型
- I/O 消耗型进程:指进程大部分时间用来提交 I/O 请求或者是等待 I/O 请求
- 处理器消耗型进程:与 I/O 消耗型相反,此类进程把时间大多用在执行代码上
此时调度策略通常要在两个矛盾的目标中寻找平衡。Linux 为了保证交互式应用,所以对进程的响应做了优化,即更倾向于优先调度 I/O 消耗型进程.
2. 进程优先级
调度算法中最基本的一类就是基于优先级的调度.调度程序总是选择时间片未用尽而且优先级最高的进程运行
Linux 实现了一种基于动态优先级的调度方法.即:一开始,先设置基本的优先级,然后它允许调度程序根据需要加,减优先级。如果一个进程在 I/O 等待上消耗的时间多于运行时间,则明显属于 I/O 消耗型进程,那么根据 1 中的考虑,应该动态提高其优先级.
linux 提供了两组独立的优先级范围:
- nice 值:范围从-20 到+19.默认值是 0,值越小,优先级越高.nice 值也用来决定分配给进程的时间片的长短
- 实时优先级:范围为 0 到 9.注意,任何实时进程的优先级都高于普通的进程.
3. 进程时间片
时间片是一个数值,它表明进程在被抢占前所能持续运行的时间。调度策略必须规定一个默认的时间片。时间片过长,则会影响系统的交互性。时间片过短,则会明显增大因进程频繁切换所耗费的时间。
调度程序提供较长的默认时间片给交互式程序.此外,linux 调度程序还能根据进程的优先级动态调整分配给它的时间片,从而保证了优先级高的进程,执行的频率高,执行时间长.
当一个进程的时间片耗尽时,则认为进程到期了,此时不能在运行.除非所有进程都耗尽了他们的时间片,此时系统会给所有进程重新分配。
六:进程的创建
用fork()来创建子进程。
父进程用wait() 来等待来获取子进程的状态信息,获取到以后清除掉子进程。
如果子进程状态已经改变,那么 wait 调用会立即返回。否则调用 wait 的进程将会阻塞直到有子进程改变状态或者有信号来打断这个调用。(这里所指的状态的改变包括:子进程终止;子进程被一个信号终止来;子进程被一个信号恢复。)
七:线程
其实在 Linux 中,新建的线程并不是在原先的进程中,而是系统通过一个系统调用clone() 。
该系统 copy 了一个和原先进程完全一样的进程,并在这个进程中执行线程函数。不过这个 copy 过程和 fork 不一样。copy 后的进程和原先的进程共享了所有的变量,运行环境。这样,原先进程中的变量变动在 copy 后的进程中便能体现出来
八:零拷贝技术
1. 直接IO
应用程序之间访问磁盘,而不经过内核缓冲区,可以减少内核缓冲区到用户程序缓存的数据复制。
2. 使用mmap读取
使用mmap代替read读取,数据从DMA拷贝到内核缓冲区,应用程序和操作系统共享缓冲区,不需要再互相拷贝
3. 优化和写时复制技术
对数据在页缓冲区和用户进程缓冲区之间的传输和拷贝进行优化。

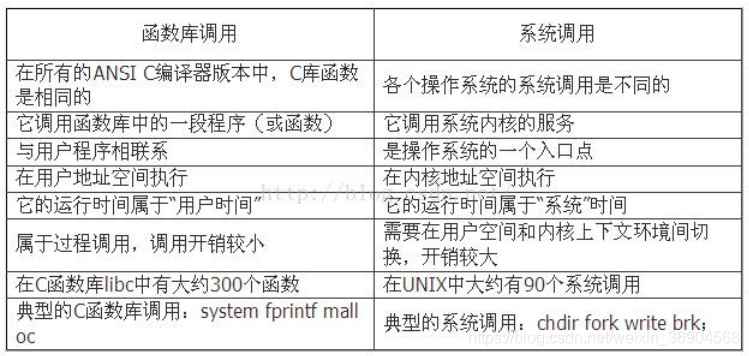
九:系统调用与库函数的区别

















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









