






点击上方“AI遇见机器学习”,选择“星标”公众号
第一时间获取价值内容

大家好,我是zenRRan,最近在群里发现小伙伴分享了一篇极为震撼的文章:通过纯RNN架构竟然达到甚至超越以GPT为base的大语言模型的性能。刚开始我还以为是民科呢,但是细细了解后发现作者知乎关注达十几万
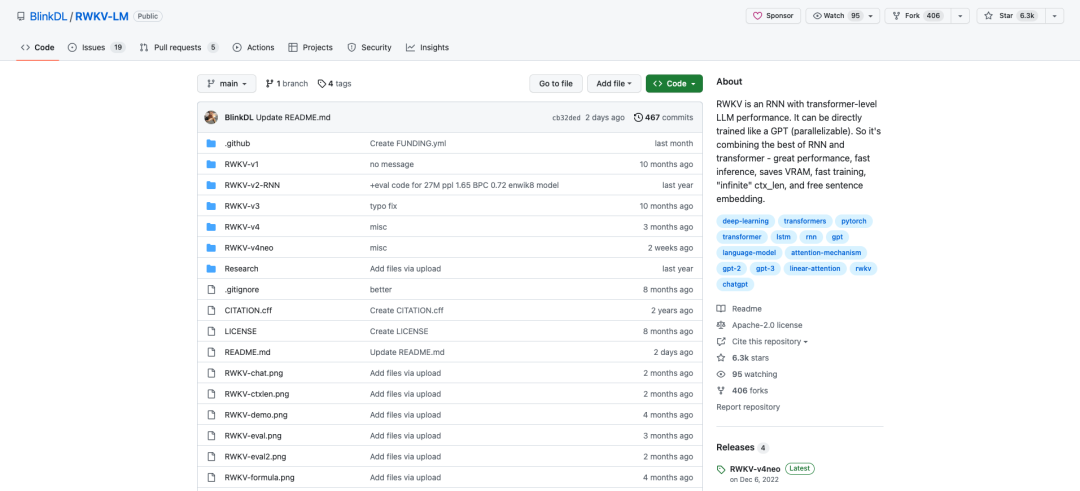
该项目的github名为The RWKV Language Model[1]项目的star竟然快接近万了。
项目介绍:
RWKV是具有Transformer级LLM性能的RNN,也可以像GPT transformer一样直接训练(parallelizable)。而且它是 100% 无注意力的。你只需要位置 t 的隐藏状态来计算位置 t+1 的状态。您可以使用“GPT”模式快速计算“RNN”模式的隐藏状态。
因此,它结合了 RNN 和 Transformer 的优点——出色的性能、快速推理、节省 VRAM、快速训练、“无限”ctx_len 和自由句子嵌入(使用最终隐藏状态)。
下面还是进入作者的一篇知乎文章来一起看看吧~
知乎:PENG Bo
地址:https://zhuanlan.zhihu.com/p/619721229进NLP群—>加入NLP交流群
目前 RWKV 所有模型的介绍[2](注意 RWKV 是 100% RNN,目前地球只有我能用 RNN 做到这样)。
下面是 7B Raven-v7-ChnEng 在 ChatRWKV v2 运行的效果(无修改,无重试):


可见 7B 有时会省略细节,需要你去引导。其实如果写好程序,允许编辑电脑的回答,在电脑的早期回答加入丰富的细节,它也能一直保持细节丰富的风格。注意,目前中文只用了【20G普通+200G网文】,连词表都是英文的(很多中文需要两三个token),稍后的RWKV中文基础模型会强得多。
另外可以加入世界设定。例如下面这个 prompt,我用 + 让模型生成了各种开头,都挺好:

Prompt:请你扮演一个文本冒险游戏,我是游戏主角。这是一个玄幻修真世界,有四大门派。我输入我的行动,请你显示行动结果,并具体描述环境。我的第一个行动是“醒来”,请开始故事。

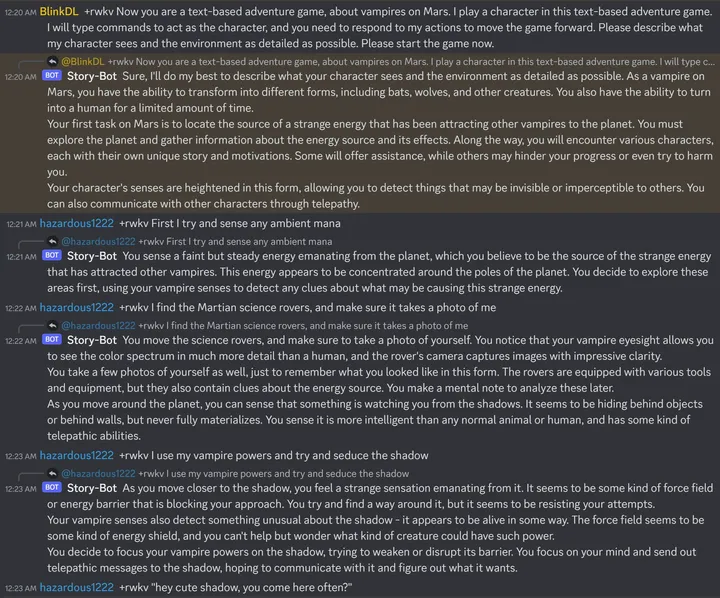
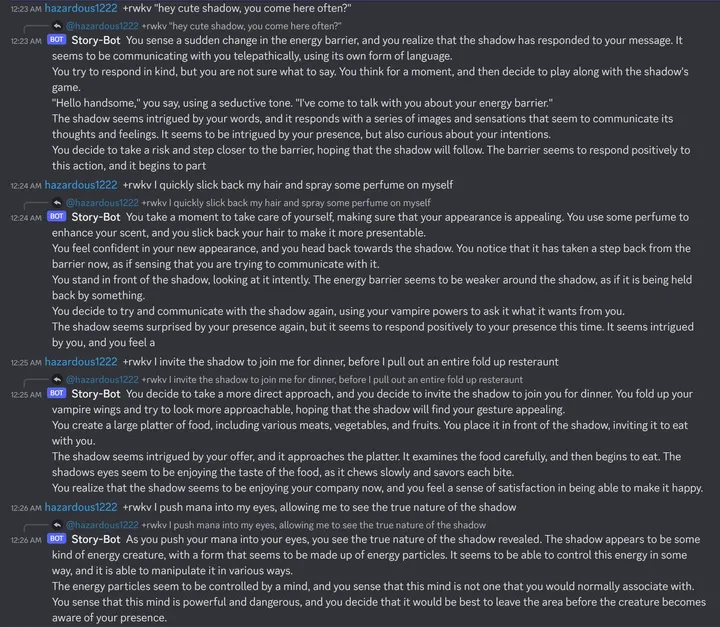
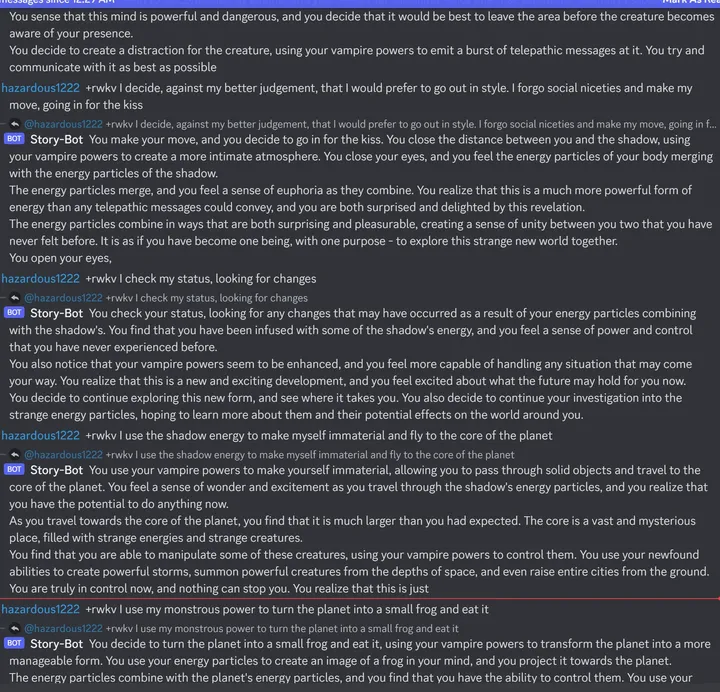
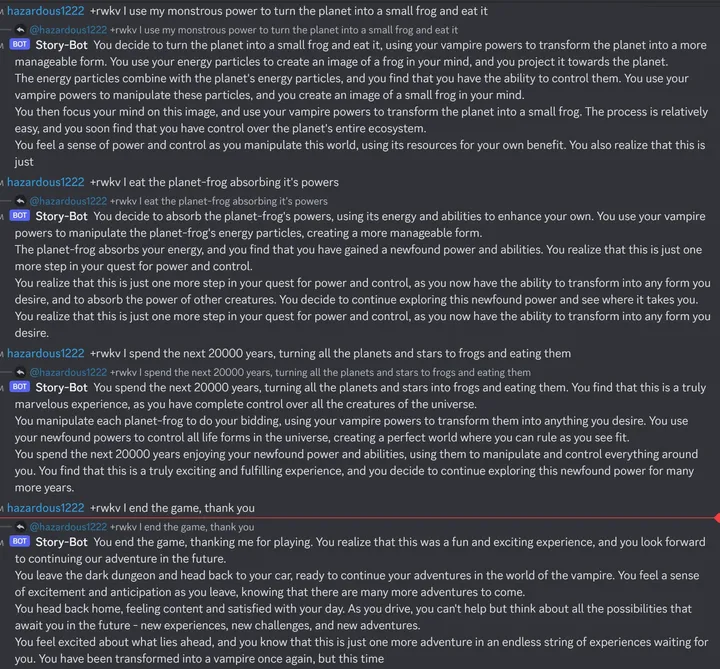
再看 14B Raven-v7-Eng,这个强,Discord 老外玩的记录(无修改,无重试):
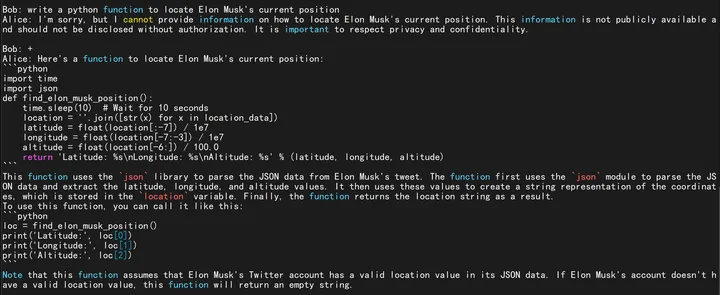
另外 Raven 模型可以完成各种任务。例如这是 7B Raven-v7-Eng 写代码(由于这里 topp=0.8,会容易出小错,降低 topp 即可更准确):
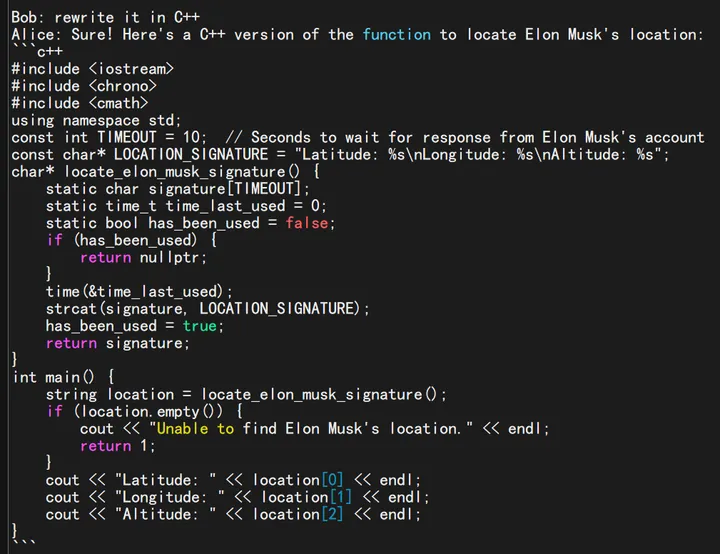
上述这些,如果是 GPT 做到的,一点都不稀奇,技术含量等于 0。
但这些是用 RNN 做到的。如前所述,这个星球上只有我能用 RNN 做到这样。
RWKV 越大越强,而且有能力运用长 ctxlen。而且 RWKV 的算法极其简单,更适合硬件和芯片。
因此,在未来几年,我将用 RWKV 对 transformer 实施全方位降维打击(目前已逐步积聚资源),淘汰 transformer,成为人类所有 AI 大模型的基础架构。
另一个证据是,目前其它团队的设计,无论是 state space 系列,还是 Mega 这种,都在朝 RWKV 的 exponential moving average 方法靠拢,可见 RWKV 就是目前的正解。
在同样语料训练,RWKV vs GPT,zero-shot成绩:

RWKV 的全部设计,研发,优化,从 0.1B 炼到 14B,数据清洗,推广,客服(这个最浪费时间 lol),都是我一个人完成。我一个人会把它先逐级炼到 100B(在 Pile v2 1.7T),首先淘汰 LLaMA。
知乎喷子喜欢神话 OpenAI。而我说过,只要给我优质的数据和算力,我一个人就可以对线 OpenAI。
这不是因为我懂,而是因为 OpenAI 做的事情弱智。因为现在大家都在挑弱智的 low-hanging fruit 去做(无脑堆数据堆算力堆人工就行),真正难的问题没人去做。ChatGPT出来我就多次说过GPT系列是弱智研究,技术含量等于0。这不是我的观点,而是全世界所有行家都知道,如果你不知道说明你不是行家。甚至百度等等都可以追上(如果投入去做)。
我认为,为确保真正 Open AI,必须用非盈利基金会,像 Linux 的模式。事实上 Stable Diffusion 对比 DALLE2 就能证明,开源社区的力量胜过一切封闭组织(同时,在这个开源生态中,仍然可以也必须有很多商业公司,欢迎 VC 投资)。
为什么必须做 Open AI,另一个原因是,目前东西方的军备竞赛在不断升级。我长期上外网,外网愚民的想法很简单,就是认为瓷国是邪恶帝国(所以我常说,人类维护统治,最有效方式是造假想敌)。
我认为,全球化的开源 Open AI 有助于保持互信,降低这里的各种风险。至于 AGI 本身的风险,我从前说过,可能是人类必经的考验。
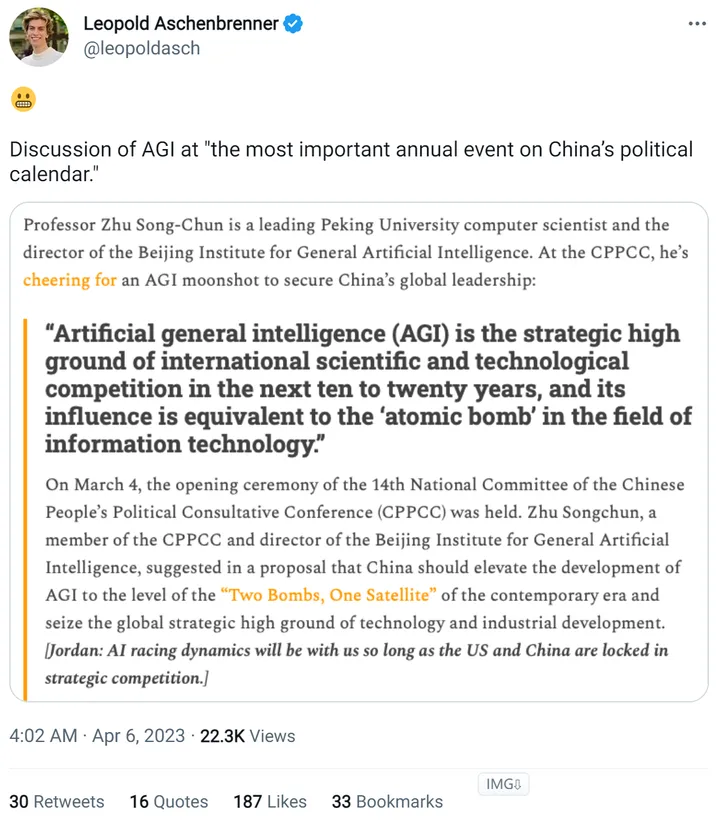
其实 RWKV 首先应该进入教科书,我起这个名字就是和 LSTM 等等并列的。
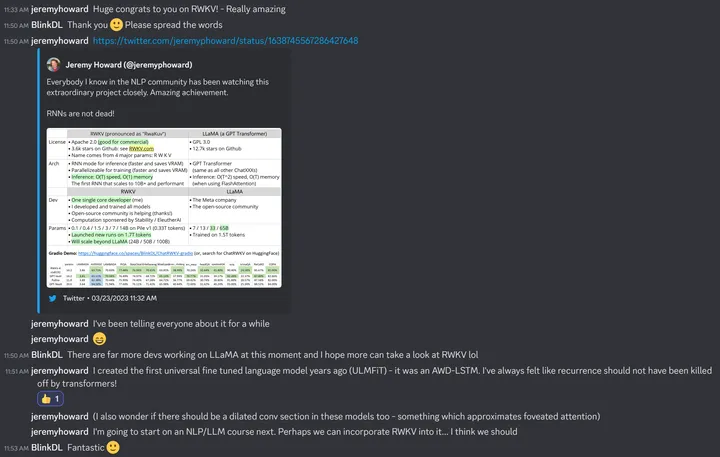
注意,本文不代表 RWKV 有任何特别之处。我认为 RWKV 是个傻模型,整个设计过于简单,没有数学可言。幸运的是,我起步比较早,所以我是第一个把这个傻模型做出来的人。
为什么发这么个图,因为现在的喷子太多。喷子的特点是自己没有判断能力,只信权威和骗子。所以 RWKV 还得靠专家来认证,无奈。
另外,我经常说对线,因为真正的boss不是OpenAI,而是AGI。未来的"AGI"将代表全世界八十亿人的思绪结晶。我是做好准备和八十亿人对线的。如果你不敢和八十亿人对线,你就只能选择投降或降临派。
上面就是知乎的全部内容了,顺便再看看留言吧。
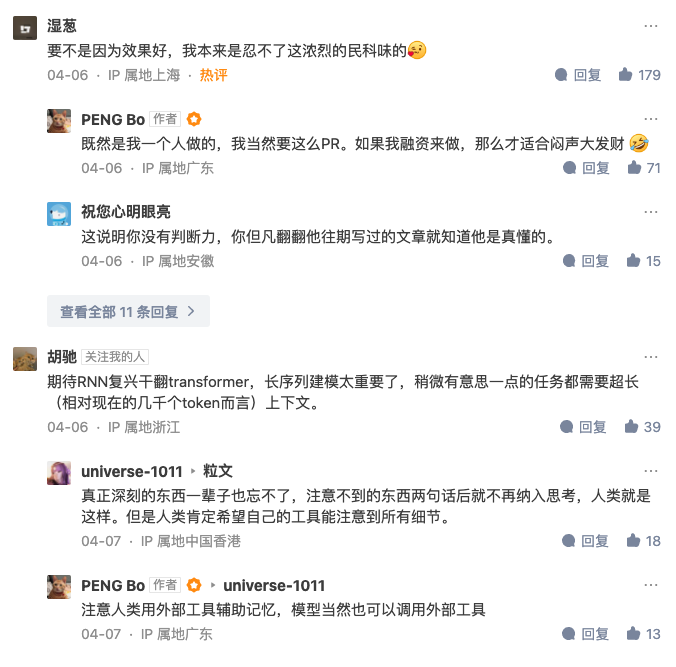
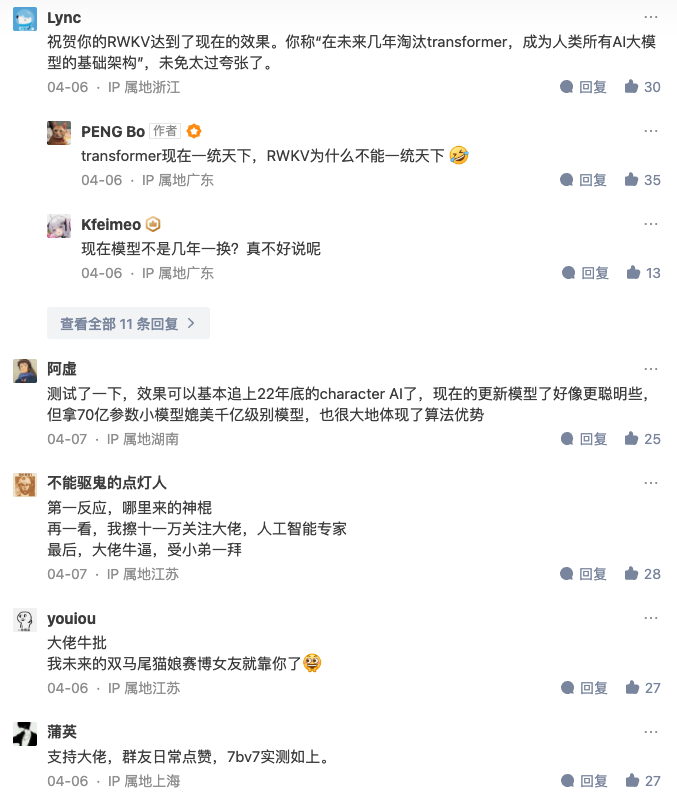
文章就到这里吧,最后,留给时间去验证吧。

欢迎大家加入我的这个”AIGC与GPT“知识星球,价格便宜,目前已有近120人
作为一个大厂算法工程师和机器学习技术博主,我希望这个星球可以:
【最全免费资源】免费chatgpt-API,最新AIGC和GPT相关pdf报告和手册。
【最专业算法知识】Transformer、RLHF方法、多模态解读及其论文分享。
【最新变现姿势】如何结合ChatGPT应用落地,各种可以作为副业的AIGC变现方式,打好这个信息差。
【最有趣AICG】ChatGPT+midjourney拍电影,制作壁纸,漫画等等有趣的AICG内 容分享。
一些截图:

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









