



2024年底,生成式AI的热潮已经持续了两年。最近,当被问及“什么是潜在空间?它如何帮助生成图像?”这样基础的问题时,我发现自己竟一时语塞,无法给出满意的回答🤔
所以这篇文章从代码角度出发,而非深入数学推导,来理解其工作机制。
先贴上代码链接:
DL-Demos/dldemos/VAE at master · SingleZombie/DL-Demos · GitHub
VAE图解
下面是我通过代码画的一个图解,帮助自己理解:
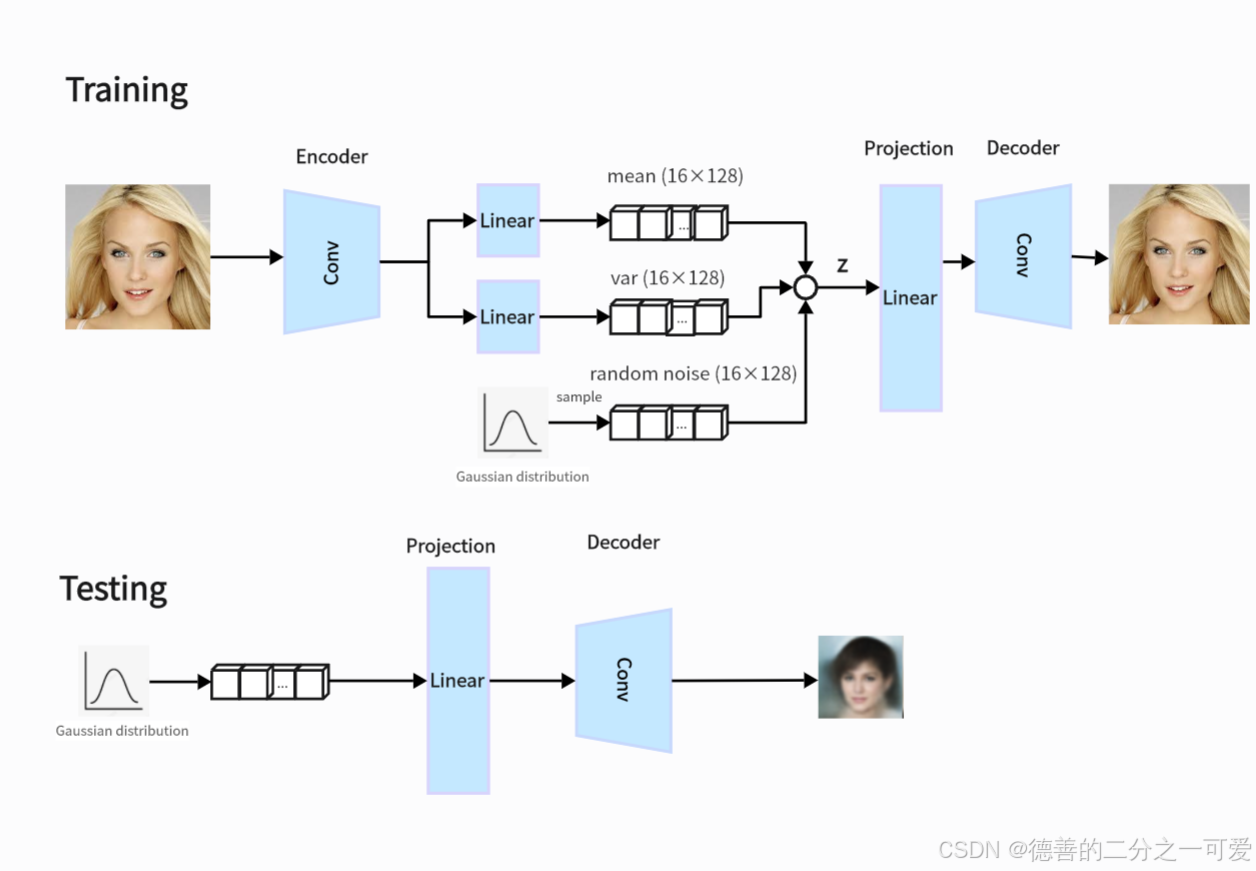
关键代码部分
训练阶段
1.图片经过encoder(卷积层)提取特征encoded
2.特征进入全连接层得到多维均值和方差mean和logvar
3.利用重参数技巧,根据 std 和 mean 以及从标准正态分布中抽取的 std,计算潜在变量 z
z = eps * std + meanz=eps*std+mean,eps为从高斯分布中随机采样的变量
4.z经过全连接映射变换维度,最后由decoder(卷积层)重建图像
def forward(self, x):
encoded = self.encoder(x)
encoded = torch.flatten(encoded, 1)
mean = self.mean_linear(encoded)
logvar = self.var_linear(encoded)
eps = torch.randn_like(logvar)
std = torch.exp(logvar / 2)
z = eps * std + mean
x = self.decoder_projection(z)
x = torch.reshape(x, (-1, *self.decoder_input_chw))
decoded = self.decoder(x)
return decoded, mean, logvar损失函数
损失函数为重建损失(mse)+KL散度(让学习的分布逼近正态分布)
def loss_fn(y, y_hat, mean, logvar):
recons_loss = F.mse_loss(y_hat, y)
kl_loss = torch.mean(
-0.5 * torch.sum(1 + logvar - mean**2 - torch.exp(logvar), 1), 0)
loss = recons_loss + kl_loss * kl_weight
return loss推理阶段
def sample(self, device='cuda'):
z = torch.randn(1, self.latent_dim).to(device)
x = self.decoder_projection(z)
x = torch.reshape(x, (-1, *self.decoder_input_chw))
decoded = self.decoder(x)
return decoded1.从高斯分布随机采样z
2.z经过decoder生成新图像
为什么VAE能生成新图像
关于VAE这种生成式模型为什么能生成新图像,这是因为VAE 不只是简单地压缩和重建图像,它还学会了不同类型图像的特征是如何组合的。训练过程中,编码器把每张图像转换成潜在空间中的一个点,这个点包含了图像的关键特征。潜在空间就像是一个有组织的地图,每个点都对应着合理的图像特征。
编码器输出的是每个潜在变量的均值和方差,而不是固定的数值,这样就定义了一个高斯分布(类似于钟形曲线)。这意味着即使我们在潜在空间中随机选择一个点,也能生成一张合理的图像。此外,潜在空间是平滑且连续的,所以相邻点之间的变化是渐进的,就像自然过渡的图像特征一样。


















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









