




 本文介绍如何使用BeautifulSoup和Requests库从西刺网站爬取免费的HTTPS IP代理,包括代码实现和IP有效性验证过程。
本文介绍如何使用BeautifulSoup和Requests库从西刺网站爬取免费的HTTPS IP代理,包括代码实现和IP有效性验证过程。
西刺是一个免费提供IP代理的网站,因为所提供的IP数量庞大且免费,可以为有需要的人提供很大的帮助,所以受到了想要获取免费IP人的热捧,这里是它的网站地址 点这里。 话不多说,现在开干
- 首先观察网页,进入网站,进入开发者模式,选取要爬取的字段,这里确定自己要爬取的是IP的地址、端口、类型
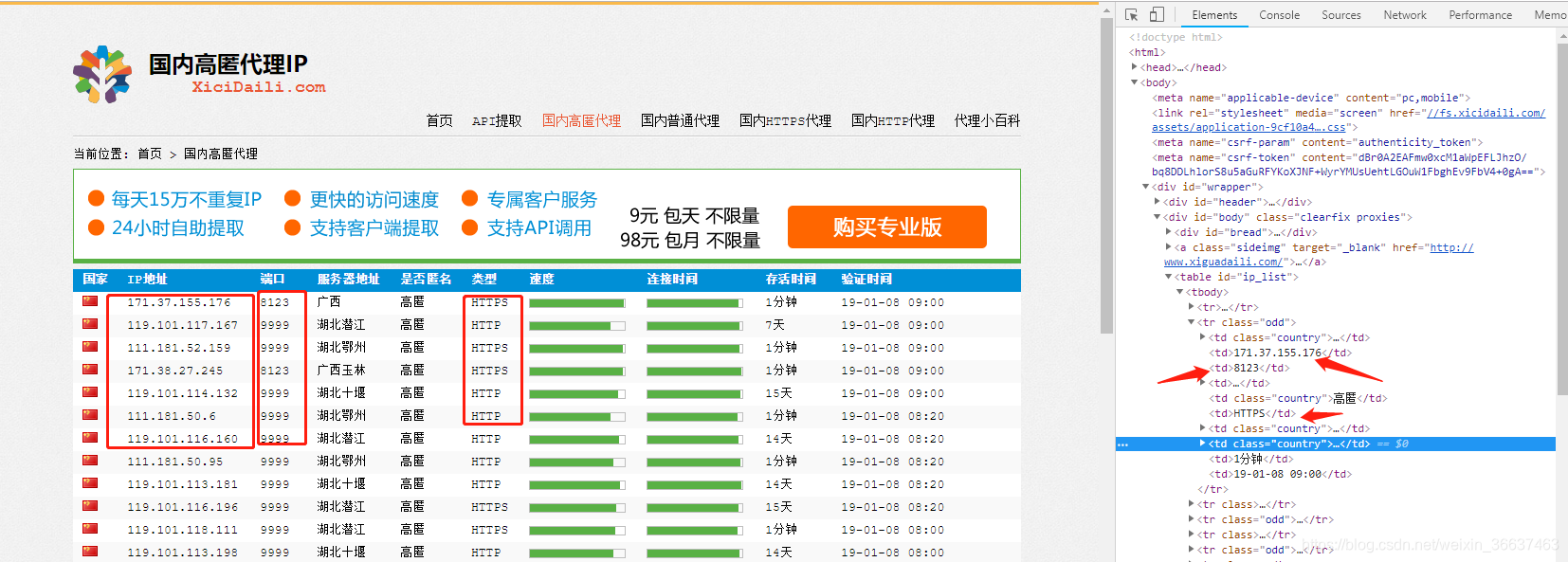
可以看到,我们要爬取的字段在一个tr标签下面的td标签中,直接右键点击,复制css selector地址。由于自己抓取的ip是为了抓取别的网站,需要用HTTPS类型的IP,所以将类型一起抓下来,后面区分。
2 这里使用BeautifulSoup+Requests抓取,其实使用正则表达式可以直接抓取一整页的数据,这里给出正则表达式
`re_dizhi = re.compile( r'\b(?:(?:25[0-5]|2[0-4]\d|[01]?\d{1,2})\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b', re.S)
dizhi = re.findall(re_dizhi, response)
re_duankou = re.compile('<td>(\d{2,5})</td>', re.S)
duankou = re.findall(re_duankou, response)
以下是自己代码:
import requests
import telnetlib # 实现ip的检测
from bs4 import BeautifulSoup
def get_html(page_number):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.\
0.3578.98 Safari/537.36"
}
base_url = "https://www.xicidaili.com/nn/"
for i in range(1, page_number+1):
url = base_url + str(i) # 结合URL
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response, 'lxml')
types = [i.get_text() for i in soup.select("tr > td:nth-of-type(6)")]
ip_address = [i.get_text() for i in soup.select('tr > td:nth-of-type(2)')]
ip_ports = [i.get_text() for i in soup.select("tr > td:nth-of-type(3)")]
for type, ip_addres, ip_port in zip(types, ip_address, ip_ports): # 使用zip函数实现抓取字段一一对应
data = {
'type': type,
'ip_address': ip_addres,
'ip_port': ip_port
}
if data['type'] == "HTTPS": # 设置一个简单的过滤
# 才发现西刺可以直接选HTTPS的选项,是我大意了,一定得要好好观察页面才行
verify_ip(data['ip_address'], data['ip_port'])
else:
pass
def verify_ip(ip_agent, ip_port):
try:
telnetlib.Telnet(ip_agent, ip_port, timeout=1) # 利用Telnet函数实现ip检测
except:
pass
else:
ip = "HTTPS://" + ip_agent + ":" + ip_port
with open('ip.txt', 'a') as f: # 会在项目文件目录下生成一个ip.txt文件
print("正在存储IP:" + ip) # 保存数据
f.write(ip+'\n')
if __name__ == '__main__':
page_number = int(input("输入你想要抓取的ip页数:", ))
get_html(page_number)
具体的代码需要自己消化,其实有时候用Xpath来做更为简单,但是需要用导入Scrapy.selector的Selector方法,因为BeautifulSoup只支持css select。
如果不需要HTTPS过滤的,可以自行删除过滤或者直接使用正则表达式更为简单暴力,但是作为初学者还是使用最基本的BeautifulSoup+requests库来实现,可以巩固一下知识。
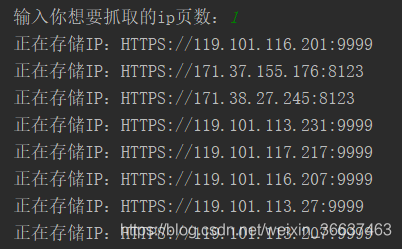
以下是运行中:
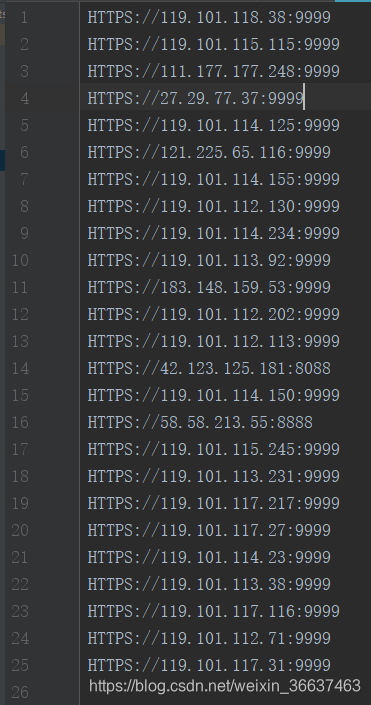
以下是抓取到的IP:
纸上得来终觉浅,绝知此事要躬行


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











