



 本文详细介绍了MAHAKIL过采样方法,该方法通过模拟染色体遗传机制来解决传统K近邻过采样方法中存在的样本边界扩大的问题。文章通过实例解释了MAHAKIL方法的工作原理,并提供了核心代码。
本文详细介绍了MAHAKIL过采样方法,该方法通过模拟染色体遗传机制来解决传统K近邻过采样方法中存在的样本边界扩大的问题。文章通过实例解释了MAHAKIL方法的工作原理,并提供了核心代码。
最近在帮实验室一师兄做实验时,刚好在学习类不平衡的采样方法,采样方法大致分为过采样和欠采样两大类,但是目前研究的主要为过采样方法,因为它主要是往少数类集合中增加样本点实现与多数类集合的动态平衡,这样能最大程度的保证样本的准确性,所以我将会在接下来的几篇博客里详细阐述过采样方法。过采样方法一般分为ROS(随机过采样),SMOTE-Regular, SMOTE-Borderline1, SMOTE-Borderline2, SMOTE-SVM以及我这篇博客要讲的MAHAKIL方法
说到MAHAKIL方法,这个方法是我看到一篇2017年的破产预测论文里讲的(具体链接我会在最下面给出,方便大家阅读),所以现在网上基本上是没有关于这个过采样方法的讲解,既然这样,那我就抛砖引玉一下吧,因为这几天看论文写代码也被它折磨的不要不要的。我接下来就截取里面的一些片段和大家讲解

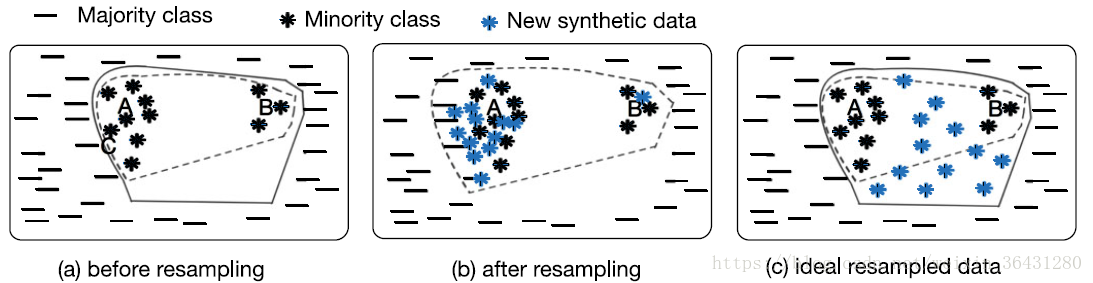
英文不好的同学请见谅哈,没办法谁让牛逼的论文都是老外写的呢,多看几篇就懂了。这里面大致讲的是:前两年很火热的SMOTE相关过采样方法都是采用K近邻方法选取样本点的最近点与之结合产生新样本,但是使用K近邻方法产生新样本好是好,但也有一个致命的缺点,就是产生的新样本会扩宽少数类样本集合的边界,也就是产生的新样本可能会跑到多数类样本集合里面去,这样就有些蛋疼了嘛,违反了我们的初衷,下图可以形象的表示
总是说乱世出英雄嘛,这是我们的大英雄MAHAKIL先生粉墨登场了,你不是说使用K近邻方法有毒嘛,那好,我就不用这个方法了。我精通生物遗传学原理,某一天刚好看到了染色体遗传机制,突然灵机一动,染色体遗传机制可以完美解决K-近邻所遇到的难题,于是迁移学习把这套机制给挪了过来,具体可以见下面两张图

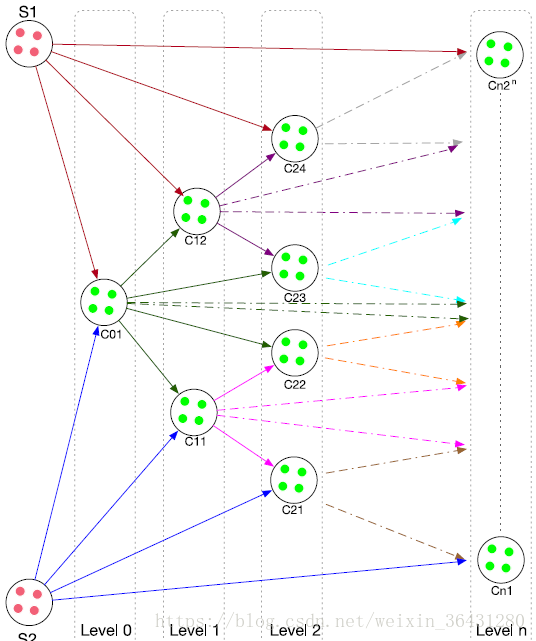
其实作者吧唧吧唧说了这么多,我总结就一句:祖先和子孙一直乱搞关系(哈哈哈哈)。这句话很粗俗哈,但话糙理不糙,就是祖先不断和其子孙结合产生新子孙,也就是亲上加亲,所以产生的样本点能完美的继承双亲的特性,也能具有自己的特点,所以最后会使整个少数类样本集合多样性增加,并且不会扩宽其边界。完美啊,简直perfect,果真是应了那句话:歪果仁就是喜欢乱搞啊,希望这段话不会被外国友人看到哈,不然会被打死。接下来就是重头戏了,我会就给出的伪代码来讲解相应的操作

看着有14条步骤很吓人,但其实都是纸老虎,虽然我刚开始也是被吓得不要不要的。大致步骤就是:现将给定数组X集合分为Nmax(多数类集合)和Nmin(少数类集合),然后用len(Nmax)-len(Nmin)得到要产生样本的数目,再计算Nmin数组中每个样本到中心点的马氏距离(马氏距离的相关概念大家可以百度,我就不介绍了),得到所有样本的马氏距离后,将每个样本点与其马氏距离保存在Nmindset数组里并按照马氏距离从大到小排序,然后将Nmindset数组从中间点Nmid分为两个数组Nbin1和Nbin2,并将两个数组Nbin1和Nbin2里的样本从1到Nmid标记好(即看做双亲了)到此前期的准备工作就算是都做好了,接下来就是傻瓜式的PaPaPa工作了,让双亲不断与后面子孙结合average(x1, x2)产生新样本,知道产生的样本数量满足要求了才停止。是不是听我说完之后感觉so easy了呢,快夸我很棒哈哈哈哈,闲话少说直接贴代码了,下面是我给出的核心代码,具体代码见最下面连接
这个是主文件MAHAKIL,核心代码都在这里面
from scipy import sparse
from sklearn.utils import check_X_y, safe_indexing
from validation import check_target_type, check_ratio
import numpy as np
# 求给定矩阵中的样本点到中心点的马氏距离
def mashi_distance(x_array):
# 给定矩阵的样本中心点
x_mean = np.mean(x_array, axis=0)
# 给定矩阵的协方差矩阵
S = np.cov(x_array.T)
ma_distances = []
if np.linalg.det(S) != 0:
for x_item in x_array:
SI = np.linalg.inv(S)
delta = x_item - x_mean
# 给定矩阵中的相应样本点到中心点的马氏距离
distance = np.sqrt(np.dot(np.dot(delta, SI), delta.T))
# 这里是项目要求得到马氏距离的平方
ma_distances.append(distance ** 2)
else:
print("矩阵行列式为0")
return ma_distances
class MAHAKIL:
def __init__(self, ratio='auto', sampling_type="over-sampling"):
self.ratio = ratio
self.sampling_type = sampling_type
# 产出新样本前对所给数组x_old,y_old进行检测,看其长度,类型是否一致
def fit(self, x_old, y_old):
y_old = check_target_type(y_old)
x_check, y_check = check_X_y(x_old, y_old, accept_sparse=['csr', 'csc'])
# ratio_xy为少数类要产生新样本的数目
self.ratio_xy = check_ratio(self.ratio, y_check, self.sampling_type)
return self
def sample(self, x_old, y_old):
X_resampled = x_old.copy()
y_resampled = y_old.copy()
for class_sample, n_samples in self.ratio_xy.items():
if n_samples == 0:
continue
target_class_indices = np.flatnonzero(y_old == class_sample)
X_class = safe_indexing(x_old, target_class_indices)
X_new, y_new = self.make_samples(X_class, class_sample, n_samples)
if sparse.issparse(X_new):
X_resampled = sparse.vstack([X_resampled, X_new])
else:
X_resampled = np.vstack((X_resampled, X_new))
y_resampled = np.hstack((y_resampled, y_new))
return X_resampled, y_resampled
# MAHAKIL方法具体产生新样本的方式
def make_samples(self, X_class, class_sample, n_samples):
x_row = np.shape(X_class)[0]
# 得到X_class数组的相关马氏距离
mashi_distances = mashi_distance(X_class)
# 将X_class数组里的每个样本和其马氏距离保存在mashi_zip数组里
mashi_zip = zip(X_class, mashi_distances)
# 将mashi_zip数组按其保存的马氏距离从大到小排序
sample_arr = sorted(mashi_zip, key=lambda x: x[1], reverse=True)
Nmid = int(x_row / 2)
nb1 = []
nb2 = []
for i in range(Nmid):
nb1.append(sample_arr[i][0])
Nbin1 = list(zip(nb1, range(Nmid)))
for j in range(Nmid, x_row):
nb2.append(sample_arr[j - Nmid - 1][0])
Nbin2 = list(zip(nb2, range(Nmid)))
x_new_list = []
xre_list = []
nmid = 0
for i in range(Nmid):
x_reshape = (np.array(Nbin1[i][0]) + np.array(Nbin2[i][0])) * 0.5
xre_list.append(x_reshape)
nmid += 1
if (len(x_new_list) + len(xre_list)) >= n_samples:
break
x_new_list.extend(list(zip(xre_list, range(nmid))))
if len(x_new_list) >= n_samples:
y_new = np.array([class_sample] * len(x_new_list))
return xre_list, y_new
x_new_copyl = x_new_list.copy()
x_new_copyr = x_new_list.copy()
nmid = 0
# 将第一代祖先不断与后面的子孙样本点结合产生新样本,知道满足数量n_sampes
while len(x_new_list) < n_samples:
xleft_list = []
xright_list = []
for i in range(Nmid):
x_reshape = (np.array(Nbin1[i][0]) + np.array(x_new_copyl[i][0])) * 0.5
xleft_list.append(x_reshape)
nmid += 1
if (len(x_new_list) + len(xleft_list)) >= n_samples:
break
x_new_copyl = list(zip(xleft_list, range(nmid)))
x_new_list.extend(x_new_copyl)
if (len(x_new_list) + len(xleft_list)) < n_samples:
nmid = 0
for j in range(Nmid):
x_reshape = (np.array(Nbin2[j][0]) + np.array(x_new_copyr[j][0])) * 0.5
xright_list.append(x_reshape)
nmid += 1
if (len(x_new_list) + len(xright_list)) >= n_samples:
break
x_new_copyr = list(zip(xleft_list, range(nmid)))
x_new_list.extend(x_new_copyr)
y_new = np.array([class_sample] * len(x_new_list))
x_new = []
for item in range(len(x_new_list)):
x_new.append(x_new_list[item][0])
return np.array(x_new), y_new
# 类似于主函数,入口
def fit_sample(self, x_old, y_old):
return self.fit(x_old, y_old).sample(x_old, y_old)
if __name__=='__main__':
X = np.array([[0.11622591, -0.0317206], [0.77481731, 0.60935141],
[1.25192108, -0.22367336], [0.53366841, -0.30312976],
[1.52091956, -0.49283504], [-0.28162401, -2.10400981],
[0.83680821, 1.72827342], [0.3084254, 0.33299982],
[0.70472253, -0.73309052], [0.28893132, -0.38761769],
[1.15514042, 0.0129463], [0.88407872, 0.35454207],
[1.31301027, -0.92648734], [-1.11515198, -0.93689695],
[-0.18410027, -0.45194484], [0.9281014, 0.53085498],
[-0.14374509, 0.27370049], [-0.41635887, -0.38299653],
[0.08711622, 0.93259929], [1.70580611, -0.11219234]])
Y = np.array([0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0])
# 给出的测试方法
mahakil = MAHAKIL()
X_resampled, y_resampled = mahakil.fit_sample(X, Y)
print(X_resampled)
print(y_resampled)
接下面给出的是validation辅助文件
import warnings
from collections import Counter
from numbers import Integral
import numpy as np
from sklearn.neighbors.base import KNeighborsMixin
from sklearn.neighbors import NearestNeighbors
from sklearn.externals import six, joblib
from sklearn.utils.multiclass import type_of_target
SAMPLING_KIND = ('over-sampling', 'under-sampling', 'clean-sampling',
'ensemble')
TARGET_KIND = ('binary', 'multiclass', 'multilabel-indicator')
def check_neighbors_object(nn_name, nn_object, additional_neighbor=0):
if isinstance(nn_object, Integral):
return NearestNeighbors(n_neighbors=nn_object + additional_neighbor)
elif isinstance(nn_object, KNeighborsMixin):
return nn_object
def check_target_type(y, indicate_one_vs_all=False):
type_y = type_of_target(y)
if type_y not in TARGET_KIND:
# FIXME: perfectly we should raise an error but the sklearn API does
# not allow for it
warnings.warn("'y' should be of types {} only. Got {} instead.".format(
TARGET_KIND, type_of_target(y)))
if indicate_one_vs_all:
return (y.argmax(axis=1) if type_y == 'multilabel-indicator' else y,
type_y == 'multilabel-indicator')
else:
return y.argmax(axis=1) if type_y == 'multilabel-indicator' else y
def hash_X_y(X, y, n_samples=10, n_features=5):
row_idx = slice(None, None, max(1, X.shape[0] // n_samples))
col_idx = slice(None, None, max(1, X.shape[1] // n_features))
return joblib.hash(X[row_idx, col_idx]), joblib.hash(y[row_idx])
def _ratio_all(y, sampling_type):
"""Returns ratio by targeting all classes."""
target_stats = Counter(y)
if sampling_type == 'over-sampling':
n_sample_majority = max(target_stats.values())
ratio = {key: n_sample_majority - value
for (key, value) in target_stats.items()}
elif (sampling_type == 'under-sampling' or
sampling_type == 'clean-sampling'):
n_sample_minority = min(target_stats.values())
ratio = {key: n_sample_minority for key in target_stats.keys()}
else:
raise NotImplementedError
return ratio
def _ratio_majority(y, sampling_type):
"""Returns ratio by targeting the majority class only."""
if sampling_type == 'over-sampling':
raise ValueError("'ratio'='majority' cannot be used with"
" over-sampler.")
elif (sampling_type == 'under-sampling' or
sampling_type == 'clean-sampling'):
target_stats = Counter(y)
class_majority = max(target_stats, key=target_stats.get)
n_sample_minority = min(target_stats.values())
ratio = {key: n_sample_minority
for key in target_stats.keys()
if key == class_majority}
else:
raise NotImplementedError
return ratio
def _ratio_not_minority(y, sampling_type):
"""Returns ratio by targeting all classes but not the minority."""
target_stats = Counter(y)
if sampling_type == 'over-sampling':
n_sample_majority = max(target_stats.values())
class_minority = min(target_stats, key=target_stats.get)
ratio = {key: n_sample_majority - value
for (key, value) in target_stats.items()
if key != class_minority}
elif (sampling_type == 'under-sampling' or
sampling_type == 'clean-sampling'):
n_sample_minority = min(target_stats.values())
class_minority = min(target_stats, key=target_stats.get)
ratio = {key: n_sample_minority
for key in target_stats.keys()
if key != class_minority}
else:
raise NotImplementedError
return ratio
def _ratio_minority(y, sampling_type):
"""Returns ratio by targeting the minority class only."""
target_stats = Counter(y)
if sampling_type == 'over-sampling':
n_sample_majority = max(target_stats.values())
class_minority = min(target_stats, key=target_stats.get)
ratio = {key: n_sample_majority - value
for (key, value) in target_stats.items()
if key == class_minority}
elif (sampling_type == 'under-sampling' or
sampling_type == 'clean-sampling'):
raise ValueError("'ratio'='minority' cannot be used with"
" under-sampler and clean-sampler.")
else:
raise NotImplementedError
return ratio
def _ratio_auto(y, sampling_type):
"""Returns ratio auto for over-sampling and not-minority for
under-sampling."""
if sampling_type == 'over-sampling':
return _ratio_all(y, sampling_type)
elif (sampling_type == 'under-sampling' or
sampling_type == 'clean-sampling'):
return _ratio_not_minority(y, sampling_type)
def _ratio_dict(ratio, y, sampling_type):
"""Returns ratio by converting the dictionary depending of the sampling."""
target_stats = Counter(y)
# check that all keys in ratio are also in y
set_diff_ratio_target = set(ratio.keys()) - set(target_stats.keys())
if len(set_diff_ratio_target) > 0:
raise ValueError("The {} target class is/are not present in the"
" data.".format(set_diff_ratio_target))
# check that there is no negative number
if any(n_samples < 0 for n_samples in ratio.values()):
raise ValueError("The number of samples in a class cannot be negative."
"'ratio' contains some negative value: {}".format(
ratio))
ratio_ = {}
if sampling_type == 'over-sampling':
n_samples_majority = max(target_stats.values())
class_majority = max(target_stats, key=target_stats.get)
for class_sample, n_samples in ratio.items():
if n_samples < target_stats[class_sample]:
raise ValueError("With over-sampling methods, the number"
" of samples in a class should be greater"
" or equal to the original number of samples."
" Originally, there is {} samples and {}"
" samples are asked.".format(
target_stats[class_sample], n_samples))
if n_samples > n_samples_majority:
warnings.warn("After over-sampling, the number of samples ({})"
" in class {} will be larger than the number of"
" samples in the majority class (class #{} ->"
" {})".format(n_samples, class_sample,
class_majority,
n_samples_majority))
ratio_[class_sample] = n_samples - target_stats[class_sample]
elif sampling_type == 'under-sampling':
for class_sample, n_samples in ratio.items():
if n_samples > target_stats[class_sample]:
raise ValueError("With under-sampling methods, the number of"
" samples in a class should be less or equal"
" to the original number of samples."
" Originally, there is {} samples and {}"
" samples are asked.".format(
target_stats[class_sample], n_samples))
ratio_[class_sample] = n_samples
elif sampling_type == 'clean-sampling':
# clean-sampling can be more permissive since those samplers do not
# use samples
for class_sample, n_samples in ratio.items():
ratio_[class_sample] = n_samples
else:
raise NotImplementedError
return ratio_
def check_ratio(ratio, y, sampling_type, **kwargs):
if sampling_type not in SAMPLING_KIND:
raise ValueError("'sampling_type' should be one of {}. Got '{}'"
" instead.".format(SAMPLING_KIND, sampling_type))
if np.unique(y).size <= 1:
raise ValueError("The target 'y' needs to have more than 1 class."
" Got {} class instead".format(np.unique(y).size))
if sampling_type == 'ensemble':
return ratio
if isinstance(ratio, six.string_types):
if ratio not in RATIO_KIND.keys():
raise ValueError("When 'ratio' is a string, it needs to be one of"
" {}. Got '{}' instead.".format(RATIO_KIND,
ratio))
return RATIO_KIND[ratio](y, sampling_type)
elif isinstance(ratio, dict):
return _ratio_dict(ratio, y, sampling_type)
elif callable(ratio):
ratio_ = ratio(y, **kwargs)
return _ratio_dict(ratio_, y, sampling_type)
RATIO_KIND = {'minority': _ratio_minority,
'majority': _ratio_majority,
'not minority': _ratio_not_minority,
'all': _ratio_all,
'auto': _ratio_auto}
好了,大功告成了,大家一定要自己动手试试才有效果呦,否则没有印象
链接:https://pan.baidu.com/s/1wdJ4TjVJXj7HeTBocW9C2w 密码:c4ti(这个链接是那篇关于MAHAKIL方法论文的链接)
这个就是我的微信号了,欢迎大家一起交流,讲的有问题的地方也请大家指出




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











