




 本文深入探讨了Pandas库中的核心数据结构:Series、DataFrame和Panel。详细介绍了这些数据结构的创建、查询、修改、增加和删除操作,以及索引和切片的使用方法。通过实例演示了如何进行数据筛选、条件过滤和数据聚合,为数据处理提供了全面的指南。
本文深入探讨了Pandas库中的核心数据结构:Series、DataFrame和Panel。详细介绍了这些数据结构的创建、查询、修改、增加和删除操作,以及索引和切片的使用方法。通过实例演示了如何进行数据筛选、条件过滤和数据聚合,为数据处理提供了全面的指南。
Pandas处理以下三个数据结构
系列(Series)
数据帧(DataFrame)
面板(Panel)
这些数据结构构建在Numpy数组之上
导入包:习惯给numpy起别名np,pandas起别名pd
一、Series数据类型
1 .创建Series数据类型
import pandas as pd
1.创建Series数据类型
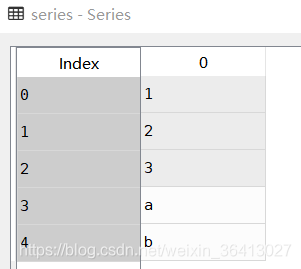
series = pd.Series([1, 2,3,'a','b'])
series
series = pd.Series(['王刚','男', 18, 59.5,False ], index=['name','sex', 'age', 'grade','qualified'])
series
name 王刚
sex 男
age 18
grade 59.5
qualified False
dtype: object
2. 查询
index和value查询
#值数据,输出类型为array,还是ndarray数组
series.values
#out:array(['王刚', '男', 18, 59.5, False], dtype=object)
#索引,输出index类型(Pandas独有的索引类型),本质上就是ndarray
series.index
#out: Index(['name', 'sex', 'age', 'grade', 'qualified'], dtype='object')
series.index[2]
#Out[13]: 'age'
series.index.values
#Out[14]: array(['name', 'sex', 'age', 'grade', 'qualified'], dtype=object)
3 索引查询
##位置索引,默认,自动生成,和自定义索引并存
series[1]
#Out[15]: '男'
##标签索引,自定义索引
series['sex']
#Out[16]: '男'
series.sex # 方法调用写法
#Out[17]: '男'
#查询多值
series[[1, 2, 4]]
#Out[18]:
#sex 男
#age 18
#qualified False
#dtype: object
series[['name', 'sex', 'age']] # 注意双括号
#Out[19]:
#name 王刚
#sex 男
#age 18
#dtype: object
#series[[1,'sex', 'age']] #错误,两套索引并存,但不能混用
4.切片
#位置切片,默认索引,左闭右开
series[:3]
#Out[22]:
#name 王刚
#sex 男
#age 18
#dtype: object
#标签切片,自定义索引
#注意:两边都闭区间(因为使用标签索引时通常不知道标签顺序,很难确定结束前一个标签是什么)
series[:'sex']
#Out[23]:
#name 王刚
#sex 男
#dtype: object
series['sex':]
#Out[24]:
#sex 男
#age 18
#grade 59.5
#qualified False
#dtype: object
#步长
series[::3]
#Out[27]:
#name 王刚
#grade 59.5
#dtype: object
series[::-1] #步长-1,逆序
#Out[26]:
#qualified False
#grade 59.5
#age 18
#sex 男
#name 王刚
#dtype: object
5.数组运算
wanggang = pd.Series({'mathematics': 66, 'English': 80, 'Chinese': 50})
#Out[29]:
#Chinese 50
#English 80
#mathematics 66
#dtype: int64
wanggang>= 60
#Out[34]:
#Chinese False
#English True
#mathematics True
#dtype: bool
wanggang[wanggang >= 60]
#Out[35]:
#English 80
#mathematics 66
#dtype: int64
#标量算数运算
wanggang + 1
#Out[36]:
#Chinese 51
#English 81
#mathematics 67
#dtype: int64
#应用函数
np.median(wanggang) # 中位数
#Out[37]: 66.0
wanggang.median() # 方法调用写法
#Out[38]: 66.0
6.in与get方法的应用
保留字in操作
使用.get()方法
'mathematics' in wanggang # 判断此键在不在class1的索引中
#0 in wanggang # 错误,in不会判断自动索引
wanggang.get('mathematics', 80) #从wanggang中提取索引mathematics的值,如存在就取出,不存在用80代替
7.修改
read查询选中赋值即可修改
#values值修改
wanggang['mathematics'] =90
#Out[40]:
#Chinese 50
#English 80
#mathematics 90
#dtype: int64
wanggang[['mathematics','Chinese']] = 60
#Out[42]:
#Chinese 60
#English 80
#mathematics 60
#dtype: int64
wanggang[['mathematics','Chinese']] = [60, 75]
#Out[42]:
#Chinese 60
#English 80
#mathematics 60
#dtype: int64
wanggang['mathematics','Chinese'] = [80, 90] # 一层也可以
#Out[44]:
#Chinese 90
#English 80
#mathematics 80
#dtype: int64
#索引修改
wangfang = wanggang.copy() # 复制副本而非引用视图,类似深拷贝
wangfang.index = ['mathematics', 'English', 'Chinese']
#Out[47]:
#mathematics 90
# French 80
#Chinese 80
#dtype: int64
二、创建DataFrame数据类型
dataframe= pd.DataFrame([
[1, 2,3,'a','b'],
['c', 'd','c', 4, 5]
])
dataframe
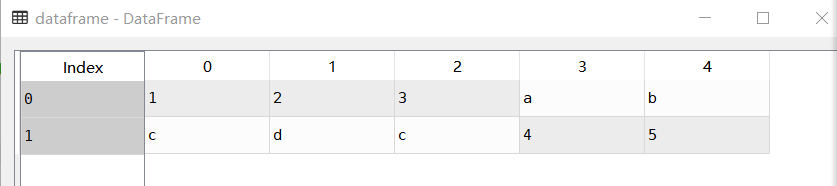
DataFrame对象包括行索引与列索引
行索引,横向索引,叫index,0轴,axis=0, 如图中(0,1)
列索引,纵向索引,叫columns,1轴,axis=1,如图中(0,1,2,3,4)
一、DataFrame数据类型
1. DataFrame对象创建
#二维列表,内层列表是行,行列默认索引0 1 2...
sdudent = pd.DataFrame([
['王华', 'male', 19, 178, 68, '深圳坂田', 58],
['周明', 'female', 20, 162, 59, '深圳南山', 80]
])
#自定义行列索引
sdudent_values = [
['王华', 'male', 19, 178, 68, '深圳坂田', 58],
['周明', 'female', 20, 162, 59, '深圳南山', 80]
]
sdudent= pd.DataFrame(
sdudent_values,
index=['0001', '0002'], # 定义行索引
columns=['name', 'sex', 'age', 'heigh', 'weight', 'address', 'grade'] # 定义列索引
)

#外层键是列索引,内层键是行索引,当inder不相同时,所有inder汇总的情况,没有值用NaN
sdudent_values = {
'name':pd.Series(['王明', '王华', '王红', '周靑', '刘兰'],index=['011','012', '013','014', '015']),
'sex':pd.Series([1, 0, 0, 1, 0],index=[1, 2, 3, 4, 5]),
'age':pd.Series([28, 38, 48, 8],index=[2, 3, 4, 5]) # 少一个值自动填充为NaN
}
sdudents= pd.DataFrame(sdudent_values)
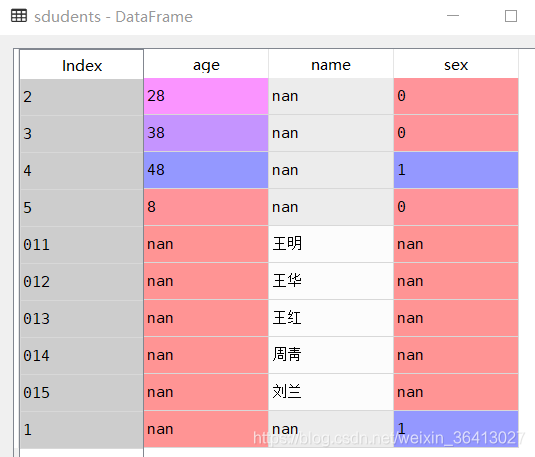
#指定内层字典键(行索引),没有的值会填充NaN
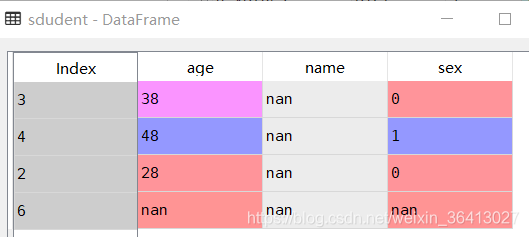
sdudent= pd.DataFrame(sdudent_values, index=[3, 4, 2, 6])
#自定义行列索引,生成一个5行6列的随机矩阵
random= pd.DataFrame(
np.random.randn(5, 4),
index=[1, 2, 3, 4, 5],
columns=['a', 'b', 'c', 'd']
)
2.DataFrame-查询
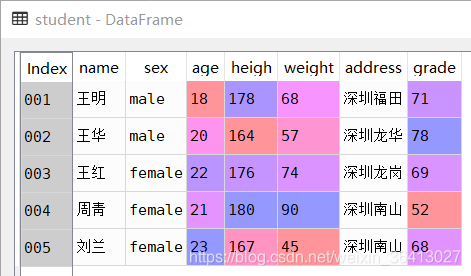
(1.创建student 表
student_values = [
['王明','male',18,178,68,'深圳福田',71],
['王华','male',20,164,57,'深圳龙华',78],
['王红','female',22,176,74,'深圳龙岗',69],
['周靑','female',21,180,90,'深圳南山',52],
['刘兰','female',23,167,45,'深圳南山',68],
]
student= pd.DataFrame(
student_values,
index=['001','002','003','004','005'],
columns=['name','sex','age','heigh','weight','address','grade']
)
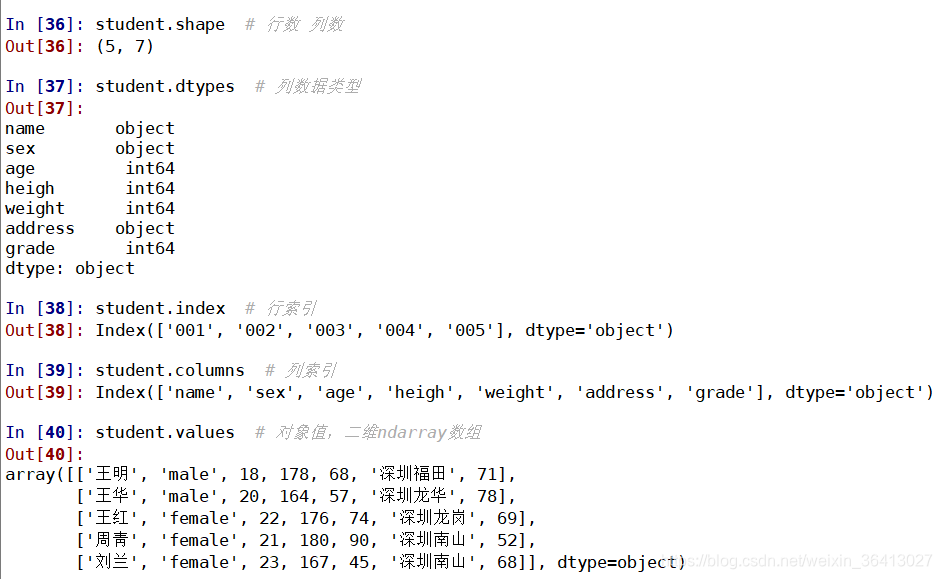
(2.DataFrame常用属性
student.shape # 行数 列数
student.dtypes # 列数据类型
student.index # 行索引
student.columns # 列索引
student.values # 对象值,二维ndarray数组
#DataFrame整体情况查询
#显示头部4行,默认5行
student.head(4)
#显示末尾2行,默认5行
student.tail(2)
#相关信息概览:行数,列数,列索引,列非空值个数,列类型,列类型,内存占用
student.info()
#<class 'pandas.core.frame.DataFrame'>
#Index: 5 entries, 001 to 005
#Data columns (total 7 columns):
#name 5 non-null object
#sex 5 non-null object
#age 5 non-null int64
#heigh 5 non-null int64
#weight 5 non-null int64
#address 5 non-null object
#grade 5 non-null int64
#dtypes: int64(4), object(3)
#memory usage: 320.0+ bytes
#快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
student.describe()
#Out[44]:
#age heigh weight grade
#count 5.000000 5.000000 5.000000 5.000000
#mean 20.800000 173.000000 66.800000 67.600000
#std 1.923538 7.071068 17.049927 9.555103
#min 18.000000 164.000000 45.000000 52.000000
#25% 20.000000 167.000000 57.000000 68.000000
#50% 21.000000 176.000000 68.000000 69.000000
#75% 22.000000 178.000000 74.000000 71.000000
#max 23.000000 180.000000 90.000000 78.000000
(3.类list/ndarray查询方式
#查询单列
student['name']
#查询多列,双中括号
student[['name','address']]
#查询行,包含头不包含尾
student[:2] #前两行
student[1:2] # 第1行
student[2:5:2] # 第2、4行,取从2行开始,步长为2
#查询单值,先列后行
student['name'][2]
(4. Pandas查询方式
三种查询方式:索引,切片,过滤
(1).索引
a.loc[行,列],标签索引,自定义索引
a.iloc[行,列],位置索引,默认索引
#输出学生学号为002学生的姓名,输出:王华
student.loc['002','name'] # 标签索引,先行后列,一行一列
student.at['002','name'] # 同上,但速度更快效率更高
student.iloc[1,0] # 位置索引
student.iat[1,0] # 同上,但速度更快效率更高
(2).切片
#切片选取连续多行
student.loc[:'003',:]
student.iloc[:3,:]
#切片选取连续多列
student.loc[:,'heigh':'address']
student.iloc[:,3:6]
#切片选取多行多列的聚合
student.loc['003':'005','sex':'heigh']
student.iloc[2:5,1:4]
(3).过滤
#布尔值做DataFrame参数,返回Dataframe对象
student[student['grade'] >= 60]
student[student.loc[:,'grade'] >= 60]
#布尔索引和切片结合,输出分数小于60分,同学的地址和姓名
student.loc[student['grade'] < 60,'address':]
> #address grade > #004 深圳南山 52
(一) & 且
(二) | 或
(三)非(或用 != 判断)
#返回布尔值
(student['grade'] >= 60) & (student['sex'] == 'female')
#返回Dataframe对象
student[(student['grade'] >= 60) & (student['sex'] == 'female')]
#查找weight和grade有小于60的数字设置为Nan,然后用dropna()去除缺失值
dColumns = student[['name','weight','grade']] # 获取3列数据
dBool = dColumns> 60 # 判断布尔值
dNan = dColumns[dBool] # 过滤查询
dNan
dNan.dropna(how='any') # 丢掉含有缺失值的行
(四)通过isin()过滤选取数据
#判断地址是否包含'深圳龙岗','深圳南山',返回布尔值,包含返回True
student['address'].isin(['深圳龙岗','深圳南山'])
#返回Dataframe对象
student[student['address'].isin(['深圳龙岗','深圳南山'])]
4.DataFrame修改
#查询方式修改
student['heigh'] = [150,160,170,180,190]
#索引或切片查询方式修改(修改‘001’,‘002’,003)
student.loc[['001','002','003'],['age','heigh']] = [[10,100],[20,200],[30,300]] # 3行2列
#通过where过滤修改
student_less=student.loc[:,['weight','grade']]
student_less[student_less > 60] = 1 # 修改非NaN值
5.DataFrame增加
#插入学号为006的学生
student.loc['006'] = ['刘芳','female',22,154,42,'深圳福田',95]
6.DataFrame增加
b= student.copy()
#默认删除行,默认只改动视图
b.drop('001') # 删除学号为001的单行
b.drop(['001','003']) # 删除学号为001与003的多行
#删除列
#axis=1删除列,默认axis=0删除行
b.drop('age',axis=1)# 删除age列
b.drop(['age','sex'],axis=1)#删除age与sex列
b#输出值未改变
#inplace=True 改动原数据,默认inplace=False 只改动视图
b.drop(['age','sex'],axis=1,inplace=True)
b #输出值改变
7.DataFrame对象的索引命名
student.index.name = ‘xuehao’
student.columns.name = ‘zhibiao’
student
8.遍历DataFrame
for index, values in student.iterrows():
print(index) # 行索引
print(values) # 值,按行排列
参考链接:https://www.yiibai.com/pandas/python_pandas_data_structures.html


















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









