



 本文介绍了如何在Spark on Zeppelin环境中配置Yarn模式,包括将`hive-site.xml`复制到Spark配置目录,修改`spark-env.sh`、`spark-defaults.conf`以确保Spark能找到必要的jar包,并在`zeppelin-env.sh`中进行相应配置。同时,需要替换Zeppelin目录下的某些jar包为Spark目录下的对应版本,以避免运行时错误。通过这些步骤,可以在Zeppelin上使用外部Spark并以Yarn模式运行代码。文章最后提出了一个问题,为何只能使用`yarn-client`模式,而不能使用`yarn-cluster`模式。
本文介绍了如何在Spark on Zeppelin环境中配置Yarn模式,包括将`hive-site.xml`复制到Spark配置目录,修改`spark-env.sh`、`spark-defaults.conf`以确保Spark能找到必要的jar包,并在`zeppelin-env.sh`中进行相应配置。同时,需要替换Zeppelin目录下的某些jar包为Spark目录下的对应版本,以避免运行时错误。通过这些步骤,可以在Zeppelin上使用外部Spark并以Yarn模式运行代码。文章最后提出了一个问题,为何只能使用`yarn-client`模式,而不能使用`yarn-cluster`模式。
一、上篇文件介绍到Spark on Zeppelin 但是运行的是Zeppelin自带的spark,不能使用yarn模式,会导致很多问题的,今天介绍一下Spark On Zeppelin使用yarn模式配置以及运行代码。
二、相关配置
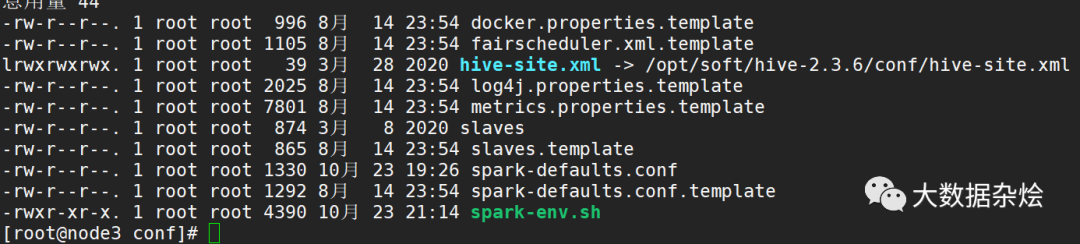
spark配置拷贝hive-site.xml到spark conf目录下
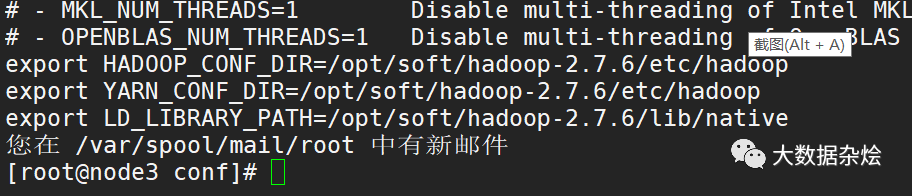
配置spark-env.sh
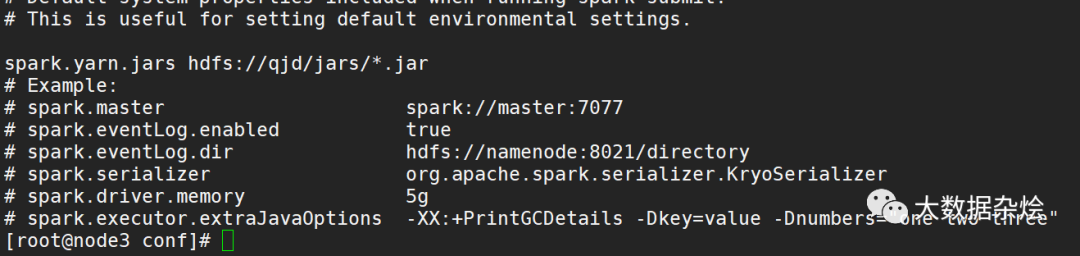
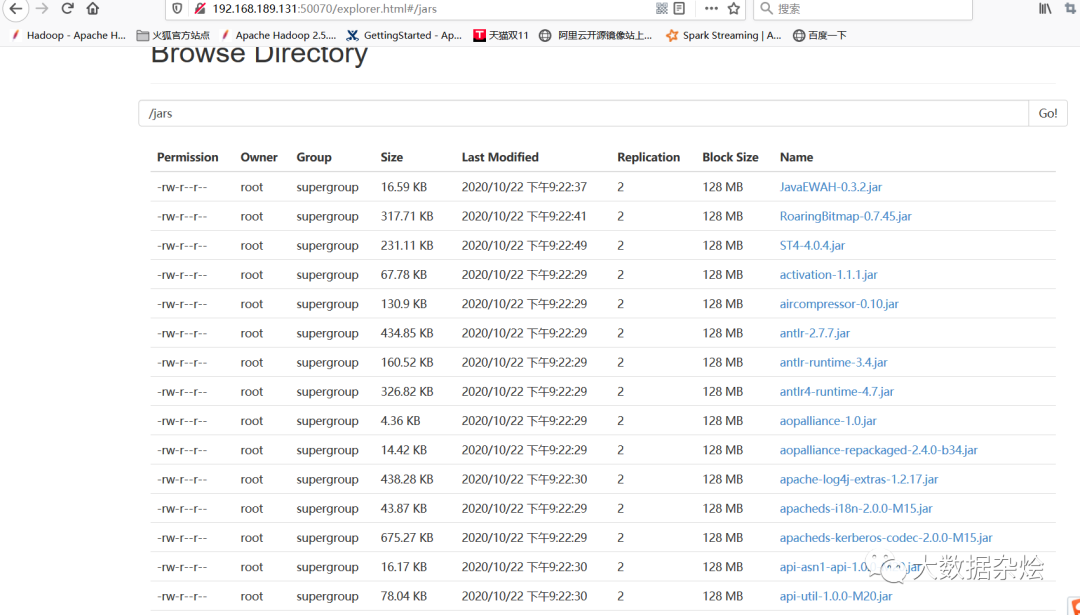
配置spark-defaults.conf 为了spark on yarn找到相应的spark jar包,并将spark目录下的jar包上传到自建的hdfs目录上供代码运行时进行读取所需jar包
配置zeppelin-env.sh

替换zeppelin安装目录下的jar包
jackson-annotations-2.9.9.jar
jackson-core-2.8.10.jar
jackson-databind-2.9.10.1.jar
更换成spark安装目录下的jar包
jackson-annotations-2.6.7.jar
jackson-core-2.6.7.jar
jackson-databind-2.6.7.jar
如果上述jar包不更换会出现以下的报错

通过页面编辑相关执行器
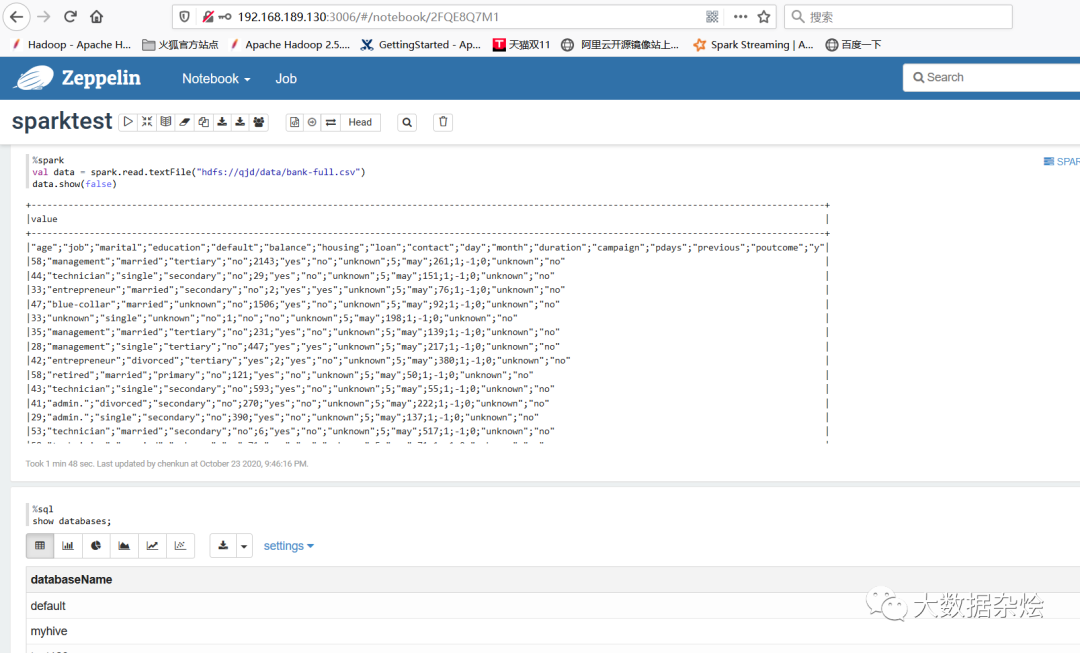
创建NoteBook进行编写读取hdfs上数据和读取hive库数据
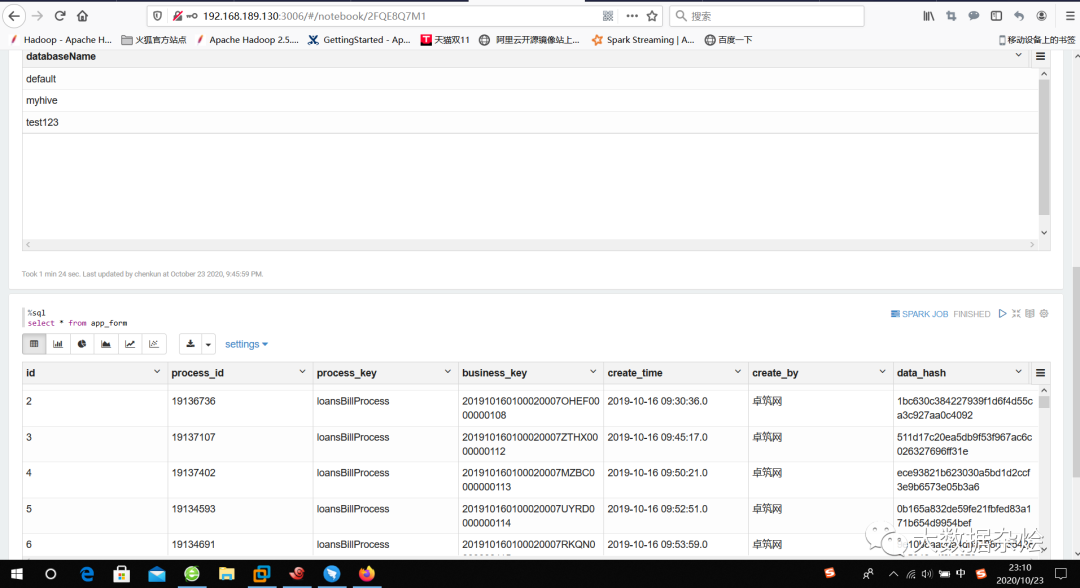
yarn界面查看Zeppelin所提交的运行
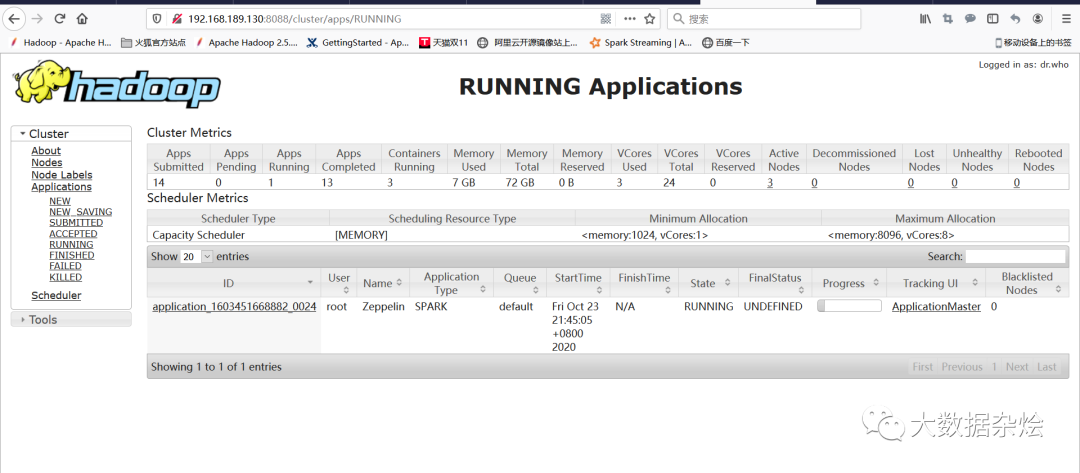
综上所述spark在zeppelin上不使用自带spark利用外部spark,采用on yarn模式运行代码已经完成了。
思考:为什么只能采用 yarn-client模式呢?而不能采用yarn-cluster模式呢?
时间仓促如有错误恳请大家原谅,并指出错误

















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









