




 Shuffle是Hadoop MapReduce中的关键步骤,它连接Map和Reduce任务,确保数据正确传递。Map阶段结束后,数据在内存中排序并溢写到磁盘,最终归并成大文件。Reduce端通过网络领取属于自己的数据并进行归并,优化带宽使用和磁盘IO。理解并优化Shuffle能显著提升MapReduce作业的性能和效率。
Shuffle是Hadoop MapReduce中的关键步骤,它连接Map和Reduce任务,确保数据正确传递。Map阶段结束后,数据在内存中排序并溢写到磁盘,最终归并成大文件。Reduce端通过网络领取属于自己的数据并进行归并,优化带宽使用和磁盘IO。理解并优化Shuffle能显著提升MapReduce作业的性能和效率。
shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的性能和吞吐量。
shuffle的目的是以下三点:
- 完整地从map task端读取数据到reduce 端。
- 在跨节点读取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
来自其他大佬的经典图解
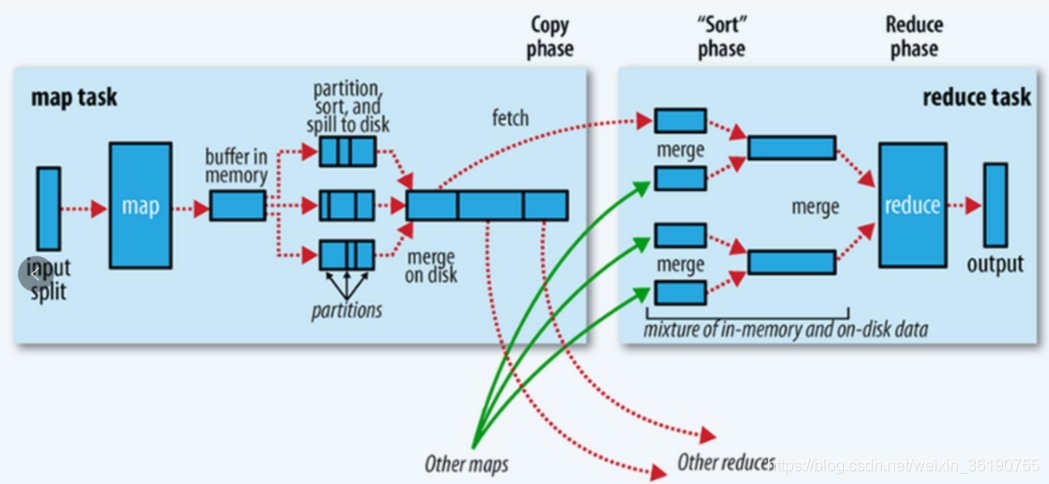
在进入map这一步之前,首先是split(分片),按输入文件大小和数量切分多个片,每一个片对应一个maptask。
Map端shuffle
Map的输出结果首先被缓存到内存,当缓存区(环状缓冲区)达到80% (默认大小为100MB),就会启动溢写操作,当前启动溢写操作时,首先把缓存中的数据进行分区,对每个分区的数据进行排序和合并。之后再写入到磁盘中,每次溢写 都会生成新的磁盘文件,随着Job执行,被溢写出到磁盘的文件会越来越多,在Map任务全部结束之前,这些溢写文件会被归并成一个大的磁盘文件,然后通知相应的Reduce任务来领取属于自己的数据
- map输入结果写入缓冲区
- 缓冲区达到阈值(触发溢写的百分比),溢写到磁盘中
- 分区内排序合并最后归并成大文件(k,v)
Reduce端shuffle
- 领取数据
- 归并数据
- 数据给reduce任务


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









