



前言
前文已经介绍了TextCNN的基本原理,如果还不熟悉的建议看看原理:【深度学习】textCNN论文与原理[1]及一个简单的基于pytorch的图像分类案例:【深度学习】卷积神经网络-图片分类案例(pytorch实现)[2]。 现在介绍一下如何使用textcnn进行文本分类,该部分内容参考了:Pytorch-textCNN(不调用torchtext与调用torchtext)[3]。当然原文写的也挺好的,不过感觉不够工程化。现在我们就来看看如何使用pytorch和cnn来进行文本分类吧。
1 实验语料介绍与预处理
本文进行的任务本质是一个情感二分类的任务,语料内容为英文,其格式如下:

一行文本即实际的一个样本,样本数据分别在neg.txt和pos.txt文件中。在进行数据预处理之前,先介绍一下本任务可能用到的一些参数,这些参数我放在了一个config.py的文件中,内容如下:
#!/usr/bin/python# -*- coding: UTF-8 -*-"""@author: juzipi@file: config.py@time:2020/12/06@description: 配置文件"""LARGE_SENTENCE_SIZE = 50 # 句子最大长度BATCH_SIZE = 128 # 语料批次大小LEARNING_RATE = 1e-3 # 学习率大小EMBEDDING_SIZE = 200 # 词向量维度KERNEL_LIST = [3, 4, 5] # 卷积核长度FILTER_NUM = 100 # 每种卷积核输出通道数DROPOUT = 0.5 # dropout概率EPOCH = 20 # 训练轮次下面就是数据预处理过程啦,先把代码堆上来:
import numpy as npfrom collections import Counterimport randomimport torchfrom sklearn.model_selection import train_test_splitimport configrandom.seed(1000)np.random.seed(1000)torch.manual_seed(1000)def read_data(filename): """ 数据读取 :param filename: 文件路径 :return: 数据读取内容(整个文档的字符串) """ with open(filename, "r", encoding="utf8") as reader: content = reader.read() return contentdef get_attrs(): """ 获取语料相关参数 :return: vob_size, pos_text, neg_text, total_text, index2word, word2index """ pos_text, neg_text = read_data("corpus/pos.txt"), read_data("corpus/neg.txt") total_text = pos_text + '' + neg_text text = total_text.split() vocab = [w for w, f in Counter(text).most_common() if f > 1] vocab = ['', ''] + vocab index2word = {i: word for i, word in enumerate(vocab)} word2index = {word: i for i, word in enumerate(vocab)} return len(word2index), pos_text, neg_text, total_text, index2word, word2indexdef convert_text2index(sentence, word2index, max_length=config.LARGE_SENTENCE_SIZE): """ 将语料转成数字化数据 :param sentence: 单条文本 :param word2index: 词语-索引的字典 :param max_length: text_cnn需要的文本最大长度 :return: 对语句进行截断和填充的数字化后的结果 """ unk_id = word2index[''] pad_id = word2index[''] # 对句子进行数字化转换,对于未在词典中出现过的词用unk的index填充 indexes = [word2index.get(word, unk_id) for word in sentence.split()] if len(indexes) 其中各个函数怎么使用以及相关参数已经在函数的说明中了,这里再赘述就耽误观众姥爷的时间了,哈哈。这些代码我放在了一个dataloader.py的python文件中了,相信你会合理的使用它,如果有啥不明白的可以留言交流哦。
2 textcnn模型构建
我依然先把代码堆出来,不是网传那么一句话嘛:“talk is cheap, show me code”,客官,代码来咯:
#!/usr/bin/python# -*- coding: UTF-8 -*-"""@author: juzipi@file: model.py@time:2020/12/06@description:"""import numpy as npimport torchfrom torch import nn, optimimport matplotlib.pyplot as pltimport configimport dataloaderimport utilsclass TextCNN(nn.Module): # output_size为输出类别(2个类别,0和1),三种kernel,size分别是3,4,5,每种kernel有100个 def __init__(self, vocab_size, embedding_dim, output_size, filter_num=100, kernel_list=(3, 4, 5), dropout=0.5): super(TextCNN, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) # 1表示channel_num,filter_num即输出数据通道数,卷积核大小为(kernel, embedding_dim) self.convs = nn.ModuleList([ nn.Sequential(nn.Conv2d(1, filter_num, (kernel, embedding_dim)), nn.LeakyReLU(), nn.MaxPool2d((config.LARGE_SENTENCE_SIZE - kernel + 1, 1))) for kernel in kernel_list ]) self.fc = nn.Linear(filter_num * len(kernel_list), output_size) self.dropout = nn.Dropout(dropout) def forward(self, x): x = self.embedding(x) # [128, 50, 200] (batch, seq_len, embedding_dim) x = x.unsqueeze(1) # [128, 1, 50, 200] 即(batch, channel_num, seq_len, embedding_dim) out = [conv(x) for conv in self.convs] out = torch.cat(out, dim=1) # [128, 300, 1, 1],各通道的数据拼接在一起 out = out.view(x.size(0), -1) # 展平 out = self.dropout(out) # 构建dropout层 logits = self.fc(out) # 结果输出[128, 2] return logits# 数据获取VOB_SIZE, pos_text, neg_text, total_text, index2word, word2index = dataloader.get_attrs()# 数据处理X_train, X_test, y_train, y_test = dataloader.number_sentence(pos_text, neg_text, word2index)# 模型构建cnn = TextCNN(VOB_SIZE, config.EMBEDDING_SIZE, 2)# print(cnn)# 优化器选择optimizer = optim.Adam(cnn.parameters(), lr=config.LEARNING_RATE)# 损失函数选择criterion = nn.CrossEntropyLoss()def train(model, opt, loss_function): """ 训练函数 :param model: 模型 :param opt: 优化器 :param loss_function: 使用的损失函数 :return: 该轮训练模型的损失值 """ avg_acc = [] model.train() # 模型处于训练模式 # 批次训练 for x_batch, y_batch in dataloader.get_batch(X_train, y_train): x_batch = torch.LongTensor(x_batch) # 需要是Long类型 y_batch = torch.tensor(y_batch).long() y_batch = y_batch.squeeze() # 数据压缩到1维 pred = model(x_batch) # 模型预测 # 获取批次预测结果最大值,max返回最大值和最大索引(已经默认索引为0的为负类,1为为正类) acc = utils.binary_acc(torch.max(pred, dim=1)[1], y_batch) avg_acc.append(acc) # 记录该批次正确率 # 使用损失函数计算损失值,预测值要放在前 loss = loss_function(pred, y_batch) # 清楚之前的梯度值 opt.zero_grad() # 反向传播 loss.backward() # 参数更新 opt.step() # 所有批次数据的正确率计算 avg_acc = np.array(avg_acc).mean() return avg_accdef evaluate(model): """ 模型评估 :param model: 使用的模型 :return: 返回当前训练的模型在测试集上的结果 """ avg_acc = [] model.eval() # 打开模型评估状态 with torch.no_grad(): for x_batch, y_batch in dataloader.get_batch(X_test, y_test): x_batch = torch.LongTensor(x_batch) y_batch = torch.tensor(y_batch).long().squeeze() pred = model(x_batch) acc = utils.binary_acc(torch.max(pred, dim=1)[1], y_batch) avg_acc.append(acc) avg_acc = np.array(avg_acc).mean() return avg_acc# 记录模型训练过程中模型在训练集和测试集上模型预测正确率表现cnn_train_acc, cnn_test_acc = [], []# 模型迭代训练for epoch in range(config.EPOCH): # 模型训练 train_acc = train(cnn, optimizer, criterion) print('epoch={},训练准确率={}'.format(epoch, train_acc)) # 模型测试 test_acc = evaluate(cnn) print("epoch={},测试准确率={}".format(epoch, test_acc)) cnn_train_acc.append(train_acc) cnn_test_acc.append(test_acc)# 模型训练过程结果展示plt.plot(cnn_train_acc)plt.plot(cnn_test_acc)plt.ylim(ymin=0.5, ymax=1.01)plt.title("The accuracy of textCNN model")plt.legend(["train", 'test'])plt.show()多说无益程序都在这,相关原理已经介绍了,各位读者慢慢品尝,有事call me。 对了,程序最后运行的结果如下:
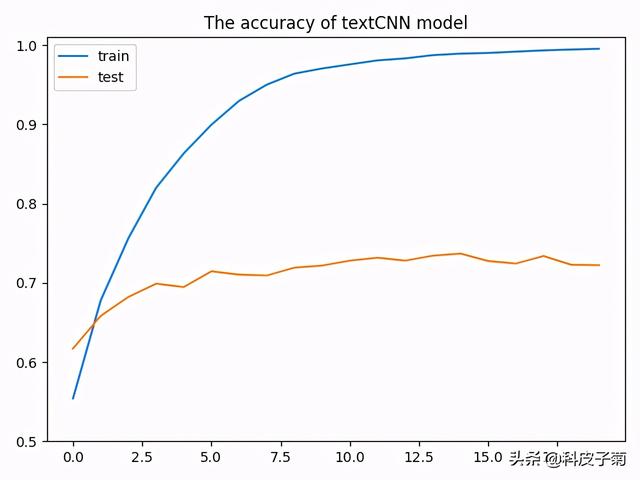
模型分类结果
3 结果的一个简要分析
其中随着模型的训练,模型倒是在训练集上效果倒好(毕竟模型在训练集上调整参数嘛),测试集上的结果也慢慢上升最后还略有下降,可见开始过拟合咯。本任务没有使用一些预训练的词向量以及语料介绍,总体也就1万多条,在测试集达到了这个效果也是差强人意了。主要想说明如何使用pytorch构建textcnn模型,实际中的任务可能更复杂,对语料的处理也更麻烦(数据决定模型的上限嘛)。或许看完这个文章后,你对损失函数、优化器、数据批次处理等还有一些未解之谜和改进的期待,我尽力在工作之余书写相关文章以飨读者,敬请关注哦。打条广告,想及时看到最新个人原创文章记得关注“AIAS编程有道”公众号哦,我在那里等你。至于本文的全部代码和语料,我都上传到github上了:https://github.com/Htring/NLP_Applications[4],后续其他相关应用代码也会陆续更新,也欢迎star,指点哦。
参考资料
[1]【深度学习】textCNN论文与原理: https://piqiandong.blog.youkuaiyun.com/article/details/110099713
[2]【深度学习】卷积神经网络-图片分类案例(pytorch实现): https://piqiandong.blog.youkuaiyun.com/article/details/109967487
[3] Pytorch-textCNN(不调用torchtext与调用torchtext): https://www.cnblogs.com/cxq1126/p/13466998.html
[4] https://github.com/Htring/NLP_Applications: https://github.com/Htring/NLP_Applications


















 4799
4799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









