



 本文深入探讨Java I/O流的概念,包括字节流与字符流的特性、构造方法及使用案例,如文件复制、文本处理与高效流操作,旨在帮助读者掌握Java文件操作的核心技巧。
本文深入探讨Java I/O流的概念,包括字节流与字符流的特性、构造方法及使用案例,如文件复制、文本处理与高效流操作,旨在帮助读者掌握Java文件操作的核心技巧。
文章目录
JAVA文件I/O流概述:
-
I/O流概述:
a. I/O流用来处理设备之间的数据传输
b. Java对数据的操作是通过流的方式
c. Java用于操作流的对象都在IO包中 java.io -
IO流分类:
- a. 按照数据流向 站在内存角度:
类别 功能 输入流 读入数据 输出流 写出数据 - b. 按照数据类型:
类别 功能 字节流 可以读写任何类型的文件 字符流 只能读写文本文件 -
JAVA字节流的继承体系:
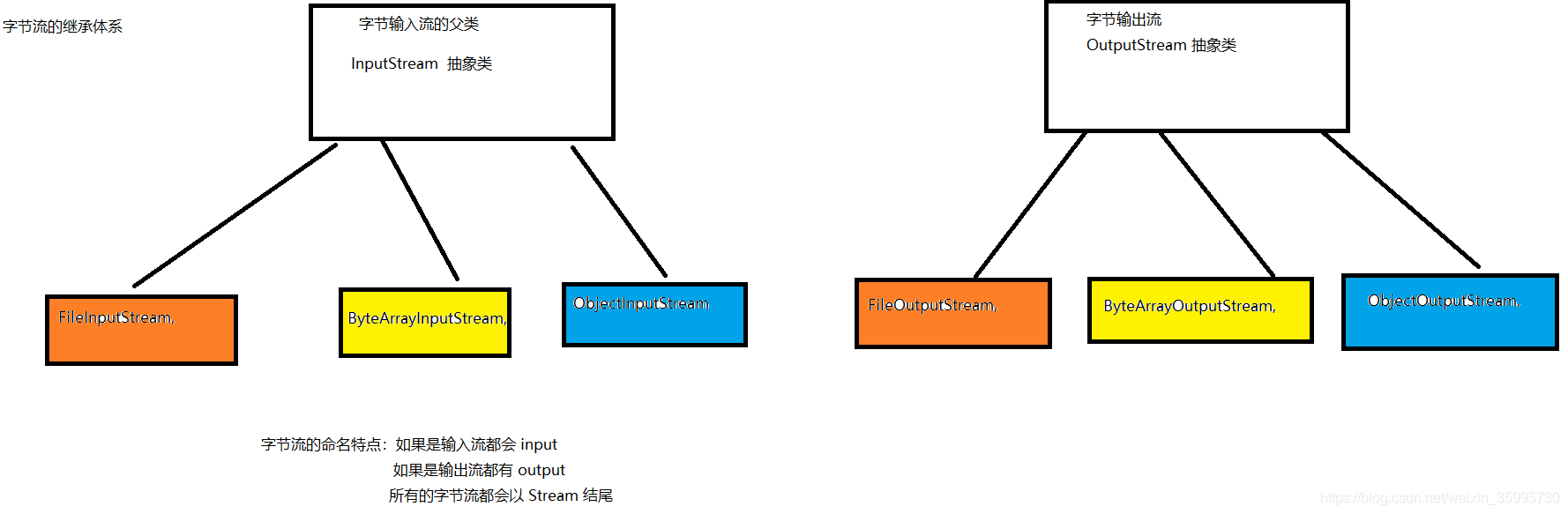 * JAVA字节流命名特点:
* JAVA字节流命名特点:
a. 如果是输入流都会以Input开头
b. 如果是输出流都会以Output开头
c. 所有字节流都会以Stram结尾! -
JAVA字符流继承体系:
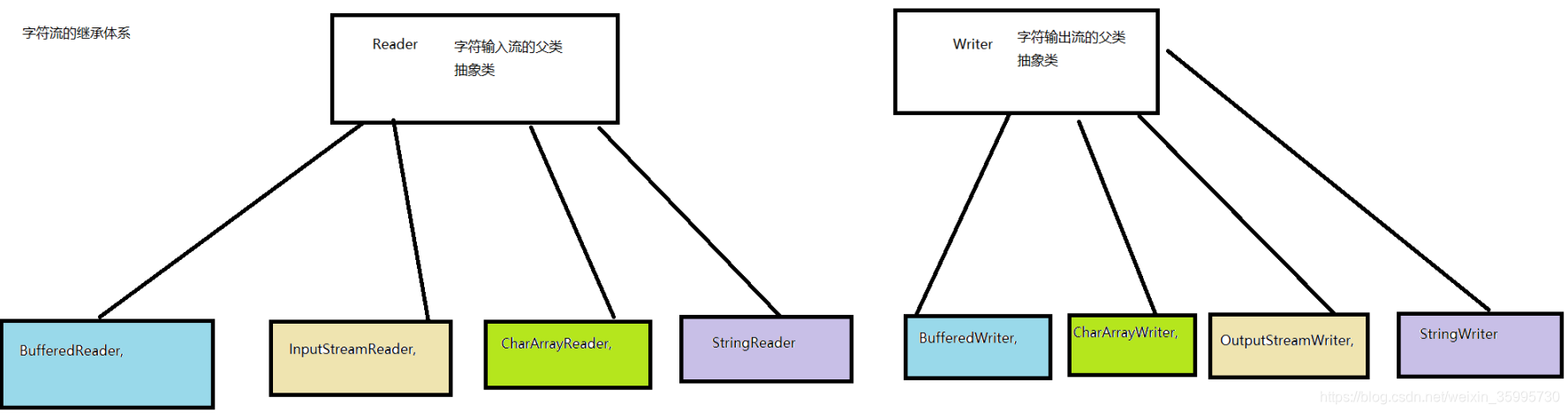 * JAVA字符流命名特点:
* JAVA字符流命名特点:
a. 输入流都以Reader结尾
b. 输出流都以Writer结尾 -
注:由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。
-
什么情况下使用哪种流呢?
a. 如果数据所在的文件通过windows自带的记事本打开并能读懂里面的内容,就用字符流。其他用字节流。(一般处理文本字符串的时候才用字符流!!!)
b. 如果处理其他文件,则用字节流。
JAVA字节流:
JAVA字节输出流——FileOutputStream
-
引入:
a. 我们发现OutputStream是一个抽象类,我们不能对其进行直接实例化,而我们需要使用子类对其进行实例化.那么选择哪个子类呢?
b. 我们现在操作的是文件所以我们选择的是FileOutputStream -
构造方法:
FileOutputStream(File file) FileOutputStream(String name) -
特点:
a. 使用时,需要抛出异常(防止出错)
b. 输出流所关联的文件如果不存在,则会自动创建对应的文件 -
FileOutputStream的三个write()方法
public void write(int b): 写一个字节 超过一个字节 砍掉前面的字节 public void write(byte[] b): 写一个字节数组 public void write(byte[] b,int off,int len):写一个字节数组的一部分 -
案例演示:(FileOutputStream写出数据)
FileOutputStream out = new FileOutputStream("a.txt"); //我们使用输入流,往文件中写入数据 一次写入一个字节 out.write(97); out.write(98); out.write(99); out.write(300); //如果你超过一个字节的范围,会丢弃掉多余字节 ------------------------------------------ 一次写入一个字节数组 byte[] bytes = {100, 101, 102, 103, 104, 105}; out.write(bytes); System.out.println(new String(bytes)); ------------------------------------------ 一次写入字节数组的一部分 out.write(bytes, 0, 3); //一次写入字节数组的一部分 ------------------------------------------ 利用字节数组的形式将一个字符串写入文件:(注意!) String str = "我是不是你最疼爱的人,你为什么不说话"; byte[] bytes1 = str.getBytes(); //解码 utf-8 out.write(bytes1); out.write(bytes1,0,12); ------------------------------------------ //流使用完毕要释放资源 out.close();问题:汉字字符串获得的getBytes()返回的是什么?
这块儿的解释是这样:因为汉字的编码(按照utf-8格式来进行编码),编码返回后的汉字的Bytes数组跟我们平常定义的Bytes数组无异,只不过在写入文件的时候,它能还原出汉字(而不是根据ASCII来写入)。
参考UTF-8编码表可知,由于UTF-8在存储汉字的时候,会有一种特殊的编码格式,根据这种编码格式,在解码的时候,就可以知道接下来的几个字节会构成一个汉字,从而将这些字节解码为一个汉字。如果写入的数字正好凑成一个或多个汉字,它也会这样写入。
个人以为:在JAVA中一个字符占两个字节,正好可以存储下Unicode的编码后的Unicode字符。(即:在计算机内存中,字符的表示都是通过Unicode解码编码进行存储的,只是在网络传输或者硬盘存储的时候,为了节省内存才转换为:UTF-8进行存储的!)
参考链接:Unicode 和 UTF-8 有什么区别 -
注意事项:
(1) 创建字节输出流对象了做了几件事情?
a:调用系统资源创建a.txt文件
b:创建了一个fos对象
c:把fos对象指向这个文件
(2) 为什么一定要close()?
a: 通知系统释放关于管理a.txt文件的资源
b: 让Io流对象变成垃圾,等待垃圾回收器对其回收 -
FileOutputStream写出数据实现换行:
系统 换行符号 windows \r\n Linux \n Mac \r 示例:
out.write("\r\n".getBytes()); //写入换行符 -
FileOutputStream写出数据如何实现数据的追加写入:
(注意:默认的是,你每次运行,都会覆盖之前文件中的数据)FileOutputStream(File file, boolean append) 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。 FileOutputStream(String name, boolean append) 创建一个向具有指定 name 的文件中写入数据的输出文件流。示例:
public class MyTest2 { public static void main(String[] args) throws IOException { //参数2:true 代表追加写入,不会重新覆盖文件中之前的数据 FileOutputStream out = new FileOutputStream("e.txt",true); out.write("江畔何人初见月".getBytes()); out.write("\r\n".getBytes()); out.write("江月何年初照人".getBytes()); out.write("\r\n".getBytes()); out.close(); } } -
流的移除处理:(为了安全考虑,在这种情况下就需要手动处理异常,而不是简单的抛出异常!)
public class MyTest { public static void main(String[] args) { //流的移除处理 FileOutputStream out=null; try { out = new FileOutputStream("a.txt"); out.write(200); } catch (IOException e) { e.printStackTrace(); }finally { try { if(out!=null){ out.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
JAVA字节输入流——FileInputStream:
- 构造函数:
注意:输入流所关联的文件,如果不存在就会报错//文件是输入流:读文件中的数据 FileInputStream(File file) 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。 FileInputStream(String name) 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。 - 读取数据的方法:
int read(): 一次读取一个字节,如果没有数据返回的就是-1,有的话,返回的是该字节的大小。(连续读取一个字节的话,迟早会读到-1去(应该是指针在偏移)) int read(byte[] b): 一次读取一个字节数组(返回的是读取的有效长度,这个读入的一部分字节,都是从被读文件的头部开始的!长度为指定的长度,连续读取也会读到末尾去,最后一次有效数组的长度很有可能不是指定的数组长度!) int read(byte[] b,0,len):一次读取一部分内容到字节数组中去!(占用的是字节数组0~len范围的空间!) - 示例:(一次读取一个字节)
public class MyTest { public static void main(String[] args) throws IOException { FileInputStream in = new FileInputStream("a.txt"); //读取文件中的数据 int b = in.read();//一次读取一个字节,返回的是这个字节数据,如果读取不到,返回 -1 我们会拿-1 判断他文件是否读取完 System.out.println(b); b = in.read();//一次读取一个字节 System.out.println(b); b = in.read();//一次读取一个字节 System.out.println(b); //释放资源 in.close(); } } - 示例:(一次一个字节数组)
public class MyTest2 { public static void main(String[] args) throws IOException { FileInputStream in = new FileInputStream("a.txt"); //创建一个空的字节数组,充当缓冲区 byte[] bytes = new byte[1024]; //返回值是他读取到的有效的字节个数 int len = in.read(bytes); 这里只读取了一个数组的长度(因为a.txt文件本身就很小!) for (byte aByte : bytes) { System.out.println(aByte); } System.out.println(len); String s = new String(bytes,0,len);//利用构造函数重新生成字符串(这里面应该也是牵扯到了编码的问题,读取到内存后存储的形式是:Unicode) // String s = new String(bytes,0,len,"UTF-8");(这条语句与上面的语句是等价的!指定了解码的格式!) System.out.println(s); //释放资源 in.close(); } } - 示例:(一次读取一部分字节到字节数组中去!)
public class MyTest3 { public static void main(String[] args) throws IOException { FileInputStream in = new FileInputStream("a.txt"); byte[] bytes = new byte[1024]; //一次读取一部分字节,填入到缓冲区数组 int len = in.read(bytes, 10, 20); //只占用bytes数组的10~20索引的空间! // System.out.println(len); for (byte aByte : bytes) { System.out.println(aByte); } in.close(); } } ---------------
JAVA字节流案例:(文件复制)
- 方法:
a. 读一个字节,写一个字节。(效率太低!原因:是循环次数太多!)
b. 一个缓存数组的读写:
注意:数组读写也可以连续读写,直到返回值为-1为止!import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; public class Test3 { public static void main(String[] args) throws IOException { FileInputStream in = new FileInputStream("C:\\Users\\Administrator\\Desktop\\station1_0_Sat Jul 13 22_56_11 2019_9.mp4"); FileOutputStream out = new FileOutputStream("test.mp4"); // 方式:按照数组进行缓存,然后保存! // byte[] bytes = new byte[1024 * 4]; // 4KB读写大概是:487毫秒 byte[] bytes = new byte[1024 * 8]; // 8KB读写大概是:328毫秒 int len = 0; long start = System.currentTimeMillis(); //开始计时! while ((len = in.read(bytes))!=-1){ out.write(bytes,0,len); //这里的写法尤其要注意,千万不能直接out.write(bytes),这样最后一次读写会少一些! } long end = System.currentTimeMillis(); //结束计时! System.out.println("总共耗时:"+(end-start)+"毫秒!"); // 释放文件: in.close(); out.close(); } }
结论:操作文件时候,一定要加入缓冲区,差距很大!
JAVA字节流——高效字节输入输出流:
- BufferedOutputStream :写出数据!
- BufferedInputStream:读入数据!
- 缓冲思想:
a. 字节流一次读写一个数组的速度明显比一次读写一个字节的速度快很多,
b. 这是加入了数组这样的缓冲区效果,java本身在设计的时候,
c. 也考虑到了这样的设计思想(装饰设计模式后面讲解),所以提供了字节缓冲区流。 - BufferedOutputStream的构造方法:
BufferedInputStream(InputStream in) 创建一个新的缓冲输出流,以将数据写入指定的底层输出流。 - BufferedInputStream的构造方法:
总结:如果用数组流的读写方法的话,高效流和普通流其实差距不是很大!BufferedInputStream(InputStream in) 创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 BufferedInputStream(InputStream in, int size) 创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 ``` * 示例: ```java public class MyTest { public static void main(String[] args) throws IOException { copy0(); //高效的流 19毫秒 copy1(); //原始的流 14毫秒 } private static void copy0() throws IOException { //高效的字节输入输出流 //Ctrl+H 看一个类的继承关系 BufferedInputStream bis = new BufferedInputStream(new FileInputStream("烟花易冷Live_林志炫.mp3"), 1024); BufferedOutputStream bos= new BufferedOutputStream(new FileOutputStream("C:\\Users\\ShenMouMou\\Desktop\\a.mp3")); //读取一个字节写入一个字节 //一次读取一个字节,写一个字节来复制音乐 int len = 0;//用来记录读取到的字节 long start = System.currentTimeMillis(); byte[] bytes = new byte[1024 * 8]; while ((len = bis.read(bytes)) != -1) { bos.write(bytes,0,len); bos.flush(); } long end = System.currentTimeMillis(); bos.close(); bis.close(); System.out.println("复制完成耗时" + (end - start) + "毫秒"); } private static void copy1() throws IOException { File file = new File("烟花易冷Live_林志炫.mp3"); FileInputStream in = new FileInputStream(file); FileOutputStream out = new FileOutputStream("C:\\Users\\ShenMouMou\\Desktop\\" + file.getName()); //一次读取一个字节,写一个字节来复制音乐 int len = 0;//用来记录读取到的字节 byte[] bytes = new byte[1024 * 8]; long start = System.currentTimeMillis(); while ((len = in.read(bytes)) != -1) { out.write(bytes,0,len); out.flush(); } long end = System.currentTimeMillis(); in.close(); out.close(); System.out.println("复制完成耗时" + (end - start) + "毫秒"); } } - IDEA中快速抽象一个方法(选中需要抽象为函数的(多行)代码,然后点击:Crtl+Alt+m)
- IEDA中查看继承关系:选取一个类,然后按键:Ctrl+h 进行查看!
JAVA字符流:
- 由来:
 * 特点:只能针对于文本文件。
* 特点:只能针对于文本文件。
String类中的编码和解码问题:
- 编码: 就是把字符串转换成字节数组:(把看得懂的变成看不懂的: String – byte[])
public byte[] getBytes(); 使用平台的默认字符集(UTF-8)将此 String编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 public byte[] getBytes(String charsetName); 使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 - 解码: 把字节数组转换成字符串:(把看不懂的变成看得懂的: byte[] – String)
public String(byte[] bytes): 通过使用平台的默认字符集(UTF-8)解码指定的 byte 数组,构造一个新的 String。 public String(byte[] bytes, String charsetName) 通过使用指定的 charset 解码指定的 byte 数组,构造一个新的 String。 - 小结:使用什么字符集进行编码,那么就是使用什么字符集进行解码
JAVA字符输出流——OutputStreamWriter:
-
概念:OutputStreamWriter 是字符流通向字节流的桥梁,可使用指定的 码表 将要写入流中的字符编码成字节。
-
OutputStreamWriter的构造方法:(注意:所关联的文件如果不存在则自动创建)
OutputStreamWriter(OutputStream out): 根据平台默认编码(UTF-8)把字节流的数据转换为字符流。 OutputStreamWriter(OutputStream out,String charsetName): 根据指定编码把字节流数据转换为字符流。 -
字符流的五种写入方式:
public void write(int c) 写一个字符 public void write(char[] cbuf) 写一个字符数组 public void write(char[] cbuf,int off,int len) 写一个字符数组的 一部分 public void write(String str) 写一个字符串 public void write(String str,int off,int len) 写一个字符串的一部分 -
示例:
public class MyTest { public static void main(String[] args) throws IOException { //IO:字节流:可以读写任意类型的文件,比如文本文件,音频,视频等所有文件。 //字节流的父类 // InputStream 抽象类 字节输入流的父类 // OutputStream 抽象类 字节输出流的父类 // FileInputStream (字节流的子类) // FileOutputStream (字节流的子类) // BufferedOutputStream(字节流的子类) // BufferedInputStream (字节流的子类) //字符流:他只能读写文本文件 //Reader 抽象类 字符输入流的父类 //Writer 抽象类 字符输出流的父类 //输出流,所关联的文件如果不存在则自动创建 OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream("a.txt")); //往文件中写入数据 out.write('你'); //一次写入一个字符 out.write('好'); //字符流记得要刷新一下 out.flush(); out.write("听说李小璐离婚了"); //一次写入一个字符串 out.write("皮皮虾我们走,去找一个蓝朋友",0,6); //一次写入字符串的一部分, out.write("\r\n"); out.write("皮皮虾我们走,去找一个蓝朋友", 7, 7); //一次写入字符串的一部分, out.write("\r\n"); char[] chars = {'a', 'b', 'c', 'd', '爱', '你', '呦'}; out.write(chars); //一次希尔一个字符数组 out.write("\r\n"); out.write(chars,4,3);//一次写入字符数组的一部分 //释放资源 out.close(); //刷新并关闭 } }注意:字符流的构造函数需要传入一个字节流的实例对象作为参数!
重点:字符流写完以后记得要刷新一下!(out.flush()) -
out.close()和 out.flush() 的区别:
- out.close() :将内存中的数据刷入硬盘,并且关闭了文件句柄
- out.flush() :将内存中的数据刷入硬盘
- 建议:写一部分刷新一部分进硬盘(一次性刷入硬盘不好)
JAVA字符输入流——InputStreamReader:
-
概念:InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。
-
构造方法:
InputStreamReader(InputStream is):用平台默认的编码(UTF-8)读取数据 InputStreamReader(InputStream is,String charsetName):用指定的编码读取数据 -
示例:
public class MyTest { public static void main(String[] args) throws IOException { //输入流 所关联的文件,如果不存在就报错 InputStreamReader in = new InputStreamReader(new FileInputStream("c.txt")); //读取文件中的数据 int ch = in.read(); //一次读取一个字符,如果读取不到返回-1 使用-1 就可以判断文件释放读取完毕 System.out.println((char)ch); ch = in.read(); //一次读取一个字符 System.out.println((char) ch); in.close(); } }注意:输入流所关联的文件,如果不存在就报错!
-
字符流的两种读取方式:(与FileInputStream类似!)
public int read() 一次读取一个字符 public int read(char[] cbuf) 一次读取一个字符数组 如果没有读到 返回-1 -
示例:(使用字符流来复制文本文件,一次一个字符!)
public class MyTest3 { public static void main(String[] args) throws IOException { //使用字符流来复制文本文件 InputStreamReader in = new InputStreamReader(new FileInputStream("MyTest.java")); OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream("C:\\Users\\ShenMouMou\\Desktop\\a.txt")); //一次读取一个字符,写一个字符来复制 int len=0;//定义一个变量,来记录读取的字符 while ((len=in.read())!=-1){ out.write(len); out.flush(); } //释放资源 in.close(); out.close(); } }问题: in.read()(获得一个字符)获得的数值是int类型的,为什么是int类型的?
回答:参考Link,为了解决返回为-1的不连续读取的情况!
(这种说法到底是否正确?那不同编码规则的文件返回的Int类型的数字为何是相同的?总感觉这里已经转化为Unicode了,但是如果已经转换为Unicode了,还需要用Int类型来进行接收吗?)问题:int和char类型的相互转换,其利用的码表是什么?(应该就是Unicode码表)
回答: char类型是两个字节(符合Unicode定义的存储长度!)
问题:是不是除了固定的一部分方法外,其他方法操作文件,都会使得文件指向的指针发生偏移!
回答:是
问题:利用Reader读出来的int数值范围是多少?是否是指定编码表的范围吗?打印一个试查看!
回答:应该是两个字节范围之内的的Int数值。因为char类型的范围只有两个字节,也就是Unicode的编码范围!
-
示例:(使用字符流来复制文本文件,一次读写一个字符数组!)
public class MyTest4 { public static void main(String[] args) throws IOException { InputStreamReader in = new InputStreamReader(new FileInputStream("MyTest.java")); OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream("C:\\Users\\ShenMouMou\\Desktop\\b.txt")); //定义一个字符数组,来充当缓冲区 char[] chars = new char[1000]; //定义一个变量,用来记录读取到的有效字符个数 int len=0; while ((len=in.read(chars))!=-1){ System.out.println("循环次数"); out.write(chars,0,len); out.flush(); } //释放资源 in.close(); out.close(); } } -
问题示例:
public class MyTest2 { public static void main(String[] args) throws UnsupportedEncodingException { String str = "今晚小树林见"; System.out.println(str.getBytes("GBK").length); System.out.println(str.getBytes("UTF-8").length); } } ----------- 输出: 12 18结论:这个示例的结果不一致才是编码出错的原因,但估计:同一个字的在码表中的数值是一样的,但通过刚才打印,发现获得的数值也不相同,没法解释这里获得的int类型的len,因为:这个len不管是用gbk还是utf-8都能写入到文件中去,且结果一致!
便捷流(FileReader和FileWriter):
-
由来:转换流的名字比较长,而我们常见的操作都是按照本地默认编码实现的,所以,为了简化我们的书写,转换流提供了对应的子类。
-
概念:对字符流操作进行了再次封装(但没有自己特性的功能,只是简短了调用难易程度)
-
缺点:不能指定编码表,用的是平台默认码表。
-
字符流便捷类: 因为转换流的名字太长了,并且在一般情况下我们不需要制定字符集,
于是java就给我们提供转换流对应的便捷类 -
转换表:
原始 便捷流 utputStreamWriter FileWriter nputStreamReader FileReader -
示例:
public class MyTest { public static void main(String[] args) throws IOException { //便捷字符流,的缺点是不能指定编码表,用的是平台默认码表 FileReader in = new FileReader("a.txt"); FileWriter out = new FileWriter("aa.txt"); //定义一个字符数组,来充当缓冲区 char[] chars = new char[1000]; //定义一个变量,用来记录读取到的有效字符个数 int len = 0; while ((len = in.read(chars)) != -1) { System.out.println("循环次数"); out.write(chars, 0, len); out.flush(); } //释放资源 in.close(); out.close(); } }
高效字符流的基本使用:
-
高效的字符输出流: BufferedWriter
构造方法:public BufferedWriter(Writer w) -
高效的字符输入流: BufferedReader
构造方法:public BufferedReader(Reader e) -
特有的方法:(较为实用,高效!)
BufferedWriter: public void newLine():根据系统来决定换行符 具有系统兼容性的换行符 BufferedReader: public String readLine():一次读取一行数据 是以换行符为标记的 读到换行符就换行 没读到数据返回null -
解耦:程序和数据解耦!
-
示例:(采用读取一行写入一行的方式来复制文本文件)
public class MyTest2 { public static void main(String[] args) { //高效的字符流里面有自己特有的方法比较好用 // BufferedReader readLine() 一次读取一行内容 // BufferedWriter newLine(); 写入换行符他具有平台兼容性 //采用读取一行写入一行的方式来复制文本文件 BufferedReader bfr = null; BufferedWriter bfw = null; try { bfr = new BufferedReader(new InputStreamReader(new FileInputStream("MyTest.java"))); bfw = new BufferedWriter(new FileWriter("test.java")); //定义一个变量来记录读取到的每一行 String line = null; //String s = bfr.readLine(); while ((line = bfr.readLine()) != null) { //注意一行一行的读取,读取不到返回null bfw.write(line); //bfw.write("\r\n"); bfw.newLine();//写个换号符 bfw.flush(); } } catch (IOException e) { e.printStackTrace(); } finally { try { if (bfr != null) { bfr.close(); } if (bfw != null) { bfw.close(); } } catch (IOException e) { e.printStackTrace(); } } } }
案例演示:
- 案例1:(复制多级文件夹)
package org.westos.demo4; import java.io.*; public class Demo { public static void main(String[] args) throws IOException { // 复制文件夹: File in = new File("C:\\Users\\Administrator\\Desktop\\img3"); File out = new File("C:\\Users\\Administrator\\Desktop\\img_out"); copyDir(in, out); } private static void copyDir(File in,File out) throws IOException { if(in.isDirectory()){ out = new File(out,in.getName()); out.mkdirs(); } for (File file : in.listFiles()) { if (file.isFile()){ copyFile(out,file); }else{ copyDir(file,out); } } } private static void copyFile(File dir, File file) throws IOException { FileInputStream in = new FileInputStream(file); File files = new File(dir,file.getName()); FileOutputStream out = new FileOutputStream(files); byte[] bytes = new byte[1024 * 8]; int len = 0; while((len=in.read(bytes))!=-1){ out.write(bytes,0,len); } } } - 案例2:(复制多级文件夹并对其中的.png的文件更名为.jpg)
package org.westos.demo4; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class Demo2 { public static void main(String[] args) throws IOException { // 复制文件夹: File in = new File("C:\\Users\\Administrator\\Desktop\\img3"); File out = new File("C:\\Users\\Administrator\\Desktop\\img_out2"); copyDir(in, out); } private static void copyDir(File in,File out) throws IOException { if(in.isDirectory()){ out = new File(out,in.getName()); out.mkdirs(); } for (File file : in.listFiles()) { if (file.isFile()){ copyFile(out,file); }else{ copyDir(file,out); } } } private static void copyFile(File dir, File file) throws IOException { File files = null; if(file.getName().endsWith(".png")){ files = new File(dir,file.getName().substring(0,file.getName().lastIndexOf(".png"))+".jpg"); }else{ files = new File(dir,file.getName()); } FileInputStream in = new FileInputStream(file); FileOutputStream out = new FileOutputStream(files); byte[] bytes = new byte[1024 * 8]; int len = 0; while((len=in.read(bytes))!=-1){ out.write(bytes,0,len); } } } - 案例3:(将手动收入的成绩自动排序后写入文件当中!)
package org.westos.demo4; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; import java.util.Comparator; import java.util.Scanner; import java.util.TreeSet; public class Demo3 { public static void main(String[] args) throws IOException { TreeSet<StudentS> studentS = new TreeSet<>(new Comparator<StudentS>() { @Override public int compare(StudentS o1, StudentS o2) { int num = o1.total_score - o2.total_score; int num2 = num == 0 ? o1.getName().compareTo(o2.getName()) : num; return num2; } }); for(int i=0;i<3;i++){ Scanner scanner = new Scanner(System.in); System.out.println("请输入第"+i+"个学生的姓名:"); String name = scanner.nextLine(); System.out.println("请输入第"+i+"个学生的语文成绩:"); int chinese_score = scanner.nextInt(); System.out.println("请输入第"+i+"个学生的数学成绩:"); int math_score = scanner.nextInt(); System.out.println("请输入第"+i+"个学生的英语成绩:"); int english_score = scanner.nextInt(); studentS.add(new StudentS(name,chinese_score,math_score,english_score)); } int x =0; BufferedWriter out = new BufferedWriter(new FileWriter("seozheng.txt")); out.write(String.format("%-10s%-15s%-15s%-15s%-15s%-15s","No","Name","Chinese_score","Math_score","English_score","Total_score")); out.newLine(); System.out.println(String.format("%-10s%-15s%-15s%-15s%-15s%-15s","No","Name","Chinese_score","Math_score","English_score","Total_score")); for (StudentS student : studentS) { System.out.println(String.format("%-10s%-15s%-15s%-15s%-15s%-15s",x++,student.getName(),student.getChinese_score(),student.getMath_score(),student.getEnglish_score(),student.getTotal_score())); out.write(String.format("%-10s%-15s%-15s%-15s%-15s%-15s",x++,student.getName(),student.getChinese_score(),student.getMath_score(),student.getEnglish_score(),student.getTotal_score())); out.newLine(); out.flush(); } out.close(); } } class StudentS { String name; int chinese_score; int math_score; int english_score; int total_score; public String getName() { return name; } public StudentS(String name, int chinese_score, int math_score, int english_score) { this.name = name; this.chinese_score = chinese_score; this.math_score = math_score; this.english_score = english_score; this.total_score = chinese_score+math_score+english_score; } public void setName(String name) { this.name = name; } public int getChinese_score() { return chinese_score; } public void setChinese_score(int chinese_score) { this.chinese_score = chinese_score; } public int getMath_score() { return math_score; } public void setMath_score(int math_score) { this.math_score = math_score; } public int getEnglish_score() { return english_score; } public void setEnglish_score(int english_score) { this.english_score = english_score; } public int getTotal_score() { return total_score; } public void setTotal_score(int total_score) { this.total_score = total_score; } }
Java中字节流和字符流的read()方法为什么返回的值是int类型:
-
参考: link
-
个人理解:
a. 首先,Java中的char类型本身就是利用Unicode编码来进行存储的。link
b. 因为Unicode只有两个字节的长度,其中不能完全收录所有的汉字,所以Unicode中也会出现转换不了的情况(比如:(char)(xxxxx—>int))
c. 上面已经阐述了为何Java中字节流和字符流都有返回为int类型的情况,其实就是为了避免还没读到最后就断尾的情况。这个解释对于Byte类型的数据还比较好理解,对于字符类型,感觉差点味道。int类型(4个字节)能够表示的返回很大,这个读回来的数据既然可以用char(两个字节来表示),那么必然可以用int来进行表示。
d. 事实上,由于Unicode本身就不可能存储那么多汉字,如果直接转回来的数字到底有没有直接通过Unicode转换的话,那么它怎么可能直接利用(char)强制类型转化,就得到明确的字符值? -
问题:
比如:我有两个文件1111.txt(UTF-8) 和 2222.txt(GBK),它俩中间的内容都是一个汉字:“我”。
我分别利用不同解码方式的字符流的方式去进行读取,读取回来的数值是一样的。
(为什么会一样呢?如果中间经过了一层Unicode转换的话,那么如果文件中出现了unicode中不存在的中文字符(特殊字符),那返回的int感觉是不是有问题?(想不出来思绪!)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









