






Kafka如何支持十万甚至百万的并发呢?
答案是分区。Kafka的一个Topic可以有一个至多个Partition,并且可以分布到多台机器上。
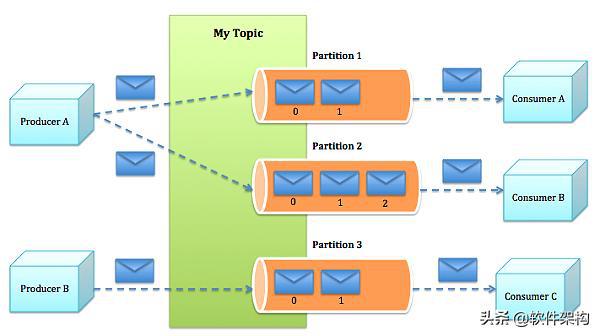
Kafka只保证在一个Partition内部,消息是有序的,但是,存在多个Partition的情况下,Producer发送的3个消息会依次发送到Partition-1、Partition-2和Partition-3,Consumer从3个Partition接收的消息并不一定是Producer发送的顺序,因此,多个Partition只能保证接收消息大概率按发送时间有序,并不能保证完全按Producer发送的顺序。这一点在使用Kafka作为消息服务器时要特别注意,对发送顺序有严格要求的Topic只能有一个Partition。

Kafka的另一个特点是消息发送和接收都尽量使用批处理,一次处理几十甚至上百条消息,比一次一条效率要高很多。
最后要注意的是消息的持久性。Kafka总是将消息写入Partition对应的文件,消息保存多久取决于服务器的配置,可以按照时间删除(默认3天),也可以按照文件大小删除,因此,只要Consumer在离线期内的消息还没有被删除,再次上线仍然可以接收到完整的消息流。这一功能实际上是客户端自己实现的,客户端会存储它接收到的最后一个消息的offsetId,再次上线后按上次的offsetId查询。offsetId是Kafka标识某个Partion的每一条消息的递增整数,客户端通常将它存储在ZooKeeper中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









