






原标题:干货 | NLP数据处理工具——torchtext
本文为 AI 研习社社区用户 @Dendi独家投稿内容,欢迎扫描底部社区名片访问 @Dendi的主页,查看更多内容。
01.概述
在处理NLP任务时除了需要优秀的神经网络还需要方便、高效的数据预处理工具。今天介绍一款优秀的NLP数据处理工具torchtext。
NLP常见的数据预处理工作如下:
Load File:数据文件加载;
Tokenization:分词;
Create Vocabulary:创建字典;
Indexify:将词与索引进行映射;
Word Vectors:创建或加载词向量;
Padding or Fix Length:按长度对文本进行补齐或截取;
Dataset Splits:划分数据集(如将数据集划分问训练集、验证集、测试集);
Batching and Iterators:将数据集按固定大小划分成Batch;
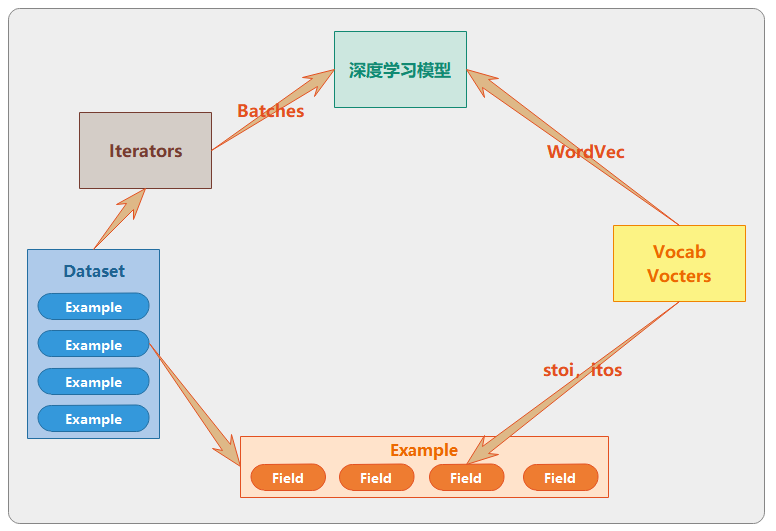
使用torchtext完成以上工作:
使用 torchtext.data.Field 定义样本各个字段的处理流程(分词、数据预处理等);
使用 torchtext.data.Example 将 torchtext.data.Field 处理成一条样本;
使用 torchtext.data.Dataset 将 torchtext.data.Example 处理成数据集,也可对数据集进行划分等工作;
使用 torchtext.data.Iterators 将 torchtext.data.Dataset 按照 batch_size 组装成 Batch 供模型训练使用;
使用torchtext.data.vocab和torchtext.data.Vectors创建词典、词和索引的一一对应、下载或使用预训练的词向量等;
02.安装
使用如下命令安装:pip install torchtext
03.文档
官方教程:https://torchtext.readthedocs.io/en/latest/index.html
04.主要的Package
torchtext.datatorchtext.data.Dataset:数据集;
torchtext.data.Example:样本;
torchtext.data.Fields:样本的属性(如:content、label);
torchtext.data.Iterators:将数据集封装成Batch,并提供迭代器;
tochtext.vocab
torchtext.vocab.Vocab:词典相关;
torchtext.vocab.Vectors:词向量相关;
05.实践
05-1.Field
API
classtorchtext.data.Field(
sequential=True, use_vocab=True, init_token=None, eos_token=None,
fix_length=None, dtype=torch.int64, preprocessing=None, postprocessing=None,
lower=False, tokenize=None, tokenizer_language='en', include_lengths=False,
batch_first=False, pad_token='', unk_token='', pad_first=False,
truncate_first=False, stop_words=None, is_target=False
)
#...
def build_vocab(self, *args, **kwargs)
重要的参数:
sequential:是否是可序列化数据(类似于字符串数据),默认值是 True;
user_vocab:是否使用 Vocab 对象,如果取 False,则该字段必须是数值类型;默认值是True;
tokenize:是一个 function 类型的对象(如 string.cut 、jieba.cut 等),用于对字符串进行分词;
batch_first:如果该属性的值取 True,则该字段返回的 Tensor 对象的第一维度是 batch 的大小;默认值是False;
fix_length:该字段是否是定长,如果取 None 则按同 batch 该字段的最大长度进行pad;
重要函数:
build_vocab:为该Field创建Vocab;
Code Demo
数据集(第一个字段是label, 第二个字段是content):
0 我不退我也不买。我就看戏
0 我建不了系统拒绝
0 跟诸葛撞单了
0 305没了
1 我今天很开心,很开心,微信
1 那是微信号
1 高材生你不用彩虹,如果哪天想跟我的单可以加我微信
1 高材生可以加我微信
1 群主你微信多少
1 老哥,有没有微信群啥的?一起聊球呀?
...
代码:
# 分词函数
defcontent_tokenize(text):
return[item foritem instr(text)]
# 创建content字段的Field
CONTENT = data.Field(sequential=True, tokenize=content_tokenize, batch_first=True)
# 创建label字段的Field
LABEL = data.Field(sequential=False, use_vocab=False)
# 为 CONTENT 字段创建词向量
CONTENT.build_vocab(data_set)
05-2.Example
API
classtorchtext.data.Example:
@classmethod
fromCSV(data, fields, field_to_index=None)
@classmethod
fromJSON(data, fields)
@classmethod
fromdict(data, fields)
@classmethod
fromlist(data, fields)
@classmethod
fromtree(data, fields, subtrees=False)
该类有5个类函数,可以从csv、json、dict、list、tree等数据结构中创建Example,常用的是fromlist;
05-3.Dataset
API
classtorchtext.data.Dataset(examples, fields, filter_pred=None)
重要参数:
examples:Example对象列表;
fields:格式是List(tuple(str, Field)),其中 str 是 Field 对象的描述;
Code Demo
# 读取数据
df = pd.read_csv('./datas/data.txt', sep=' ', encoding='utf8', names=['label', 'content'])
# 创建Field的list
fields = [('label', LABEL), ('content', CONTENT)]
examples = []
forlabel, content inzip(df['label'], df['content']):
examples.append(Example.fromlist([label, content], fields))
data_set = Dataset(examples, fields)
05-4.Vocab
API
classtorchtext.vocab.Vocab(
counter, max_size=None, min_freq=1, specials=[''],
vectors=None, unk_init=None, vectors_cache=None, specials_first=True
)
重要参数:
counter:collections.Counter 类型的对象,用于保存数据(如:单词)的频率;
vectors:预训练的词向量,可以是torch.vocab.Vectors类型,也可以是其他类型;
Code Demo
# 为 CONTENT 字段创建词向量
CONTENT.build_vocab(data_set)
05-5.Vectors
API
classtorchtext.vocab.Vectors(name, cache=None, url=None, unk_init=None, max_vectors=None)
重要参数:
name:保存word vectors的文件;
catch:word vectors文件的缓存目录,默认是.vector_cache;
url:如果缓存文件夹中不存在 word vectors文件,则去该url下载;
unk_init:是一个function 类型的对象,用来初始化词典中不存在的词向量;默认是Tensor.zero_;
max_vecotrs:int类型的数据,限制词典的大小;
Code Demo
# 使用预训练词向量
word_vectors = Vectors('./datas/embeddings/hanzi_embedding_150.bin', cache='./datas/embeddings/')
print(word_vectors.stoi)
结果:

06.结语
torchtext是一个很好用的文本处理工具,本文只是介绍了torchtext常用的功能,可以查看官方文档进一步学习。
* 封面图来源:https://www.developereconomics.com/nlp-wit-luis-api-ai
@Dendi的社区主页,获取更多动态
点击
,查看 @Dendi 的个人主页返回搜狐,查看更多
责任编辑:

















 1759
1759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









