



 自然语言处理(NLP)处理实际文字语言需用一系列算法。本文介绍了几种经典算法,包括HMM(隐马尔科夫模型)、维特比算法、EM算法、逻辑回归算法(LR算法),阐述了各算法的原理、应用及核心思想等。
自然语言处理(NLP)处理实际文字语言需用一系列算法。本文介绍了几种经典算法,包括HMM(隐马尔科夫模型)、维特比算法、EM算法、逻辑回归算法(LR算法),阐述了各算法的原理、应用及核心思想等。

Nature Language Processing(简称 NLP)在处理实际文字语言的时候,需要使用一系列的算法来进行处理,一般而言,整理下来有以下经典算法:
1.HMM(隐马尔科夫模型)
HMM 其中x = (q1, q2, ..., qN) 为隐状态序列,y = (o1, o2, ..., oN)为观测序列,要求预测的问题为:(q1,q2,...,qN)=argmaxP(q1,q2,...,qn|o1,o2,...,on),其中argmax 为函数,自变量y1,y2,...,yn取固定值的时候取到P(x1,x2,x3,....Xn)所对应的最大值。
HMM是一个五元组(O , Q , O0,A , B):
O:{o1,o2,…,ot}是状态集合,也称为观测序列。
Q:{q1,q2,…,qv}是一组输出结果,也称为隐序列。
Aij = P(qj|qi):转移概率分布
Bij = P(oj|qi):发射概率分布
O0是初始状态,有些还有终止状态。
在观测序列中,可以推断至隐序列。
2.维特比算法(Vitebe)
维特比算法的话其实就是动态路径优化算法,今天的数字通信、语音识别、机器翻译、拼音转汉字、分词等都有维特比算法的身影。
维特比算法的主要思想是从最短路径中求出最优路径,动态规划算法路径,然后反推出该路径。这个算法可以极大的减少路径规划,并通过最短路径求出最优路径。
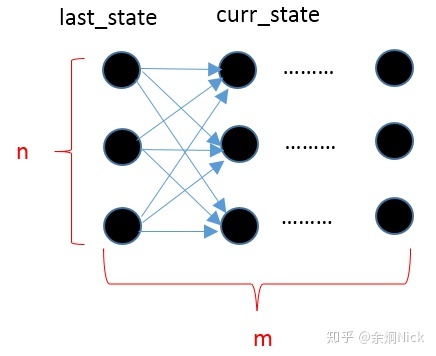
图1是几个状态的状态变量,从 Laststate 到 curr_state,状态变化的时间复杂度最大值为 O(n^M),这样的话会让人无法接受,因为时间复杂度受到矩阵路径的影响过大,假如采用了维特比算法以后,通过最短路径来求出最优路径,动态规划出最短路径,这样可以极大的降低时间复杂度,最大可以降低到O(N)级别。
3.EM算法
EM 算法是机器学习领域中的一大类算法
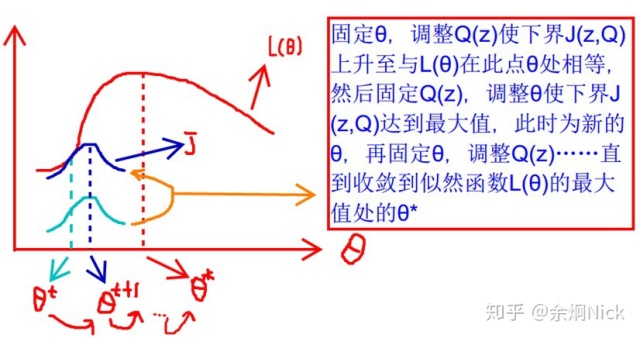
从浅蓝色的线到深蓝色的线其实就是完成了Qi(z)值的不断探索确定的过程,最终得到下界逼近似然函数的结果是后验概率,(实际上这里完成了E-step的操作)。然后很明显深蓝色的线条的最大值并不是相交的点,于是就将Qi(z)的值固定住,对θ的结果求导,进一步得到极大值点也就是θt+1这个位置,后续会继续从θ t+1接着上探,然后再相交,然后再固定住Q,继续对θ求极大值,这样不断的上探,变化,循环下去,就完成了对似然函数的下界的极大化的操作,这也就是整个EM算法的核心思想!
4.逻辑回归算法(LR 算法)
逻辑回归算法的话主要是用来解决分类问题,英文全称是 Logical Regressions.
实现方面的话,逻辑回归仅仅是对线性回归的计算结果加上了一个Sigmoid函数,将数值结果转化为了0到1之间的概率(Sigmoid函数的图像 一般来说并不直观,你仅仅须要理解对数值越大。函数越逼近1。数值越小,函数越逼近0)。接着我们依据这个概率能够做预測,比如概率大于0.5,则这封邮件 就是垃圾邮件,或者肿瘤是否是恶性的等等。从直观上来说,逻辑回归是画出了一条分类线。见下图。
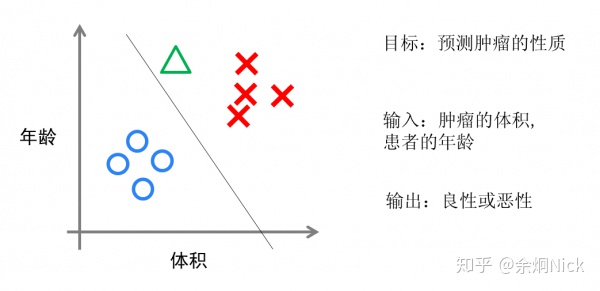
图3 逻辑回归算法
5.其余还有各类算法未一一列出。

















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









