






 本文探讨了在Scrapy框架中使用XPath选择器时如何处理HTML中的非断行空格(xa0)。通过unicodedata.normalize函数及XPath表达式实现对文本的规范化和过滤。
本文探讨了在Scrapy框架中使用XPath选择器时如何处理HTML中的非断行空格(xa0)。通过unicodedata.normalize函数及XPath表达式实现对文本的规范化和过滤。
1.参考
详细解释
unicodedata.normalize('NFKD',string) 实际作用???
Scrapy : Select tag with non-breaking space with xpath
>>> selector.xpath(u'''
... //p[normalize-space()]
... [not(contains(normalize-space(), "\u00a0"))]
normalize-space() 实际作用???
In [244]: sel.css('.content')
Out[244]: [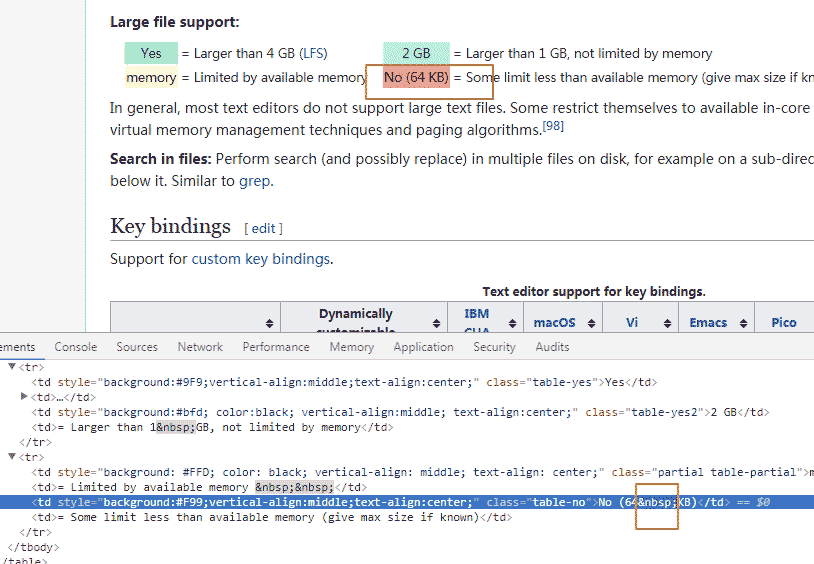
网页源代码表示为
memory= Limited by available memory No (64 KB)= Some limit less than available memory (give max size if known)实际传输Hex为:
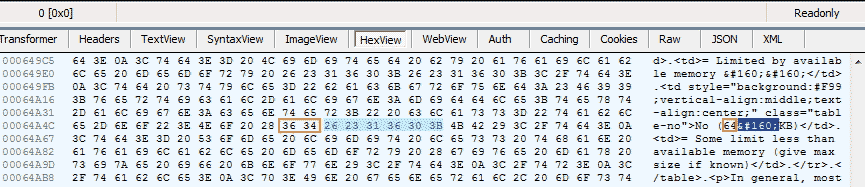
不间断空格的unicode表示为 u\xa0',保存的时候编码 utf-8 则是 '\xc2\xa0'
In [211]: for tr in response.xpath('//table[8]/tr[2]'):
...: print [u''.join(i.xpath('.//text()').extract()) for i in tr.xpath('./*')]
...:
[u'memory', u'= Limited by available memory \xa0\xa0', u'No (64\xa0KB)', u'= Some limit less than available memory (give max size if known)']
In [212]: u'No (64\xa0KB)'.encode('utf-8')
Out[212]: 'No (64\xc2\xa0KB)'
In [213]: u'No (64\xa0KB)'.encode('utf-8').decode('utf-8')
Out[213]: u'No (64\xa0KB)'
保存 csv 直接使用 excel 打开会有乱码(默认ANSI gbk 打开???,u'\xa0' 超出 gbk 能够编码范围???),使用记事本或notepad++能够自动以 utf-8 正常打开。

使用记事本打开csv文件,另存为 ANSI 编码,之后 excel 正常打开。超出 gbk 编码范围的替换为'?'
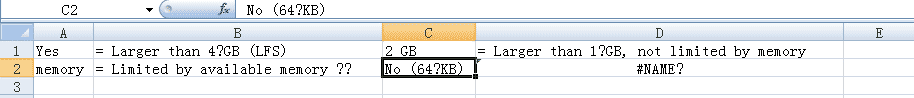
3.如何处理
.extract_first().replace(u'\xa0', u' ').strip().encode('utf-8','replace')
以上就是HTML转义字符&npsp;表示non-breaking space \xa0的详细内容,更多关于HTML转义字符\xa0的资料请关注脚本之家其它相关文章!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









