




简介:Java作为广泛使用的编程语言,其面试题目包含多个核心领域,从基础语法到JVM优化,涵盖了基础知识、面向对象、集合框架、多线程、异常处理、IO流、网络编程、数据库操作、设计模式等。应聘广州Java开发岗位者需深入理解这些知识点,以展现自己的理论知识和实际操作能力。同时,熟悉Java最新版本的特性将有助于在面试中脱颖而出。 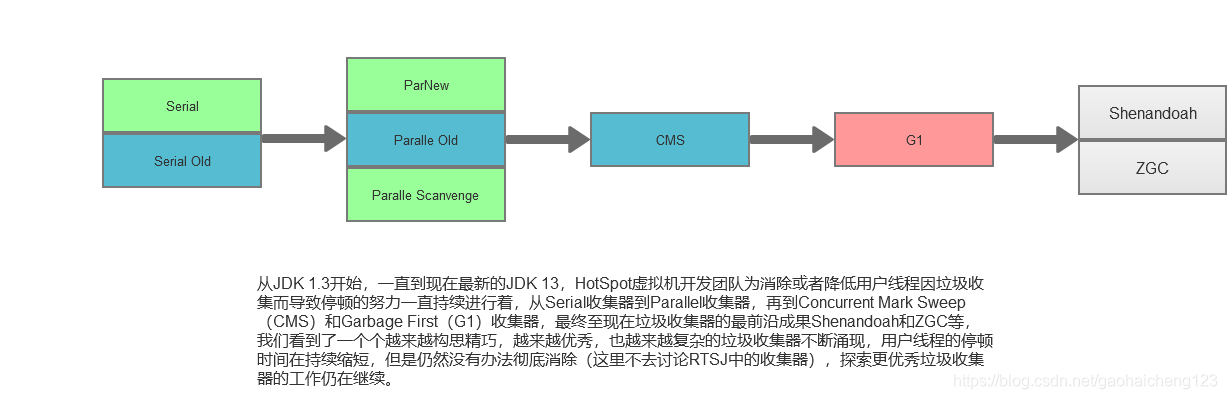
1. Java基础语法精讲
1.1 Java语言概述
Java是一种广泛使用的面向对象的编程语言,由Sun Microsystems公司于1995年发布。Java的设计初衷是“一次编写,到处运行”,它的跨平台特性来自于Java虚拟机(JVM),这意味着编译后的Java程序可以在任何安装了相应版本JVM的机器上执行。
1.2 基本数据类型与运算符
Java定义了八种基本数据类型,分为四类:
- 整数型:byte(1字节)、short(2字节)、int(4字节)、long(8字节)
- 浮点型:float(4字节)、double(8字节)
- 字符型:char(2字节,UTF-16编码)
- 布尔型:boolean(true/false)
基本数据类型的操作主要涉及算术运算符、关系运算符和逻辑运算符等。例如,算术运算符包括加(+)、减(-)、乘(*)、除(/)等,这些运算符用于执行数值计算。
int a = 10;
int b = 20;
int sum = a + b; // 加法运算
int product = a * b; // 乘法运算
在上述代码中,定义了两个整型变量 a 和 b 并进行加法和乘法运算,结果分别赋值给 sum 和 product 。
1.3 控制流程语句
控制流程语句用于控制程序的执行路径。Java中的控制语句主要包括条件语句(if-else)和循环语句(for、while、do-while)。
int number = 5;
if (number > 10) {
System.out.println("Number is greater than 10.");
} else {
System.out.println("Number is less than or equal to 10.");
}
for (int i = 0; i < 5; i++) {
System.out.println("The loop iteration is: " + i);
}
在此代码段中,首先使用条件语句检查变量 number 是否大于10,然后使用for循环打印从0到4的数字。
总结来说,Java基础语法为开发者提供了一系列强大的工具来创建程序逻辑,从基本数据类型和运算符到控制流程语句,这些都是构建更复杂程序的基础。掌握这些基础知识对于深入学习Java至关重要。
2. 面向对象编程深入理解
2.1 面向对象的核心概念
面向对象编程(OOP)是一种编程范式,它利用“对象”来设计软件。对象可以包含数据,表示为域或字段,以及代码,表示为方法。它基于现实世界建模,更符合人类的思维方式,大大提高了软件开发的效率。
2.1.1 类与对象的创建和使用
类是对象的蓝图或模板。对象是类的实例,具有类定义的属性和方法。创建对象的过程称为实例化。
下面是一个简单的Java类定义和对象创建的例子:
public class Person {
// 属性
private String name;
private int age;
// 构造方法
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 方法
public void introduce() {
System.out.println("Hello, my name is " + name + " and I am " + age + " years old.");
}
}
// 使用类创建对象
public class Main {
public static void main(String[] args) {
Person person = new Person("Alice", 30);
person.introduce();
}
}
分析: - Person 类定义了两个私有属性 name 和 age ,它们被封装在对象内部。 - 类包含一个构造方法,用来在创建对象时初始化对象的状态。 - introduce 方法允许对象展示自身信息。 - 在 Main 类中, person 对象通过 new 关键字创建,并调用了 introduce 方法。
对象的创建过程涉及内存分配、构造方法调用、成员变量初始化、方法区设置等步骤。在实际开发中,对象的创建是一个频繁的操作,需要优化构造方法和实例化过程来提升性能。
2.1.2 继承、封装、多态的原理及应用
继承、封装和多态是面向对象编程的三大特性。继承允许新创建的类(子类)继承父类的属性和方法,封装使对象的状态保持私有化并提供公共访问方法,多态允许子类重写或重载父类的方法,实现同一行为的不同表现形式。
继承
public class Animal {
protected String name;
public void eat() {
System.out.println(name + " is eating.");
}
}
public class Dog extends Animal {
public void bark() {
System.out.println("Woof!");
}
}
public class Main {
public static void main(String[] args) {
Dog dog = new Dog();
dog.name = "Buddy";
dog.eat(); // Buddy is eating.
dog.bark(); // Woof!
}
}
在上述代码中, Dog 类继承自 Animal 类,它自动拥有 Animal 类的 eat 方法。 Dog 类还可以添加自己特有的方法,如 bark 。
封装
封装是通过访问修饰符来实现的。在Java中, private 、 protected 、和 public 是常见的访问修饰符。它们定义了类成员的访问范围。
多态
public class Shape {
public void draw() {
System.out.println("Drawing a generic shape.");
}
}
public class Circle extends Shape {
@Override
public void draw() {
System.out.println("Drawing a circle.");
}
}
public class Rectangle extends Shape {
@Override
public void draw() {
System.out.println("Drawing a rectangle.");
}
}
public class Main {
public static void drawShapes(Shape[] shapes) {
for(Shape shape : shapes) {
shape.draw();
}
}
public static void main(String[] args) {
Shape[] shapes = {new Circle(), new Rectangle()};
drawShapes(shapes);
}
}
在以上代码中, drawShapes 方法可以接受 Shape 类型的对象数组。因为 Circle 和 Rectangle 都继承自 Shape ,它们都可以被视为 Shape 类型。当调用 draw 方法时,实际调用的是对象类型的方法,这体现了多态性。
2.2 面向对象设计原则
设计原则是面向对象设计的指导原则,它们帮助设计师创建灵活、可维护、可扩展的系统。其中最著名的设计原则是SOLID,它是一组面向对象设计原则的首字母缩写,包括单例原则(Single Responsibility Principle)、开放封闭原则(Open/Closed Principle)、里氏替换原则(Liskov Substitution Principle)、接口隔离原则(Interface Segregation Principle)和依赖倒置原则(Dependency Inversion Principle)。
2.2.1 SOLID原则详解
- 单例原则 :一个类应该只有一个实例,并提供一个全局访问点。
- 开放封闭原则 :类、模块、函数等应该对扩展开放,对修改关闭。
- 里氏替换原则 :子类可以替换其基类。
- 接口隔离原则 :不应该强迫客户依赖于它们不用的方法。
- 依赖倒置原则 :高层模块不应该依赖低层模块,两者都应该依赖其抽象。
以上原则帮助我们设计更加灵活、可维护的系统。理解这些原则并加以应用,对于提高软件的质量和可维护性至关重要。
2.2.2 设计原则在实际开发中的应用案例
面向对象的设计原则在软件开发过程中扮演着关键角色。它们不仅指导我们如何编写代码,还引导我们如何组织代码,以适应未来的变化。下面是一个应用SOLID原则的简单例子:
// 单一职责原则
public class ReportPrinter {
public void print(Report report) {
// 打印报告逻辑
}
}
// 开放封闭原则
public interface Report {
// 报告方法
}
public class SalesReport implements Report {
// 销售报告实现
}
public class FinanceReport implements Report {
// 财务报告实现
}
// 里氏替换原则
public class ReportPrinter {
public void print(Report report) {
if (report instanceof SalesReport) {
// 特定于销售报告的打印逻辑
} else if (report instanceof FinanceReport) {
// 特定于财务报告的打印逻辑
}
}
}
// 接口隔离原则
public interface PrintableReport {
void print();
}
public interface ExportableReport {
void exportToCSV();
}
public class SalesReport implements PrintableReport, ExportableReport {
public void print() {
// 打印逻辑
}
public void exportToCSV() {
// 导出CSV逻辑
}
}
// 依赖倒置原则
public class ReportGenerator {
private ReportStorage storage;
public ReportGenerator(ReportStorage storage) {
this.storage = storage;
}
// 生成和存储报告
}
public interface ReportStorage {
void store(Report report);
}
public class DatabaseStorage implements ReportStorage {
public void store(Report report) {
// 数据库存储逻辑
}
}
在以上代码中,通过将 Report 类设计为一个接口,我们确保了 Report 类型的方法清晰而专注。 ReportGenerator 类依赖于 ReportStorage 接口,而不是具体的实现类,这样我们就可以在不影响 ReportGenerator 的情况下更换存储实现。此外, ReportPrinter 的设计允许它灵活处理不同类型的报告,同时也保证了对于新类型的报告能够容易地扩展。
通过遵循这些原则,我们能够开发出更加健壮、可维护和可扩展的系统。在实际开发中,应用这些原则需要根据具体情况灵活运用,不能生搬硬套。
3. Java集合框架的使用与源码解读
3.1 集合框架概述
集合框架是Java编程中不可或缺的一部分,它提供了一套性能优化、设计优雅且易于使用的数据结构。Java集合框架支持不同类型的集合操作,按照不同的数据类型分为List、Set和Map三大接口。
3.1.1 List、Set、Map接口及其实现类特性
List接口支持有序、可重复的元素集合。ArrayList是基于动态数组实现的,适用于随机访问,但不适合插入和删除操作。LinkedList基于链表实现,提供了高效的插入和删除操作,但随机访问性能较差。通过以下示例代码,展示如何创建和初始化一个ArrayList和LinkedList实例:
import java.util.*;
public class ListExample {
public static void main(String[] args) {
// 创建ArrayList实例
List<String> arrayList = new ArrayList<>();
arrayList.add("Apple");
arrayList.add("Banana");
// 创建LinkedList实例
List<String> linkedList = new LinkedList<>();
linkedList.add("Orange");
linkedList.add("Mango");
// 打印元素
System.out.println("ArrayList: " + arrayList);
System.out.println("LinkedList: " + linkedList);
}
}
Set接口保证元素唯一性,不允许重复。HashSet是基于HashMap实现的,提供了快速的查找能力。TreeSet基于红黑树实现,可以保证元素自动排序。下面的示例展示了如何使用HashSet和TreeSet:
import java.util.*;
public class SetExample {
public static void main(String[] args) {
// 创建HashSet实例
Set<String> hashSet = new HashSet<>();
hashSet.add("Dog");
hashSet.add("Cat");
// 创建TreeSet实例
Set<String> treeSet = new TreeSet<>();
treeSet.add("Horse");
treeSet.add("Sheep");
// 打印元素
System.out.println("HashSet: " + hashSet);
System.out.println("TreeSet: " + treeSet);
}
}
Map接口是一种键值对集合,允许将唯一键映射到特定的值。HashMap和TreeMap是两个最常用的实现类。HashMap基于散列实现,提供了高效的随机访问。TreeMap基于红黑树实现,能够保证键的自然排序或指定排序。下面是创建和使用HashMap和TreeMap的示例代码:
import java.util.*;
public class MapExample {
public static void main(String[] args) {
// 创建HashMap实例
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("January", 1);
hashMap.put("February", 2);
// 创建TreeMap实例
Map<String, Integer> treeMap = new TreeMap<>();
treeMap.put("March", 3);
treeMap.put("April", 4);
// 打印键值对
System.out.println("HashMap: " + hashMap);
System.out.println("TreeMap: " + treeMap);
}
}
3.1.2 集合框架在JDK中的迭代与演变
Java集合框架自JDK 1.2以来已经历了多次迭代和增强。JDK 5引入了泛型,极大地提升了代码的类型安全性和可读性。JDK 8则引入了Stream API,使得集合数据处理更加简洁和函数式。此外,Java 9引入了 java.util.List.of 和 java.util.Set.of 等工厂方法,为创建不可变集合提供了一种便捷的方式。了解这些迭代与演变,有助于我们更好地掌握集合框架的使用。
3.2 集合类的底层原理
3.2.1 ArrayList与LinkedList的内部结构与性能比较
ArrayList和LinkedList是Java中实现List接口的两个常用类。它们在内部结构和性能特点上有着显著的不同。
ArrayList的内部结构与性能
ArrayList内部使用Object数组存储元素。当数组容量不足以容纳更多元素时,ArrayList会自动扩容,通常新容量是原容量的1.5倍。这种设计使得ArrayList在内存使用上较为高效,但也带来了扩容时的性能开销。
由于ArrayList使用数组存储元素,其查找操作的时间复杂度为O(1),而插入和删除操作通常需要移动元素,时间复杂度为O(n),其中n是列表中元素的数量。因此,ArrayList在执行随机访问操作时性能优越,但在插入和删除操作方面表现一般。
以下是ArrayList在插入和删除操作中的性能分析代码块:
import java.util.ArrayList;
public class ArrayListPerformance {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
// 测试插入性能
long startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.add(0, i);
}
long endTime = System.nanoTime();
System.out.println("ArrayList 插入操作耗时:" + (endTime - startTime) + " 纳秒");
// 测试删除性能
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.remove(i);
}
endTime = System.nanoTime();
System.out.println("ArrayList 删除操作耗时:" + (endTime - startTime) + " 纳秒");
}
}
LinkedList的内部结构与性能
LinkedList内部是基于双向链表实现的,每个节点包含三个部分:数据项、指向前一个节点的引用以及指向后一个节点的引用。这种结构使得LinkedList在插入和删除元素时不需要移动元素,只需要调整节点间的引用,因此在这些操作上性能较好。
然而,LinkedList的随机访问性能较差,因为它需要从头部或尾部开始遍历链表直到找到所需的元素。因此,LinkedList的时间复杂度为O(n),其中n是列表中元素的数量。
以下是LinkedList在插入和删除操作中的性能分析代码块:
import java.util.LinkedList;
public class LinkedListPerformance {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
// 测试插入性能
long startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.add(0, i);
}
long endTime = System.nanoTime();
System.out.println("LinkedList 插入操作耗时:" + (endTime - startTime) + " 纳秒");
// 测试删除性能
startTime = System.nanoTime();
for (int i = 0; i < 100000; i++) {
list.remove(i);
}
endTime = System.nanoTime();
System.out.println("LinkedList 删除操作耗时:" + (endTime - startTime) + " 纳秒");
}
}
3.2.2 HashMap与TreeMap的工作机制与效率分析
HashMap和TreeMap是实现Map接口的两个重要类,它们在数据存储和检索上有不同的工作机制和效率表现。
HashMap的工作机制与效率
HashMap是基于哈希表的Map接口实现。它存储键值对时,通过键的哈希码进行计算得到存储位置,以此实现高效的插入、删除和查找操作。当两个不同的键计算出相同的哈希码时,这些键值对将存储在同一个位置,形成一个链表,这种现象称为“哈希冲突”。Java 8对HashMap进行了优化,当链表长度达到一定阈值时,会将链表转换为红黑树,以减少搜索时间。
HashMap在大多数情况下提供了常数时间的性能(O(1)),但在极端情况下,性能可能退化到O(n)。这是由于哈希冲突导致链表过长,或者在转换为红黑树时进行大量的重组操作。
import java.util.HashMap;
public class HashMapPerformance {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
// 测试插入性能
long startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
map.put("key" + i, i);
}
long endTime = System.nanoTime();
System.out.println("HashMap 插入操作耗时:" + (endTime - startTime) + " 纳秒");
// 测试检索性能
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
map.get("key" + i);
}
endTime = System.nanoTime();
System.out.println("HashMap 检索操作耗时:" + (endTime - startTime) + " 纳秒");
}
}
TreeMap的工作机制与效率
TreeMap基于红黑树实现,它通过比较键的自然顺序或自定义的Comparator来维护键的顺序。在TreeMap中,插入、删除和查找操作的时间复杂度为O(log n),其中n是树中节点的数量。由于TreeMap维持了键的有序状态,它适合需要按键排序的场景。
import java.util.TreeMap;
public class TreeMapPerformance {
public static void main(String[] args) {
TreeMap<String, Integer> map = new TreeMap<>();
// 测试插入性能
long startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
map.put("key" + i, i);
}
long endTime = System.nanoTime();
System.out.println("TreeMap 插入操作耗时:" + (endTime - startTime) + " 纳秒");
// 测试检索性能
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
map.get("key" + i);
}
endTime = System.nanoTime();
System.out.println("TreeMap 检索操作耗时:" + (endTime - startTime) + " 纳秒");
}
}
在实际应用中,选择ArrayList还是LinkedList、HashMap还是TreeMap,应根据具体需求和操作特点来决定,以便获得最佳性能。
4. 多线程编程与并发工具应用
4.1 Java多线程基础
4.1.1 线程的创建、启动与管理
在Java中,线程的创建和管理是一项基础而重要的能力。要创建一个线程,通常有两种方式:继承Thread类或者实现Runnable接口。创建线程后,通过调用start()方法启动它,该方法会调用线程的run()方法,其中包含要执行的代码。
class MyThread extends Thread {
public void run() {
System.out.println("This is a thread");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start(); // 启动线程
}
}
在此代码段中,MyThread类继承了Thread类,并重写了run()方法。在main方法中创建了MyThread的实例,并调用start()方法来启动线程。需要注意的是,直接调用run()方法并不会创建新线程,它只是在当前线程中运行run()方法的内容。
线程的管理包括线程的优先级调整、状态监控(例如是否存活、是否正在执行)、以及线程的中断。Java中的线程是抢占式的,也就是说高优先级的线程比低优先级的线程有更大的机会执行。
Thread thread = new Thread(new Runnable() {
public void run() {
// ...
}
});
thread.setPriority(Thread.MAX_PRIORITY); // 设置为最高优先级
thread.isAlive(); // 检查线程是否存活
thread.interrupt(); // 中断线程
4.1.2 同步机制与线程安全的实现
在多线程环境中,多个线程可能会同时访问和修改共享资源,这可能导致竞态条件和不一致的数据状态。为了避免这种情况,Java提供了同步机制,包括synchronized关键字和锁(Lock)机制。
synchronized关键字可以用来控制对方法或代码块的访问,确保一次只有一个线程可以执行同步代码块,保证了线程安全。
class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
在这个例子中,increment()方法和getCount()方法都被同步了,所以当一个线程执行increment()方法时,其他线程不能同时执行这两个同步方法。
Lock接口提供了一种更灵活的方式来实现同步,与synchronized相比,Lock提供了更多的功能,比如尝试获取锁(tryLock())和响应中断(lockInterruptibly())。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class CounterWithLock {
private final Lock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
这里,我们使用了ReentrantLock来保证对count变量的同步访问,lock()和unlock()方法分别用来获取和释放锁。务必确保unlock()方法总是在finally块中被调用,以避免造成死锁。
4.2 并发工具类的高级用法
4.2.1 锁机制与并发集合详解
除了synchronized和Lock,Java还提供了高级并发工具类来帮助开发者实现复杂并发操作。例如,Semaphore(信号量)、CyclicBarrier(回环栅栏)、CountDownLatch(倒计时门闩)和Phaser(阶段器)等。
以CountDownLatch为例,它是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,允许一个或多个线程一直等待。
import java.util.concurrent.CountDownLatch;
public class CountDownLatchExample {
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(3);
new Thread(new Worker(latch)).start();
new Thread(new Worker(latch)).start();
new Thread(new Worker(latch)).start();
try {
latch.await(); // 等待直到倒计时结束
System.out.println("所有子线程已执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class Worker implements Runnable {
private final CountDownLatch latch;
public Worker(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " 正在执行");
Thread.sleep(1000); // 假设操作需要一些时间
latch.countDown(); // 计数减一
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
在上述代码中,我们创建了一个CountDownLatch实例,计数设置为3,表示有三个子线程需要完成操作。每个子线程在执行完自己的任务后调用countDown()方法,当计数达到0时,主线程中的await()方法会放行,继续执行后续代码。
4.2.2 Fork/Join框架与原子操作类的使用实例
Fork/Join框架是Java 7引入的一种用于并行执行任务的框架,特别适合用于可以将大任务分割成小任务的并行计算。Fork/Join利用了工作窃取算法,即如果一个工作线程完成了自己的任务,它可以窃取其它未完成的工作线程的任务来执行,减少空闲时间,提高效率。
以下是Fork/Join框架的一个简单示例:
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.ForkJoinPool;
class FibonacciTask extends RecursiveTask<Integer> {
private final int n;
FibonacciTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
FibonacciTask f1 = new FibonacciTask(n - 1);
f1.fork(); // 分割任务
FibonacciTask f2 = new FibonacciTask(n - 2);
return f2.compute() + f1.join(); // 合并结果
}
}
public class ForkJoinExample {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
int result = pool.invoke(new FibonacciTask(10));
System.out.println("Fibonacci number is " + result);
}
}
在这个例子中,我们使用ForkJoinPool来执行一个计算斐波那契数列的任务。我们创建了一个RecursiveTask子类,将计算分解为更小的任务,并使用compute()方法来组合这些任务的结果。
原子操作类如AtomicInteger、AtomicLong、AtomicBoolean等,提供了一种方法,可以进行无锁的操作,以保证操作的原子性。原子操作是多线程环境下非常有用的工具,它们通过底层硬件的原子指令,实现了线程安全的操作。
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerExample {
private AtomicInteger count = new AtomicInteger();
public void increment() {
count.incrementAndGet(); // 等价于 count++
}
public int getCount() {
return count.get();
}
}
在这个例子中,AtomicInteger类用于安全地进行数值的增加操作。使用incrementAndGet()方法可以实现对count变量的原子性增加操作,无需使用synchronized关键字。
以上我们通过实例代码和详细解释,深入探讨了Java多线程编程中的核心概念和并发工具的高级用法。理解并能够灵活运用这些知识点,对于开发高并发应用至关重要。
5. Java异常处理机制与IO流操作
5.1 异常处理机制详解
异常处理是Java编程中确保程序健壮性的重要组成部分。本节将深入探讨Java的异常处理机制,包括异常类的层次结构、异常的捕获与处理,以及如何创建和使用自定义异常。
5.1.1 异常类层次结构与捕获处理
Java异常处理是通过try、catch、finally和throw、throws关键字来实现的。异常类在Java中是一个层次结构,所有的异常类都继承自Throwable类,其下分为Error和Exception两大类。Error类表示严重错误,程序无法处理,而Exception类则分为受检异常(checked exceptions)和非受检异常(unchecked exceptions),其中受检异常是编译器要求必须捕获或声明抛出的异常。
异常处理的基本流程可以通过以下代码块和逻辑分析来展示:
try {
// 尝试执行的代码块
} catch (ExceptionType1 e1) {
// 异常类型1的处理逻辑
} catch (ExceptionType2 e2) {
// 异常类型2的处理逻辑
} finally {
// 无论是否捕获到异常,都会执行的代码块
}
在此结构中, try 代码块中放置可能会发生异常的代码。 catch 块用于捕获并处理特定类型的异常。如果try块中的代码抛出 ExceptionType1 类型的异常,那么第一个 catch 块将执行其处理逻辑,如果没有任何 catch 块匹配,则异常将被抛向调用者。 finally 块包含的代码无论是否捕获到异常都会执行,常用于清理资源如关闭文件流。
5.1.2 自定义异常与异常链的应用
在实际开发中,可能会遇到标准异常类无法准确描述的情形,此时可创建自定义异常。自定义异常是扩展了Exception类或其子类的新类。它们通常用于明确特定的错误类型或业务逻辑错误。
通过异常链,可以将低层的异常信息嵌入到高层异常中,从而提供更丰富的错误处理上下文。使用 Throwable 类的 initCause() 方法或构造函数中的 cause 参数可以实现异常链。
class CustomException extends Exception {
public CustomException(String message) {
super(message);
}
public CustomException(String message, Throwable cause) {
super(message, cause);
}
}
通过扩展Exception类来定义自定义异常,构造函数可以接受错误信息或底层异常作为原因。
5.2 IO流的操作与NIO的进阶
5.2.1 字节流与字符流的应用场景
Java的IO流分为字节流和字符流,分别对应于字节输入/输出流(InputStream和OutputStream)和字符输入/输出流(Reader和Writer)。
字节流主要用于处理二进制数据,如文件、网络数据传输等。字节流的处理不需要考虑字符编码,直接按照字节进行读写,适用于所有类型的数据。
字符流主要用于处理文本数据,它在字节流基础上增加了编码转换的功能。字符流通过BufferedReader、BufferedWriter等包装类对数据进行缓存处理,提高了读写效率,并处理字符编码,使其更适合处理文本文件。
// 字节流读写文件示例
try (FileInputStream fis = new FileInputStream("example.bin");
FileOutputStream fos = new FileOutputStream("copy_example.bin")) {
int len;
while ((len = fis.read()) != -1) {
fos.write(len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 字符流读写文件示例
try (FileReader fr = new FileReader("example.txt");
FileWriter fw = new FileWriter("copy_example.txt")) {
int c;
while ((c = fr.read()) != -1) {
fw.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}
在字节流示例中,我们使用 read() 和 write(int b) 方法来读写单个字节。在字符流示例中,我们使用 read() 和 write(int c) 方法来读写单个字符。
5.2.2 NIO的核心组件与性能优势分析
NIO(New I/O)是Java提供的新的输入/输出API,它不同于传统的IO,提供了基于缓冲区、选择器以及通道的IO操作方式。NIO支持面向缓冲区的(Buffer-oriented)、基于通道的(Channel-based)I/O操作,使得NIO可以支持非阻塞式(non-blocking)的IO操作。
NIO中的核心组件包括:
- Buffer :缓冲区,是数据在内存中的临时存储区。
- Channel :通道,类似于传统IO中的流,但通道支持双向的数据传输。
- Selector :选择器,允许单个线程管理多个Channel。
graph LR
A[客户端] -->|连接| B[Selector]
B -->|选择| C[Channel 1]
B -->|选择| D[Channel 2]
C -->|数据交互| E[服务器]
D -->|数据交互| E
使用NIO时,可以构建高性能的网络服务端,支持大量并发连接。NIO的设计思想是通过使用较少的线程来处理大量的连接,相比传统的IO(BIO),NIO大大减少了线程资源的消耗,提高了系统的吞吐量。
NIO的性能优势体现在:
- 非阻塞操作:NIO可以在Channel未准备好数据时,不用阻塞等待,可以继续执行其他任务。
- 选择器(Selector):允许一个单独的线程来监视多个输入通道,减少了线程切换开销。
- 缓冲区(Buffer):能够高效地在内存中读写数据,减少了数据拷贝次数。
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(port));
serverSocketChannel.configureBlocking(false);
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int readyChannels = selector.select();
if (readyChannels == 0) continue;
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
}
if (key.isReadable()) {
// 处理读取逻辑
}
keyIterator.remove();
}
}
通过上述代码片段,我们可以看到NIO是如何通过非阻塞的方式和选择器来监听和处理多个连接的。
小结
本章深入探索了Java异常处理机制,从基本的异常类层次结构到自定义异常的创建和异常链的使用。此外,通过对比传统的IO和NIO的使用场景和性能优势,给出了实际的代码应用和逻辑分析,使读者能够清晰地了解和掌握Java中复杂的I/O操作。通过本章的学习,开发者能够更加得心应手地在实际项目中应用异常处理和IO流操作,编写出更为健壮和高效的Java代码。
6. 网络编程基础与数据库操作
6.1 Java网络编程入门
Java网络编程为开发者提供了丰富的API来实现各种网络通信需求。从基础的Socket通信到复杂的协议实现,Java都提供了强大的支持。
6.1.1 基于Socket的网络通信实现
Socket编程是网络编程中最基本的技能之一。在Java中,我们可以利用Socket类和ServerSocket类来实现客户端和服务器端的通信。
以下是基于Socket通信的一个简单示例:
import java.io.*;
import java.net.*;
public class SimpleSocketClient {
public static void main(String[] args) {
Socket socket = null;
DataOutputStream dos = null;
DataInputStream dis = null;
try {
socket = new Socket("localhost", 12345); // 连接到服务器
dos = new DataOutputStream(socket.getOutputStream());
dos.writeUTF("Hello, Server!");
dis = new DataInputStream(socket.getInputStream());
String response = dis.readUTF();
System.out.println("Server said: " + response);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (dos != null) dos.close();
if (dis != null) dis.close();
if (socket != null) socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
import java.io.*;
import java.net.*;
public class SimpleSocketServer {
public static void main(String[] args) {
ServerSocket serverSocket = null;
Socket clientSocket = null;
DataOutputStream dos = null;
DataInputStream dis = null;
try {
serverSocket = new ServerSocket(12345); // 监听12345端口
System.out.println("Waiting for a connection...");
clientSocket = serverSocket.accept(); // 接受连接
dos = new DataOutputStream(clientSocket.getOutputStream());
dis = new DataInputStream(clientSocket.getInputStream());
String clientMessage = dis.readUTF();
System.out.println("Client said: " + clientMessage);
dos.writeUTF("Hello, Client!");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (dos != null) dos.close();
if (dis != null) dis.close();
if (clientSocket != null) clientSocket.close();
if (serverSocket != null) serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
在这个例子中,客户端发送了一个字符串消息给服务器,服务器接收到这个消息后,回应了客户端。
6.1.2 高级网络编程技巧与案例分析
随着网络编程的深入,我们会遇到更多复杂的需求,比如非阻塞IO、异步IO、以及协议的设计等。
非阻塞IO
Java NIO提供了一套不同于传统Java IO的API,它支持面向缓冲区的、基于通道的IO操作。NIO能够非阻塞地读写数据,这在处理大量并发连接时非常有用。
以下是使用NIO进行非阻塞通信的简单例子:
import java.net.*;
import java.nio.*;
import java.nio.channels.*;
public class NonBlockingSocketServer {
public static void main(String[] args) {
AsynchronousServerSocketChannel serverChannel = null;
AsynchronousSocketChannel clientChannel = null;
ByteBuffer buffer = ByteBuffer.allocate(1024);
try {
serverChannel = AsynchronousServerSocketChannel.open();
serverChannel.bind(new InetSocketAddress(12345));
System.out.println("Waiting for incoming connection...");
serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
public void completed(AsynchronousSocketChannel result, Object attachment) {
serverChannel.accept(null, this); // 接受下一个连接
clientChannel = result;
buffer.clear();
clientChannel.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
public void completed(Integer result, ByteBuffer attachment) {
buffer.flip();
System.out.println("Client said: " + new String(buffer.array()));
buffer.clear();
clientChannel.write(ByteBuffer.wrap("Hello Client!".getBytes()));
}
public void failed(Throwable exc, ByteBuffer attachment) {
// 处理读写失败情况
}
});
}
public void failed(Throwable exc, Object attachment) {
// 处理接受失败情况
}
});
Thread.sleep(Integer.MAX_VALUE); // 让服务器持续运行
} catch (IOException | InterruptedException e) {
e.printStackTrace();
} finally {
try {
if (clientChannel != null) clientChannel.close();
if (serverChannel != null) serverChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
协议设计
网络编程不仅仅是发送和接收数据,还需要设计和实现网络协议,这些协议定义了数据传输的方式和格式。协议设计时需要考虑数据的序列化和反序列化、包的分隔和重组、校验和等。
总结
网络编程是Java开发中的一个重要组成部分。从基本的Socket编程到高级的NIO,每个开发者都应该掌握网络编程的基础知识。高级技巧和协议设计更是提升网络编程能力的关键。通过实践,开发者能够更好地理解网络编程的细节和深层次的应用场景。
6.2 JDBC的应用与优化
JDBC (Java Database Connectivity) 是Java用于连接和执行查询数据库的标准接口。通过JDBC,Java程序可以访问各类关系型数据库。
6.2.1 JDBC的基本使用与事务控制
JDBC为数据库连接、查询、更新等操作提供了统一的API。
基本使用
以下是一个使用JDBC进行数据库操作的基本示例:
import java.sql.*;
public class SimpleJDBCExample {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 加载数据库驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 连接到数据库
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/testdb", "username", "password");
stmt = conn.createStatement();
String sql = "SELECT * FROM users";
rs = stmt.executeQuery(sql);
while (rs.next()) {
// 处理结果集
System.out.println("ID: " + rs.getInt("id"));
System.out.println("Name: " + rs.getString("name"));
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
try {
if (rs != null) rs.close();
if (stmt != null) stmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
在该示例中,我们使用 Statement 对象执行了一个查询操作,并通过 ResultSet 对象遍历查询结果。
事务控制
事务控制是数据库操作中的一个重要方面,它保证了一系列操作要么全部执行,要么全部不执行。
try {
conn.setAutoCommit(false); // 关闭自动提交,开始事务
// 执行数据库操作
stmt.executeUpdate("INSERT INTO users(name) VALUES ('John')");
// 可能的业务逻辑处理
// ...
conn.commit(); // 提交事务
} catch (SQLException e) {
conn.rollback(); // 回滚事务
} finally {
// 关闭资源
}
在这个例子中,我们通过关闭自动提交,手动控制事务的提交和回滚。
6.2.2 连接池与ORM框架的集成实践
随着应用需求的增长,频繁地打开和关闭数据库连接会导致性能问题。连接池是解决此问题的常用方法。
连接池
连接池复用已经建立的数据库连接,减少连接建立和释放的开销。
一个常用的连接池示例:
import org.apache.commons.dbcp2.BasicDataSource;
public class ConnectionPoolExample {
public static void main(String[] args) throws SQLException {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/testdb");
dataSource.setUsername("username");
dataSource.setPassword("password");
Connection conn = null;
try {
conn = dataSource.getConnection();
// 进行数据库操作
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
}
}
ORM框架
对象关系映射(ORM)框架如Hibernate或MyBatis,提供了对象到数据库表的映射机制,简化了数据库操作。
一个简单的Hibernate使用例子:
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateExample {
public static void main(String[] args) {
SessionFactory sessionFactory = new Configuration()
.configure("hibernate.cfg.xml")
.buildSessionFactory();
Session session = sessionFactory.getCurrentSession();
try {
session.beginTransaction();
// 保存、检索或更新对象
session.save(new User("John", "Doe"));
session.getTransaction().commit();
} catch (Exception e) {
session.getTransaction().rollback();
e.printStackTrace();
} finally {
session.close();
sessionFactory.close();
}
}
}
总结
JDBC是Java开发中不可或缺的技术,它提供了一种标准的方式来访问和操作数据库。掌握连接池和ORM框架的集成,可以显著提升应用程序的性能和开发效率。通过使用这些技术,开发者可以更专注于业务逻辑的实现,而不是底层的数据库操作细节。
7. 设计模式与JVM原理及优化
7.1 常见设计模式精讲
设计模式作为软件设计领域的一套经典解决方案,不仅在Java语言中得到了广泛应用,也为整个软件行业的架构设计提供了理论支撑。本节将深入探讨创建型、结构型、行为型设计模式,并分析它们在软件架构中的作用与选择。
7.1.1 创建型、结构型、行为型设计模式案例解析
创建型设计模式关注对象的创建过程,主要有单例模式、工厂模式、建造者模式等。结构型设计模式关心类和对象的组合,如代理模式、适配器模式、装饰器模式等。行为型设计模式专注于对象间的通信,包括策略模式、模板方法模式、观察者模式等。
以单例模式为例,它确保一个类只有一个实例,并提供一个全局访问点。以下是一个简单的单例模式实现:
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
此代码确保了 Singleton 类的实例全局唯一,并且能够延迟加载,有效节省资源。
7.1.2 设计模式在软件架构中的作用与选择
设计模式为解决特定问题提供了一套通用的模板,但选择合适的模式对于架构的可维护性和扩展性至关重要。例如,工厂模式适合在对象创建逻辑复杂或需要高度解耦时使用。
在实际应用中,应根据需求的特定场景和约束选择合适的设计模式。例如,如果你需要一个高度灵活的解决方案,策略模式可能比简单的if-else条件分支更加合适。在选择设计模式时,应先充分理解业务需求和现有系统架构,并考虑模式带来的额外复杂度。
7.2 JVM工作原理与性能调优
JVM(Java虚拟机)是Java程序运行的基础,理解其工作原理对于编写高性能的Java代码至关重要。性能调优不仅有助于提升应用性能,还能解决内存溢出、垃圾回收(GC)等问题。
7.2.1 JVM内存模型与垃圾回收机制
JVM内存模型定义了JVM在执行Java程序过程中如何管理内存,包括堆(Heap)、方法区(Method Area)、虚拟机栈(VM Stack)、本地方法栈(Native Stack)和程序计数器(Program Counter)。
垃圾回收机制是JVM的一个重要组成部分,它负责回收那些不再被引用的对象所占用的内存空间。常见的垃圾回收算法包括标记-清除(Mark-Sweep)、复制(Copying)、标记-整理(Mark-Compact)等。
7.2.2 性能监控工具的使用与调优案例
JVM性能调优是一个系统工程,通常需要使用一系列的监控和诊断工具来进行分析和调整。常用的工具有JConsole、VisualVM、JProfiler等。
调优案例: 假设我们的Java应用频繁触发Full GC,影响了性能。首先,我们可以使用 jstat 命令来监控GC情况:
jstat -gc <pid> <interval>
其中 <pid> 是Java进程的ID, <interval> 是采样间隔时间(毫秒)。
通过监控,我们发现老年代内存增长过快。针对这种情况,我们可以调整JVM参数来优化性能,比如增加老年代大小:
-Xms256m -Xmx1024m -XX:MaxPermSize=256m
同时,我们还可以考虑使用更高效的垃圾回收器,如G1或者ZGC。
通过上述步骤,我们可以对JVM进行深入分析和调优,进而提升应用性能和稳定性。
简介:Java作为广泛使用的编程语言,其面试题目包含多个核心领域,从基础语法到JVM优化,涵盖了基础知识、面向对象、集合框架、多线程、异常处理、IO流、网络编程、数据库操作、设计模式等。应聘广州Java开发岗位者需深入理解这些知识点,以展现自己的理论知识和实际操作能力。同时,熟悉Java最新版本的特性将有助于在面试中脱颖而出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









