



从表中查询数据时,可能会得到重复的行。为了删除这些重复的行,DISTINCT 语句可以帮助我们实现。
DISTINCT子句的语法:
SELECT DISTINCT select_list
FROM table_name;
示例:DISTINCT 子句从employees表中选择雇员的唯一姓氏。

首先,SELECT语句从表中查询雇员的姓氏:
SELECT lastname FROM employees
ORDER BY lastname;
运行结果:
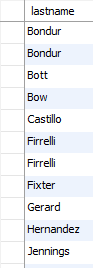
从输出中可以清楚地看到,一些员工的姓氏相同,例如 Bondur,Firrelli。
DISTINCT子句从employees表中选择的唯一姓氏:
SELECT DISTINCT lastname
FROM employees ORDER BY lastname;
运行结果
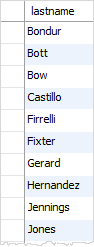
在此可以看到重复数据被过滤掉了
DISTINCT多列
可以在DISTINCT 多于一个的列中使用该子句。在这种情况下,MySQL使用这些列中值的组合来确定结果集中行的唯一性。

从customers表中获得城市和州的唯一组合,请使用以下查询:
SELECT DISTINCT state, city
FROM customers
WHERE state IS NOT NULL ORDER BY state, city;
运行结果如下:
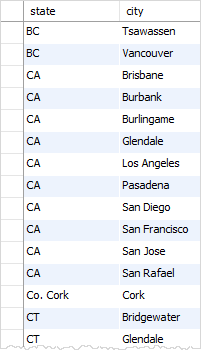
没有该DISTINCT 子句,将获得州和城市的重复组合,如下所示:
SELECT state, city FROM customers
WHERE state IS NOT NULL ORDER BY state , city;
运行结果:
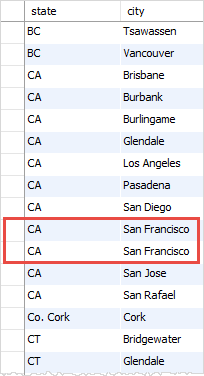
DISTINCT和聚合函数
可以将DISTINCT子句与聚合函数(例如SUM,AVG和COUNT)一起使用,以在将聚合函数应用于结果集之前删除重复的行。
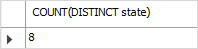
例如,要计算美国客户的唯一状态,请使用以下查询:
SELECT COUNT(DISTINCT state) FROM customers
WHERE country = 'USA';
运行结果如下:


















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









