



 本文介绍了如何使用sort命令对文本文件进行各种排序操作,包括按列排序、按数值排序等,并结合uniq命令去除重复行,适用于数据处理与分析场景。
本文介绍了如何使用sort命令对文本文件进行各种排序操作,包括按列排序、按数值排序等,并结合uniq命令去除重复行,适用于数据处理与分析场景。
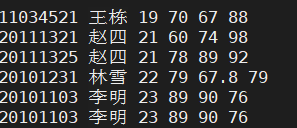
准备文本:test.txt
按列分别是学号 姓名 年龄 语文 数学 英语成绩
一、sort
1. sort默认:以行为单位对文件进行排序,按ASCII码值进行比较升序输出。
cat test.txt
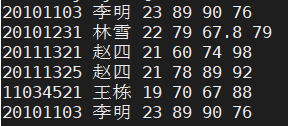
sort test.txt
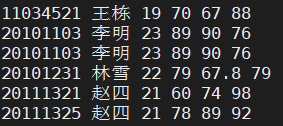
2. sort -u test.txt 对test.txt按默认规则进行排序后去除重复行
可以看出重复行“李明”对应的这一行被删除了。
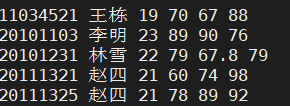
3. sort -r test.txt 对test.txt按默认规则进行降序排序
 可以看到将学号按照ASCII码降序排列了
可以看到将学号按照ASCII码降序排列了
4. sort -r test.txt -o test.txt
将排序结果直接用重定向的方式(>src.file)输出到原文件时原文件会被清空,因此为了将排序后的文件输出到原来文件中存储,使用-o选项即可。

5. sort -n num.txt 以数值的方式对文件进行排序
more num.txt
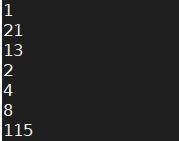
sort num.txt
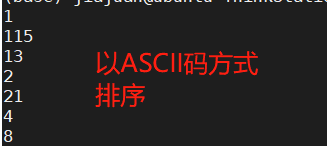
sort -n num.txt

6. sort -t -k 用-t设置分隔符,-k指定列数
sort -n -k 3 -t ' ' test.txt
对test.txt以空格为分隔符,将第三列(年龄)按数值升序排序
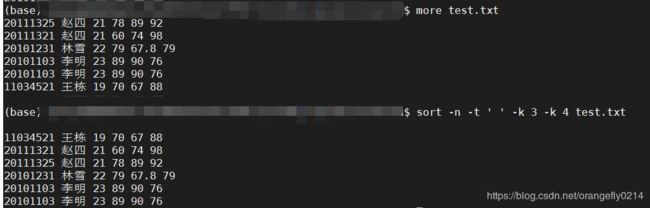
7.
sort -n -t ' ' -k 3 -k 4 test.txt
对test.txt安装第三列年龄升序排列,年龄相同时,按照第四列语文成绩升序排列
8.
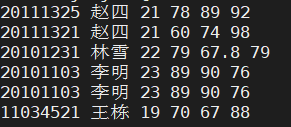
sort -n -t ' ' -k 6r -k 4 test.txt
将test.txt按照第6列英语成绩降序排列,英语成绩相同时,按照第四列语文成绩升序排列。结果如下: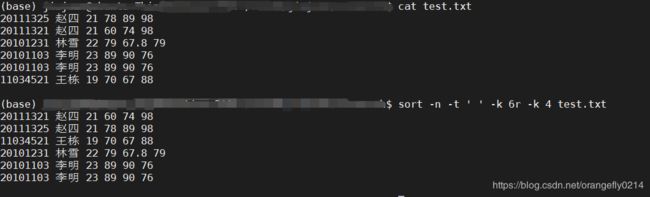
9.
sort -t ' ' -k 1.2 test.txt
对test.txt的第一列的第二个字符按照默认规则进行排序
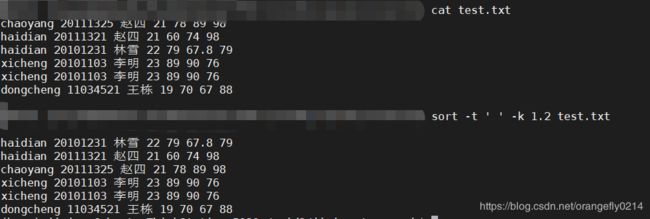
可以看到第一列的字段均按照第二个字符做了升序排序。
10.
sort -t ' ' -k 1.2,1.2 -k 7,7nr test.txt
对test.txt的第一个字段的第二个字符按默认规则排序,若该字符相同,则对第7列按照数值进行降序排列。
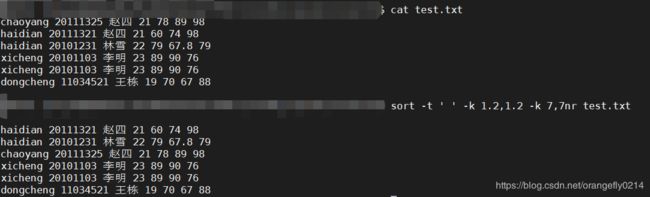
11. sort -n -k -u联合使用
sort -n -k 4 -k 7 -u test.txt
对test.txt的先按第4列升序排列,再按第7列升序排列,最后再对结果进行去重。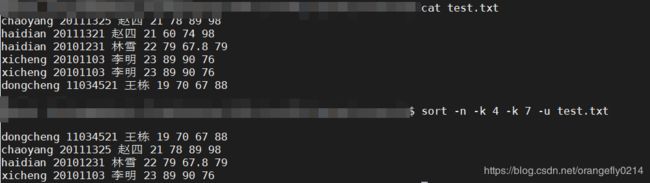
二、uniq 输出或忽略文本中的重复行
1. uniq test.txt 去除test.txt中连续的重复行
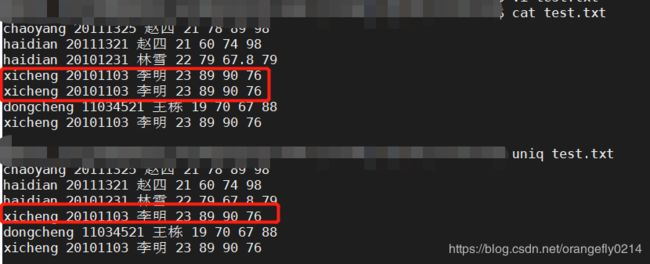
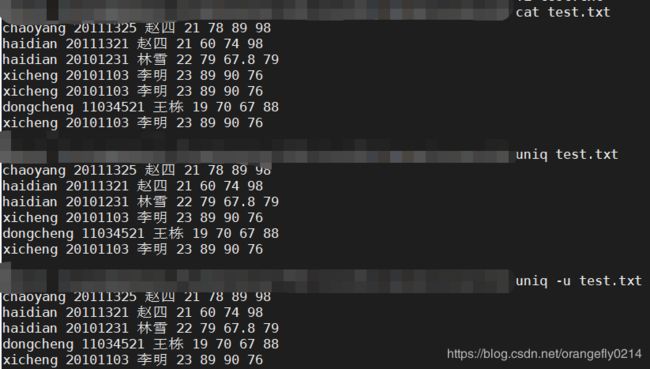
2. uniq -u test.txt 去除test.txt的重复,保留唯一的行
3. uniq -c test.txt 去除test.txt中连续的重复行并记录出现的次数

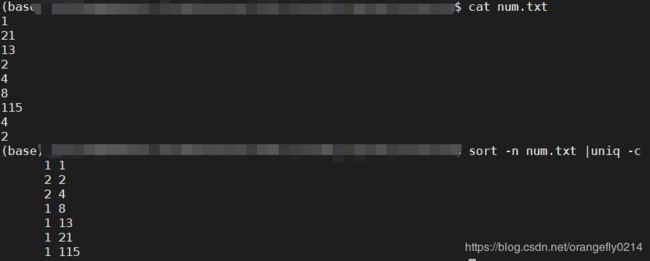
4. sort -n num.txt |uniq -c
对num.txt按数值进行排序,去重后统计各个数出现的次数
5. uniq -d num.txt 只显示num.txt中连续的重复行
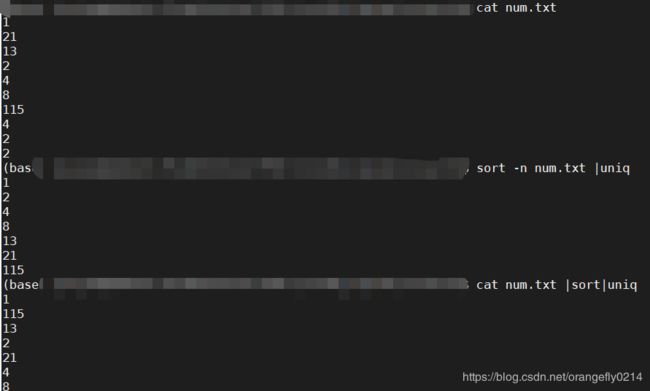
6. 先sort再uniq可以去除所有重复项

















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









