




 本文介绍了如何使用Pandas库在Python中进行数据选择、聚合和统计分析,通过银行客户流失数据集展示了数据帧的操作,如列选择、过滤以及计算统计信息和相关性。
本文介绍了如何使用Pandas库在Python中进行数据选择、聚合和统计分析,通过银行客户流失数据集展示了数据帧的操作,如列选择、过滤以及计算统计信息和相关性。

Pandas是一个python库,用于处理数据、生成统计数据、聚合数据等等。在这篇文章中,我们将讨论如何使用Pandas库进行数据选择、聚合和统计分析。
我们开始吧!
我们将使用银行客户流失建模数据集。数据可以在这里找到。
https://www.kaggle.com/sanjanavoona1043/bank-churn
首先,我们导入Pandas库,打印前五行数据:
import pandas as pddf = pd.read_csv("Bank_churn_modelling.csv")pd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)print(df.head())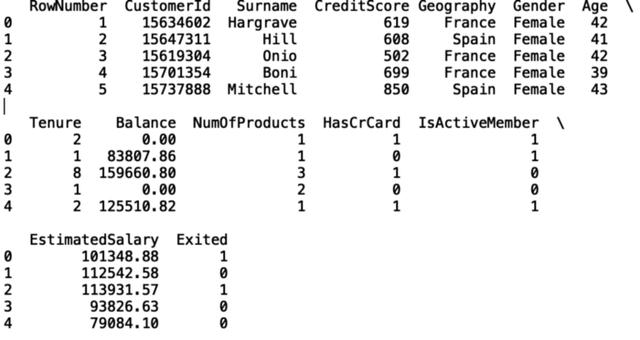
数据选择
这里我们将考虑使用Pandas数据帧进行数据选择。我们可以使用“[]”来选择数据列。例如,如果要选择“CreditScore”、“Gender”、“Age”和“Exited”,可以执行以下操作:
df_select = df[['CreditScore', 'Gender', 'Age', 'Exited']]print(df_select.head())
还可以按列值过滤原始数据帧。让我们过滤原始数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









