






LitePager,一个轻量级的ViewPager,仿新版网易云歌单广场
使用方式:
添加依赖:
implementation 'com.wuyr:litepager:1.0.0'
APIs:
MethodDescription
addViews(int... layouts)批量添加子View
addViews(View... views)批量添加子View
setSelection(View target)选中指定子View
setSelection(int index)根据索引选中子View
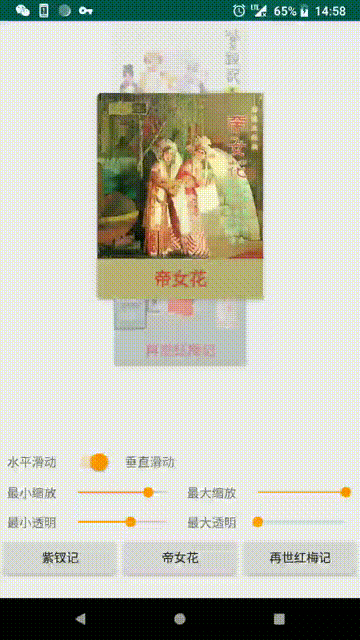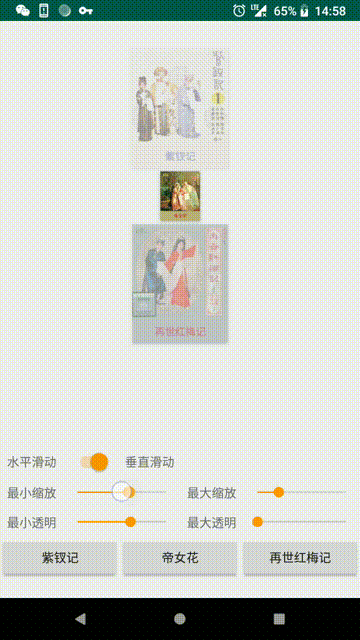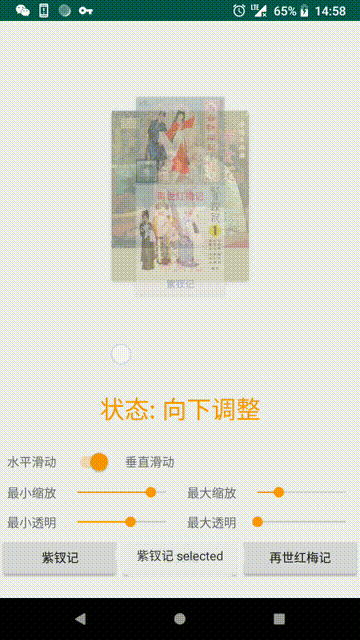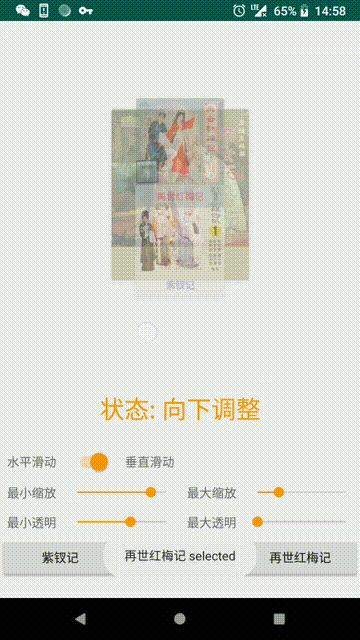
setOrientation(int orientation)设置方向(默认: ORIENTATION_HORIZONTAL):
ORIENTATION_HORIZONTAL(水平)
ORIENTATION_VERTICAL(垂直)
setFlingDuration(long duration)设置动画的时长
setMaxScale(float maxScale)设置最大缩放比例
setMinScale(float minScale)设置最小缩放比例
setMaxAlpha(float maxAlpha)设置最大不透明度
setMinAlpha(float minAlpha)设置最小不透明度
setOnScrollListener(OnScrollListener listener)设置滚动状态监听:
STATE_IDLE(静止状态)
STATE_DRAGGING_LEFT(向左拖动)
STATE_DRAGGING_RIGHT(向右拖动)
STATE_DRAGGING_TOP(向上拖动)
STATE_DRAGGING_BOTTOM(向下拖动)
STATE_SETTLING_LEFT(向左调整)
STATE_SETTLING_RIGHT(向右调整)
STATE_SETTLING_TOP(向上调整)
STATE_SETTLING_BOTTOM(向下调整)
setOnItemSelectedListener(SelectedListener listener)设置子View被选中的监听
getSelectedChild()获取当前选中的子View
Attributes:
NameFormatDescription
orientationenum (默认: horizontal)
horizontal(水平)
vertical(垂直)方向
flingDurationinteger动画时长
maxScalefloat (默认: 1)最大缩放比例
minScalefloat (默认: 0.8)最小缩放比例
maxAlphafloat (默认: 1)最大不透明度
minAlphafloat (默认: 0.4)最小不透明度
添加子View方式:
XML
android:layout_width="match_parent"
android:layout_height="wrap_content">
android:layout_width="150dp"
android:layout_height="200dp"
android:background="#F00" />
android:layout_width="150dp"
android:layout_height="200dp"
android:background="#0F0"/>
android:layout_width="150dp"
android:layout_height="200dp"
android:background="#00F"/>
或者
LitePager litePager = ...;
View child1 = ...;
View child2 = ...;
View child3 = ...;
//直接添加子View
litePager.addViews(child1, child2, child3);
//或者通过布局添加
litePager.addViews(R.layout.view_child1, R.layout.view_child2, R.layout.view_child3);
效果 (图1为网易云原效果):




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









