



 本文介绍了一个使用Python Selenium实现的百度百科爬虫程序,该程序能够根据提供的词条名称搜索并抓取百度百科页面上的信息框内容,包括词条的基本属性及其对应的值。程序还涉及了文件操作、PhantomJS无头浏览器的使用以及XPath的选择器应用。
本文介绍了一个使用Python Selenium实现的百度百科爬虫程序,该程序能够根据提供的词条名称搜索并抓取百度百科页面上的信息框内容,包括词条的基本属性及其对应的值。程序还涉及了文件操作、PhantomJS无头浏览器的使用以及XPath的选择器应用。

需求:根据文件内搜索条目,在百度百科进行搜索后,输出返回结果
步骤:1.读取词条文件,根据词条搜索百度百科;
2.获取搜索后的连接,并且读取Xpath;
3.爬取内容保存到BaiduSpider.txt。
'''
Created on 2017年12月15日
@filename: baiduInfoBox.py
@author: geng
'''
import time
import re
import os
import sys
import codecs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.PhantomJS(executable_path="phantomjs")
wait = ui.WebDriverWait(driver, 3)
global info
# 获取5A景区的infobox
def getInfoBox(name):
global info
# 创建文件
basePathDir = "Tourist_spots_5A"
if not os.path.exists(basePathDir):
os.makedirs(basePathDir)
baiduFile = os.path.join(basePathDir, "BaiduSpider.txt")
if not os.path.exists(baiduFile):
info = codecs.open(baiduFile, 'w', 'utf-8')
else:
info = codecs.open(baiduFile, 'a', 'utf-8')
# 搜索百度百科
driver.get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
#info.write(name)
time.sleep(2)
#print(driver.title, ": ", driver.current_url)
info.writelines(driver.title + ": " + driver.current_url + "\r\n")
# 查找相关信息
elem_names = driver.find_elements_by_xpath('//div[@class="basic-info cmn-clearfix"]/dl/dt')
elem_values = driver.find_elements_by_xpath('//div[@class="basic-info cmn-clearfix"]/dl/dd')
# 字典存储
elem_vn = dict(zip(elem_names, elem_values))
for key in elem_vn.keys():
# print(key.text, ': ', elem_vn[key].text)
info.writelines(key.text + ': ' + elem_vn[key].text + "\r\n")
info.writelines("\r\n")
info.close()
time.sleep(2)
if __name__ == "__main__":
source = open("TipsColumn.txt", 'r', encoding='UTF-8')
for name in source:
name = name.strip()
getInfoBox(name)
source.close()
print("Over")
词条文件截图:

运行结果部分截图:

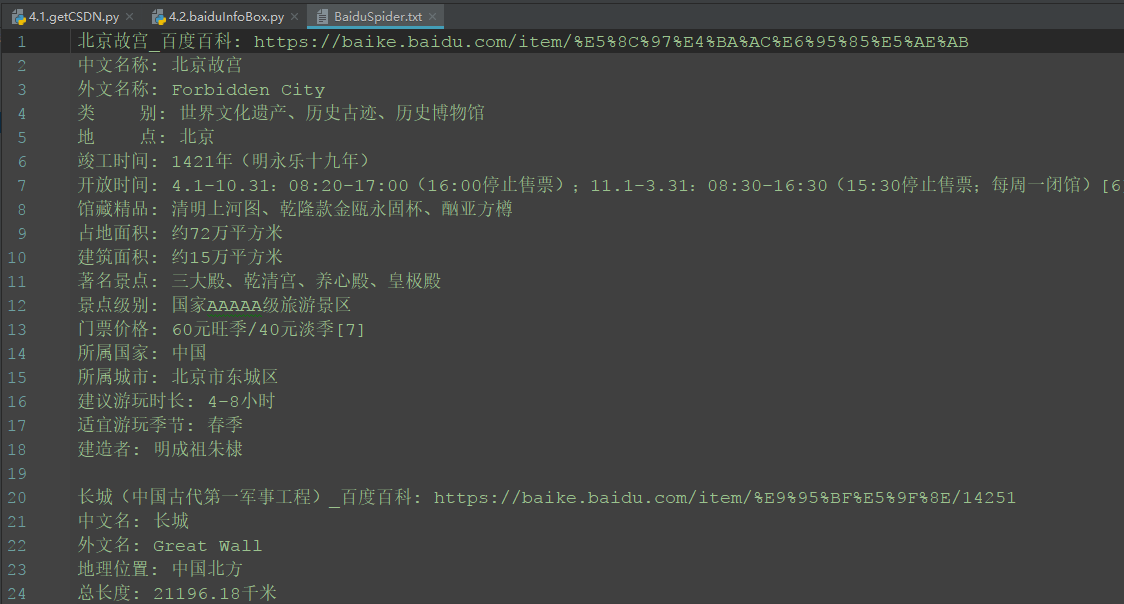
总结:
注意编码格式,个人不建议TXT文件保存数据,因为其默认编码是“GBK”,而且网上大多数解决方式都是基于python2的,我这里只不过是举个TXT编码解决方式的例子。还有就是TXT用“\r\n”表示换行,写入换行要注意区分。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









